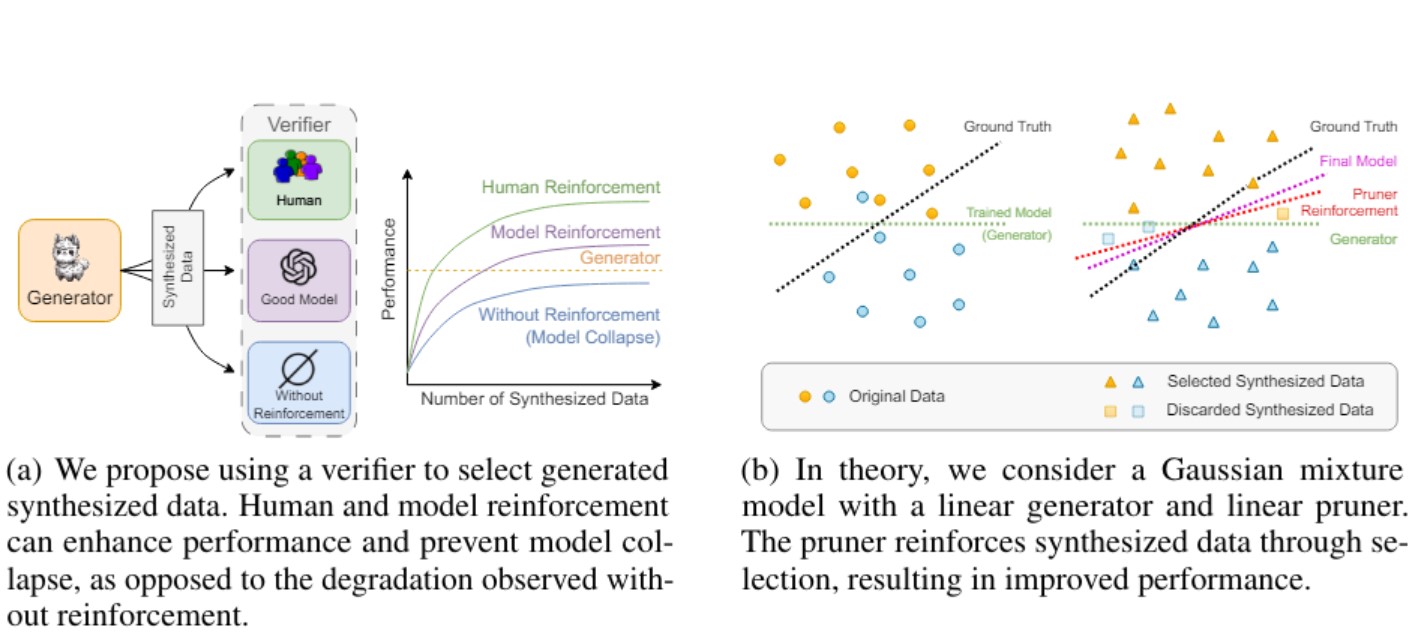
I dati sintetici sono spesso utilizzati per colmare le lacune nei dati di addestramento dell’intelligenza artificiale (AI), ma è risaputo che i modelli addestrati esclusivamente con dati sintetici possono subire un fenomeno noto come “collasso”, dove le prestazioni diminuiscono drasticamente. Recentemente, una nuova ricerca ha proposto un metodo per prevenire questo problema, suscitando grande interesse.
Mark Tech Post ha riportato che ricercatori di Meta, della New York University e dell’Università di Pechino hanno sviluppato un approccio sintetico che integra il feedback dei dati per prevenire il collasso del modello attraverso la tecnologia di rinforzo. Questo studio è stato pubblicato online.
In generale, i metodi per affrontare il collasso del modello includono l’apprendimento per rinforzo con feedback umano (RLHF), la cura dei dati e l’ingegneria dei prompt. Tra questi, RLHF è considerato il più efficace poiché implica l’uso di dati di alta qualità validati dagli esseri umani. Tuttavia, questo metodo è costoso e non scalabile poiché richiede etichettatura manuale dei dati.
Un altro approccio consiste nella selezione e filtraggio dei dati sintetici, utilizzando euristiche o regole predefinite per eliminare dati di bassa qualità o non pertinenti prima dell’addestramento. Questo metodo può mitigare l’impatto negativo dei dati sintetici di bassa qualità, ma richiede sforzi significativi e non risolve completamente il rischio di collasso del modello basato sui criteri di filtraggio.
I ricercatori hanno spiegato che hanno focalizzato l’attenzione su come è più facile distinguere tra esempi di dati di buona e cattiva qualità piuttosto che generare autonomamente dati sintetici di alta qualità. Utilizzando questo approccio, hanno applicato dati sintetici rinforzati con feedback all’addestramento del modello, simulando calcoli matriciali e riassunti di notizie. Questo metodo di selezione dei dati ha prodotto risultati positivi, escludendo quelli problematici come i calcoli matriciali e i riassunti di notizie, tipici aree in cui i modelli addestrati su dati sintetici tendono a collassare.
Inoltre, il meccanismo di feedback proposto dai ricercatori può automatizzare parzialmente o completamente la selezione e l’organizzazione dei dati sintetici. Di conseguenza, è considerato molto più efficiente rispetto all’apprendimento per rinforzo con feedback umano (RLHF).
Per validare questa tecnica, è stato utilizzato il modello open source ‘Rama3’ per selezionare i dati sintetici più adatti all’addestramento. È emerso che, pur utilizzando solo il 12,5% dei dati disponibili, il modello ha ottenuto prestazioni superiori rispetto alla versione originale addestrata sull’intero set di dati.
Il modello addestrato con questi dati sintetici selezionati ha dimostrato prestazioni migliori, evidenziando che questo metodo proposto è efficace nel prevenire il collasso del modello.
Questa ricerca rappresenta un passo avanti significativo nella gestione dei dati sintetici nell’addestramento dei modelli di intelligenza artificiale, aprendo la strada a nuove possibilità di sviluppo senza compromettere la qualità delle prestazioni.