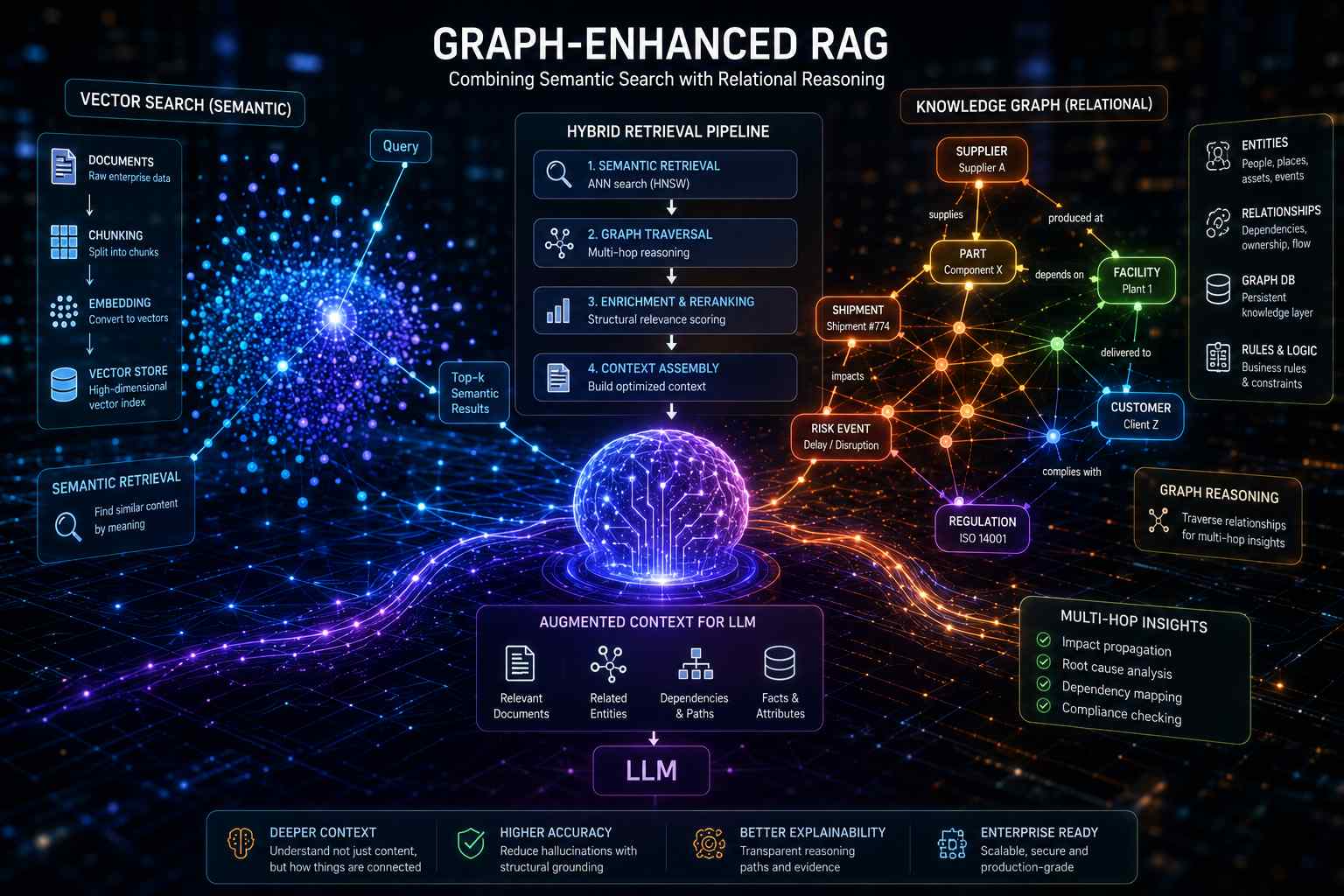
Nei contesti enterprise più complessi, la semplice vicinanza semantica tra embedding non è più sufficiente per gestire relazioni operative, dipendenze e strutture gerarchiche che caratterizzano dati industriali, supply chain, compliance finanziaria o ambienti multi-tenant. Il nuovo paradigma che sta emergendo è il graph-enhanced RAG, un’architettura ibrida che combina retrieval vettoriale e knowledge graph per consentire ragionamento strutturale e multi-hop reasoning nei workflow AI in produzione.
Nel modello RAG tradizionale, i documenti vengono suddivisi in chunk, trasformati in embedding e salvati in un vector store dove il recupero avviene tramite similarità matematica. Questo approccio funziona molto bene per la ricerca semantica su dati non strutturati, ma tende a perdere completamente il contesto relazionale originale durante il chunking. Le connessioni tra entità, dipendenze operative, ownership e relazioni causali vengono “appiattite” nel passaggio verso lo spazio vettoriale. In pratica il sistema riesce a recuperare contenuti semanticamente simili, ma non comprende realmente come gli elementi siano collegati tra loro all’interno del dominio aziendale.
Il problema emerge soprattutto nelle query multi-hop. In uno scenario di supply chain, ad esempio, un sistema vector-only può recuperare correttamente una notizia relativa a un blocco produttivo presso un fornitore, ma non riesce a dedurre automaticamente quali componenti, stabilimenti o clienti finali dipendano da quel fornitore. Il retrieval trova il documento corretto, ma manca la struttura logica necessaria per propagare l’impatto lungo la rete di dipendenze operative. È qui che entra in gioco il layer grafico.
Le nuove architetture graph-enhanced RAG introducono quindi una knowledge layer composta da nodi ed edge che rappresentano entità e relazioni aziendali. I vector embedding continuano a svolgere il ruolo di retrieval semantico iniziale, mentre il knowledge graph permette traversal contestuali, inferenza relazionale e ranking strutturale dei risultati. In pratica il retrieval non si limita più a cercare “documenti simili”, ma può attraversare relazioni esplicite tra dati, applicando reasoning topologico direttamente durante la fase di recupero del contesto.
Molti sistemi stanno convergendo verso pipeline ibride in cui il primo passaggio utilizza ANN search e indici come HNSW per recuperare rapidamente candidati semanticamente rilevanti, mentre una seconda fase esegue enrichment e reranking tramite graph traversal o proximity graph. Questo consente di mantenere la velocità della vector search migliorando contemporaneamente copertura semantica e coerenza relazionale.
Un altro aspetto importante riguarda la crescente integrazione tra graph database e vector indexing. Diverse piattaforme stanno incorporando supporto nativo agli embedding direttamente nei motori grafici, consentendo query ibride che combinano similarità vettoriale e navigazione relazionale all’interno dello stesso layer dati. Questo riduce la frammentazione architetturale tipica dei primi sistemi RAG enterprise, dove vector store, knowledge graph e database operavano come componenti separati da sincronizzare continuamente.
L’obiettivo finale di queste architetture non è sostituire la vector search, ma superarne i limiti nei domini ad alta interconnessione. I modelli linguistici continuano ad avere bisogno della capacità semantica degli embedding, ma sempre più organizzazioni stanno riconoscendo che l’intelligenza contestuale reale richiede anche rappresentazioni esplicite delle relazioni tra entità. Il graph-enhanced RAG rappresenta quindi un passaggio verso sistemi AI enterprise in grado non solo di “trovare informazioni”, ma di comprendere la struttura operativa sottostante ai dati aziendali.