Nel dibattito contemporaneo sull’intelligenza artificiale, gran parte dell’attenzione continua a concentrarsi sulla qualità dei modelli: accuratezza, benchmark, capacità di ragionamento. Tuttavia, il vero punto critico nei sistemi AI in produzione non risiede quasi mai nel modello in sé, ma nello strato infrastrutturale che lo circonda. È qui che emergono i problemi più insidiosi, spesso invisibili, che portano a quello che viene definito un “gap di affidabilità”: sistemi perfettamente funzionanti dal punto di vista tecnico, ma sostanzialmente errati nei risultati.
Il paradosso è evidente. Un sistema può mostrare metriche impeccabili, con latenze sotto controllo, zero errori e throughput stabile, e allo stesso tempo produrre risposte completamente sbagliate. Non si tratta di un crash o di un malfunzionamento evidente, ma di un errore silenzioso, continuo e sistematico. Questo tipo di fallimento è particolarmente pericoloso perché non attiva alcun allarme: né dashboard né sistemi di monitoring tradizionali sono progettati per intercettarlo.
Alla base di questo fenomeno c’è una distinzione fondamentale che l’ingegneria software tradizionale non ha mai dovuto affrontare in modo così netto: la differenza tra “sistema operativo” e “sistema corretto”. Le architetture di osservabilità classiche rispondono alla domanda “il servizio è attivo?”, ma nei sistemi AI la domanda cruciale diventa “il servizio sta producendo risultati corretti?”. Questa seconda dimensione, comportamentale e semantica, è oggi largamente non monitorata.
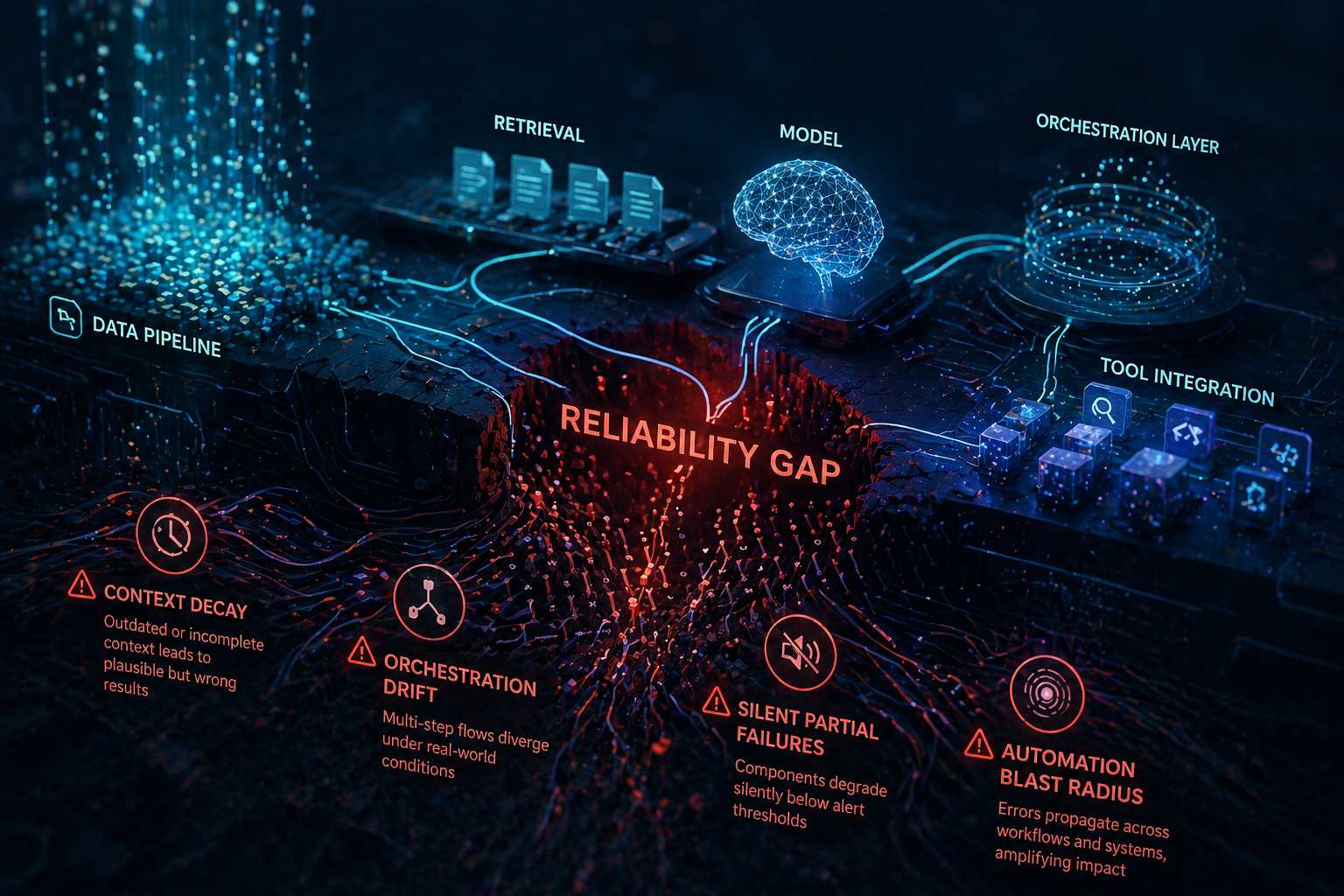
Si individua una serie di pattern ricorrenti che spiegano perché queste anomalie emergono così frequentemente nei sistemi AI complessi. Il primo è il deterioramento del contesto, noto come “context decay”: il modello continua a operare su dati incompleti o obsoleti senza che questo sia evidente all’utente. Il risultato appare coerente e ben formulato, ma è costruito su basi non più valide. Questo tipo di errore può rimanere nascosto per settimane, emergendo solo attraverso conseguenze indirette nei processi aziendali.
