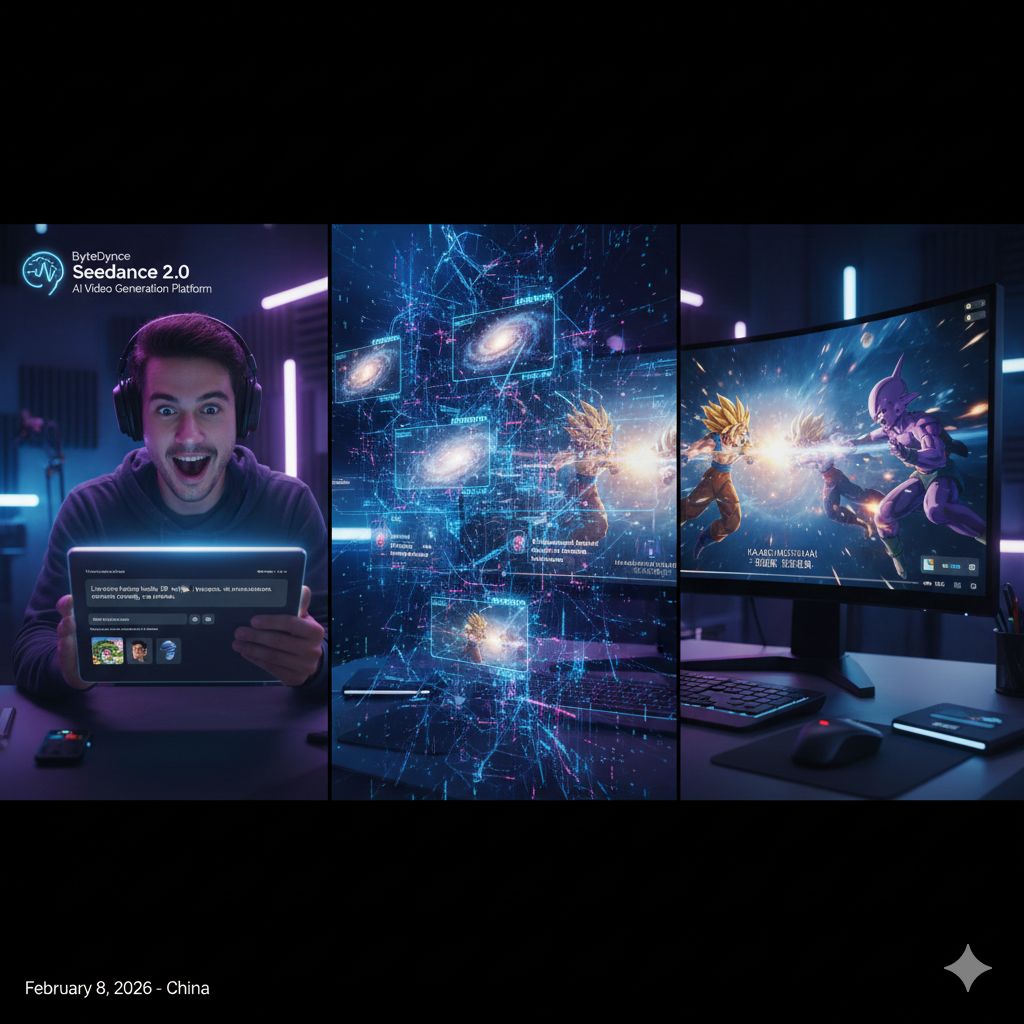
L’annuncio del nuovo modello di generazione video basato sull’intelligenza artificiale di ByteDance sta attirando un’attenzione crescente non solo tra i creatori di contenuti digitali, ma anche all’interno dell’industria audiovisiva più strutturata. Con la presentazione di Seedance 2.0, avvenuta l’8 del mese in Cina, emerge la sensazione che la produzione video stia entrando in una fase qualitativamente diversa, in cui l’intelligenza artificiale non si limita più a supportare il processo creativo, ma inizia a inglobarlo quasi interamente.
Nonostante l’assenza, al momento, di documentazione tecnica ufficiale, le testimonianze dei primi tester delineano un quadro piuttosto chiaro delle ambizioni del modello. Seedance 2.0 sarebbe in grado di generare automaticamente video ad alta risoluzione, fino a due minuti di durata, partendo esclusivamente da input testuali, immagini e audio. Si tratta di un salto rilevante rispetto alle generazioni precedenti, soprattutto se si considera che la risoluzione supportata arriva stabilmente a 1080p e, in alcuni casi sperimentali, persino a 2K, con una qualità visiva che si avvicina a quella delle produzioni professionali.
