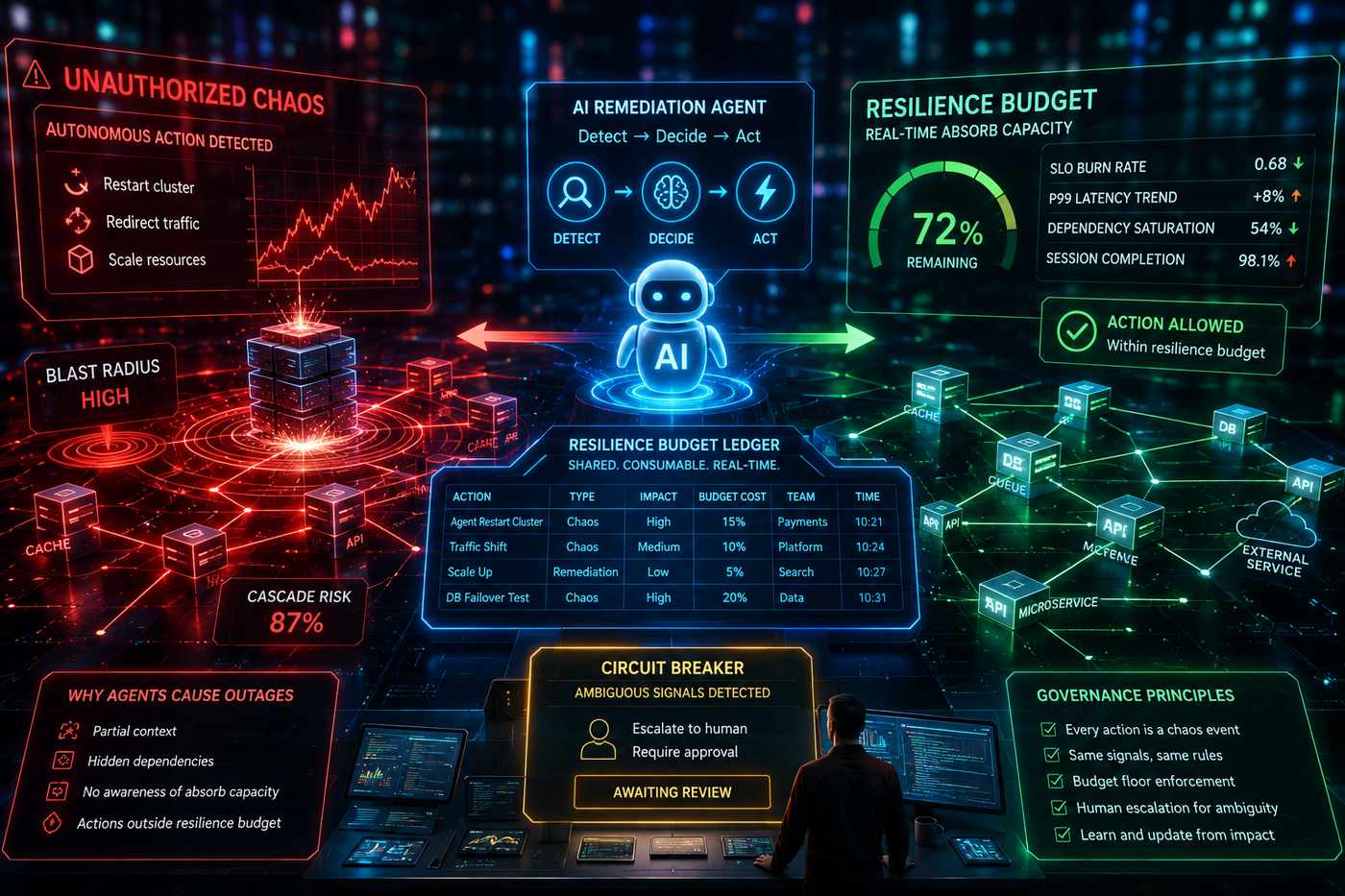
C’è una classe di incidenti di produzione che le aziende stanno generando da mesi senza riuscire a classificarla, perché cade nel mezzo fra due discipline che continuiamo a trattare separatamente: l’autonomia degli agenti AI da una parte, il chaos engineering dall’altra. Il punto è che non sono due cose distinte. Un agente di remediation che riavvia un cluster, sposta traffico o riscala risorse in risposta a un’anomalia sta, a tutti gli effetti, iniettando una perturbazione in un sistema vivo. È un esperimento di caos, solo che nessuno lo ha autorizzato e nessuno ne ha calcolato il blast radius.
