Veicolo a guida autonoma alimentato da intelligenza artificiale
Modello di intelligenza artificiale (AI) che gestisce più attività di controllo e percezione contemporaneamente nella guida di un veicolo in sicurezza in ambienti diversi
Un gruppo di ricerca composto da Oskar Natan, un Ph.D. studente, e il suo supervisore, il professor Jun Miura, che sono affiliati all’Active Intelligent System Laboratory (AISL), Dipartimento di Ingegneria Informatica, Toyohashi University of Technology, hanno sviluppato un modello di intelligenza artificiale in grado di gestire la percezione e il controllo contemporaneamente per una guida autonoma veicolo. Il modello AI percepisce l’ambiente completando diversi compiti di visione mentre guida il veicolo seguendo una sequenza di punti del percorso. Inoltre, il modello AI può guidare il veicolo in sicurezza in diverse condizioni ambientali in vari scenari. Valutato in attività di navigazione punto a punto, il modello di intelligenza artificiale raggiunge la migliore guidabilità di alcuni modelli recenti in un ambiente di simulazione standard.
Dettagli
La guida autonoma è un sistema complesso costituito da diversi sottosistemi che gestiscono molteplici compiti di percezione e controllo. Tuttavia, l’implementazione di più moduli specifici per attività è costosa e inefficiente, poiché sono ancora necessarie numerose configurazioni per formare un sistema modulare integrato. Inoltre, il processo di integrazione può portare alla perdita di informazioni poiché molti parametri vengono regolati manualmente. Con la ricerca rapida sul deep learning, questo problema può essere affrontato addestrando un singolo modello di intelligenza artificiale con modalità end-to-end e multi-task. Pertanto, il modello può fornire controlli di navigazione basati esclusivamente sulle osservazioni fornite da una serie di sensori. Poiché la configurazione manuale non è più necessaria, il modello può gestire le informazioni da solo.
La sfida che rimane per un modello end-to-end è come estrarre informazioni utili in modo che il controllore possa stimare correttamente i controlli di navigazione. Questo può essere risolto fornendo molti dati al modulo di percezione per percepire meglio l’ambiente circostante. Inoltre, una tecnica di fusione dei sensori può essere utilizzata per migliorare le prestazioni poiché fonde diversi sensori per acquisire vari aspetti dei dati. Tuttavia, un enorme carico di calcolo è inevitabile poiché è necessario un modello più grande per elaborare più dati. Inoltre, è necessaria una tecnica di preelaborazione dei dati poiché sensori variabili spesso sono dotati di modalità di dati diverse. Inoltre, l’apprendimento dello squilibrio durante il processo di formazione potrebbe essere un altro problema poiché il modello esegue contemporaneamente sia compiti di percezione che di controllo.
Per rispondere a queste sfide, il team propone un modello di intelligenza artificiale addestrato con modalità end-to-end e multi-task. Il modello è composto da due moduli principali, ovvero i moduli di percezione e di controllo. La fase di percezione inizia elaborando immagini RGB e mappe di profondità fornite da una singola telecamera RGBD. Quindi, le informazioni estratte dal modulo di percezione insieme alla misurazione della velocità del veicolo e alle coordinate del punto di rotta vengono decodificate dal modulo di controllo per stimare i controlli di navigazione. Per garantire che tutte le attività possano essere eseguite allo stesso modo, il team utilizza un algoritmo chiamato normalizzazione del gradiente modificato (MGN) per bilanciare il segnale di apprendimento durante il processo di formazione. Il team prende in considerazione l’apprendimento per imitazione in quanto consente al modello di apprendere da un set di dati su larga scala per soddisfare uno standard quasi umano. Inoltre,
Sulla base del risultato sperimentale in un simulatore di guida autonomo standard, CARLA, è stato rivelato che la fusione di immagini RGB e mappe di profondità per formare una mappa semantica a volo d’uccello (BEV) può aumentare le prestazioni complessive. Poiché il modulo di percezione ha una migliore comprensione generale della scena, il modulo controller può sfruttare informazioni utili per stimare correttamente i controlli di navigazione. Inoltre, il team afferma che il modello proposto è preferibile per la distribuzione in quanto ottiene una migliore guidabilità con meno parametri rispetto ad altri modelli.
Prospettive future
Il team sta attualmente lavorando su modifiche e miglioramenti al modello in modo da affrontare diversi problemi durante la guida in condizioni di scarsa illuminazione, come di notte, sotto la pioggia battente, ecc. A titolo di ipotesi, il team ritiene che l’aggiunta di un sensore che non sia interessato modificando la luminosità o l’illuminazione, come LiDAR, migliorerà le capacità di comprensione della scena del modello e si tradurrà in una migliore guidabilità. Un altro compito futuro è applicare il modello proposto alla guida autonoma nel mondo reale.
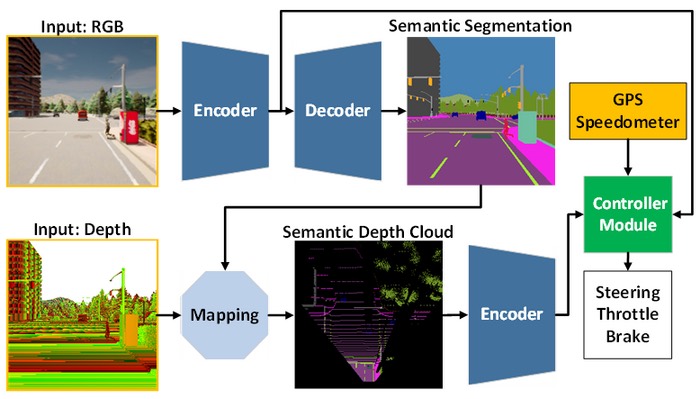
L’architettura del modello AI è composta dal modulo di percezione (blu) e dal modulo controller (verde).
Il modulo di percezione è responsabile della percezione dell’ambiente in base ai dati di osservazione forniti da una telecamera RGBD.
Nel frattempo, il modulo controller è responsabile della decodifica delle informazioni estratte per stimare il grado di sterzo, acceleratore e frenata.
CREDITO
COPYRIGHT (C) TOYOHASHI UNIVERSITY OF TECHNOLOGY.