Uno degli aspetti più interessanti è la capacità nativa di creare video multi-shot. Questo significa che il modello non produce una singola sequenza statica, ma costruisce una narrazione composta da più scene, con transizioni coerenti e fluide, senza richiedere interventi manuali di montaggio. In pratica, un singolo prompt può tradursi in una sequenza narrativa completa, riducendo drasticamente il tempo e le competenze necessarie per ottenere un risultato strutturato.
Seedance 2.0 sembra spingersi oltre anche sul piano della sincronizzazione multimodale. A differenza di molte soluzioni precedenti, che generano video e audio come elementi separati poi allineati in un secondo momento, questo modello calcola immagini e suoni insieme fin dalla fase di creazione. L’effetto più evidente di questo approccio è una sincronizzazione labiale estremamente accurata, dichiarata a livello di fonema, con supporto per oltre otto lingue e per voci multilingue. Questa integrazione profonda tra audio e video contribuisce a rendere le scene più credibili, soprattutto nei dialoghi e nelle sequenze narrative complesse.
Dai primi test emerge anche una notevole capacità di controllo sugli elementi multimodali. Seedance 2.0 consentirebbe di utilizzare fino a dodici file di riferimento, tra immagini e audio, per guidare la generazione del contenuto. Questo permette di definire con maggiore precisione frame iniziali e finali, stile visivo, atmosfera sonora e ritmo complessivo, distinguendo il modello da molte soluzioni concorrenti che offrono un controllo più limitato o meno prevedibile sull’output finale.
Sul fronte delle prestazioni, ByteDance parla di un miglioramento significativo rispetto alle versioni precedenti. La velocità di generazione dei video sarebbe aumentata di circa il 30%, mentre la lunghezza massima dei contenuti generabili sarebbe triplicata. Alcuni materiali introduttivi arrivano addirittura a sostenere che le prestazioni percepite siano fino a dieci volte superiori, un dato che, se confermato, rafforzerebbe ulteriormente l’idea di un cambio di paradigma nella produzione video automatizzata.
I filmati condivisi dai primi utilizzatori contribuiscono ad alimentare questa percezione. Tra gli esempi circolati online figurano scene che, fino a poco tempo fa, avrebbero richiesto budget elevati e team di produzione complessi, come una battaglia live-action ispirata a Dragon Ball Z, una sequenza cyberpunk che richiama lo stile di Arcane o una scena di film di guerra con dialoghi in lingua russa. Questi esempi non colpiscono solo per l’estetica, ma per la completezza dell’esperienza audiovisiva, che include effetti visivi, movimento, dialoghi e colonna sonora generati in modo coerente.
Per questo motivo, Seedance 2.0 viene sempre più spesso descritto non come un semplice strumento per creare video migliori, ma come una tecnologia che integra e ridefinisce il processo produttivo stesso. La possibilità di passare direttamente da un’idea descritta in linguaggio naturale a un video narrativo complesso mette in discussione molte delle fasi tradizionali della filiera audiovisiva, dalla pre-produzione al montaggio.
Al momento, tuttavia, l’accesso al modello è limitato alla Cina e la struttura tecnica interna non è stata resa pubblica. Secondo alcune previsioni, un lancio più ampio potrebbe avvenire in prossimità delle festività del Capodanno lunare, ma si tratta di ipotesi non ancora confermate. Nonostante ciò, l’impatto dei contenuti già diffusi è stato tale da spingere molti osservatori a parlare apertamente di “futuro della creazione di contenuti”.
L’industria cinematografica guarda a queste evoluzioni con un misto di interesse e preoccupazione. Da un lato, la possibilità di ridurre drasticamente i costi di produzione di effetti visivi e scene complesse apre scenari creativi prima inaccessibili, soprattutto per produzioni indipendenti. Dall’altro, alcuni registi e professionisti del settore temono che modelli come Seedance 2.0 possano progressivamente erodere il ruolo di figure chiave come attori, troupe tecniche e persino registi, soprattutto nelle produzioni a basso e medio budget.
Il contesto competitivo rende il quadro ancora più dinamico. La recente uscita di Kuaishou con il modello Kling 3.0, accolto positivamente per il salto qualitativo nei video generati dall’AI, suggerisce che il settore stia avanzando molto rapidamente. L’idea che un’intelligenza artificiale possa trasformare istantaneamente uno scenario descritto a parole in un video di alta qualità non è più fantascienza, ma una prospettiva concreta e sempre più vicina.