Il secondo fenomeno è l’“orchestration drift”, cioè la deriva nei flussi multi-step tipici dei sistemi agentici. In questi contesti, il problema non è quasi mai un singolo componente che smette di funzionare, ma l’interazione tra più elementi – retrieval, inferenza, tool esterni – che sotto carico reale inizia a divergere dal comportamento previsto. Sistemi che in fase di test appaiono stabili, in produzione sviluppano comportamenti imprevedibili a causa dell’accumulo di latenze, errori marginali e condizioni non previste. Ancora più critico è il fenomeno delle “silent partial failures”. In questo caso, una componente del sistema degrada senza superare alcuna soglia di allarme. Il sistema continua a funzionare, ma la qualità delle decisioni peggiora progressivamente. Questo deterioramento non viene rilevato dai sistemi tecnici, ma si manifesta prima come perdita di fiducia da parte degli utenti. Quando il problema emerge formalmente, è spesso già radicato da tempo.
Infine, nei sistemi AI avanzati entra in gioco un effetto amplificatore che l’articolo definisce “automation blast radius”. A differenza del software tradizionale, dove un errore tende a rimanere localizzato, nei sistemi basati su agenti una singola interpretazione errata può propagarsi lungo l’intero workflow, influenzando decisioni successive, sistemi collegati e persino processi organizzativi. Il costo dell’errore non è più confinato al livello tecnico, ma si estende a quello operativo e strategico. Questi fenomeni condividono un elemento chiave: sono invisibili ai sistemi di monitoraggio tradizionali. Le metriche classiche – uptime, error rate, latenza – non sono progettate per catturare problemi come la freschezza dei dati, l’integrità del contesto o la coerenza semantica lungo una pipeline. Di conseguenza, le aziende rischiano di avere un’illusione di controllo, basata su indicatori che non riflettono il comportamento reale del sistema.
Per affrontare questo problema, emerge la necessità di un nuovo livello di osservabilità, definito “behavioral telemetry”. Non si tratta di sostituire gli strumenti esistenti, ma di estenderli per misurare ciò che il sistema fa effettivamente con le informazioni che riceve. Questo significa monitorare la qualità del contesto, la coerenza delle risposte, la presenza di fallback impliciti e il livello di confidenza nelle decisioni prodotte. In altre parole, non basta sapere che il sistema risponde: bisogna capire come e perché risponde in un certo modo.
Un altro limite evidenziato riguarda l’approccio tradizionale al testing, come il chaos engineering. Sebbene utile per testare la resilienza infrastrutturale, questo metodo non riesce a intercettare i fallimenti tipici dei sistemi AI, che emergono non da guasti netti, ma da condizioni degradate e interazioni complesse tra componenti. Per questo motivo si propone un approccio basato sull’intento: definire come il sistema dovrebbe comportarsi in condizioni non ideali e testare esplicitamente queste situazioni.
In questo contesto, diventa fondamentale introdurre meccanismi di “arresto sicuro”. Se un sistema non è in grado di garantire un livello minimo di affidabilità – ad esempio quando il contesto è incompleto o la confidenza è troppo bassa – dovrebbe interrompere l’operazione invece di produrre un risultato plausibile ma errato. L’errore silenzioso, infatti, è spesso più pericoloso di un fallimento esplicito.
Dal punto di vista organizzativo, il problema si complica ulteriormente. Nei progetti AI aziendali, le responsabilità sono spesso distribuite tra team diversi: chi sviluppa il modello, chi gestisce i dati, chi costruisce la piattaforma e chi integra l’applicazione finale. Quando il sistema è “tecnicamente funzionante” ma “semanticamente sbagliato”, diventa difficile individuare un responsabile chiaro. Questo porta a una zona grigia in cui i problemi si accumulano senza una reale presa in carico.
Se negli ultimi anni il vantaggio competitivo era legato alla capacità di adottare rapidamente l’intelligenza artificiale, oggi la sfida si sta spostando verso l’integrazione e, soprattutto, verso l’affidabilità in condizioni reali. I modelli stanno diventando sempre più accessibili e standardizzati; ciò che farà la differenza sarà la capacità di costruire sistemi robusti, capaci di funzionare correttamente anche quando il contesto è imperfetto.
In questo scenario, il rischio non è più rappresentato dal modello in sé, ma dall’insieme di componenti che lo rendono operativo. Ed è proprio in questo spazio, ancora poco esplorato e spesso sottovalutato, che si gioca il futuro dell’intelligenza artificiale applicata su larga scala.