La differenza rispetto a un game day fatto da un SRE non è cosmetica. Quando un ingegnere lancia un esperimento, prima guarda la dashboard, controlla il burn rate dell’error budget, valuta se le dipendenze sono stabili, decide se questo è il momento giusto per introdurre stress aggiuntivo. È un giudizio imperfetto, spesso intuitivo, ma c’è. Un agente autonomo quella domanda non se la pone: vede l’anomalia, esegue l’azione, e l’azione è corretta rispetto al contesto ristretto che l’agente possiede. Il problema è che quel contesto quasi sempre non include lo stato del pool di connessioni condiviso, il rebuild di indice in corso su un database dipendente, il picco di traffico che tre microservizi stanno gestendo proprio ora. Il riavvio “ragionevole” diventa una thundering herd contro un servizio che si stava ancora riprendendo, e la cascata viene poi archiviata nel postmortem come saturazione del pool o spike di latenza. L’agente è invisibile.
La radice tecnica del problema è che i sistemi enterprise non trattano l’absorb capacity, cioè quanto stress aggiuntivo un sistema può ancora assorbire prima di violare gli SLO, come una risorsa misurabile e consumabile. La gestiamo implicitamente, tramite soglie statiche che si accorgono del problema solo dopo che il limite è stato superato, e tramite il giudizio degli ingegneri. Un modello più onesto la tratta come un budget di resilienza che si ricalcola di continuo, alimentato da segnali vivi: il burn rate degli SLO come input primario, perché codifica direttamente la distanza fra il comportamento attuale e l’impegno che conta davvero; il trend del p99 più del p99 assoluto, perché quaranta minuti di latenza in salita dicono qualcosa che un valore stabile non dice; lo stato di saturazione delle dipendenze, che è il segnale più sistematicamente ignorato (un’azione che assume un pool libero quando è all’87% produce modalità di guasto che nessuno ha progettato); e i segnali comportamentali applicativi come tassi di completamento sessione o shift nei pattern di chiamata API, che emergono prima dei metrics di infrastruttura perché gli utenti sentono il degrado prima di Prometheus. La parte cruciale è che il budget è consumabile e condiviso: ogni esperimento di caos lo intacca, ogni azione di agente lo intacca, e in organizzazioni con più team che operano su dipendenze sovrapposte, senza un ledger condiviso il blast radius combinato sfugge a chiunque.
Sui modelli linguistici applicati alla generazione di ipotesi di caos il quadro è più sottile di come viene di solito raccontato. Funzionano discretamente quando attingono a corpora di postmortem, perché lì il segnale è validato dalla realtà di produzione passata. Falliscono in modo prevedibile quando si appoggiano a dependency graph, perché un grafo che non riflette l’estrazione di servizio del mese scorso o una libreria condivisa aggiunta due sprint fa porta il modello a essere confidentemente sbagliato sui confini del sistema, e nel chaos engineering “confidentemente sbagliato in produzione” è il sinonimo operativo di outage non pianificato. C’è poi una soglia oltre cui il modello non andrebbe spinto: la decisione di esecuzione quando i segnali sono ambigui. Quella decisione richiede consapevolezza di cose che vivono fuori da qualsiasi sistema di monitoring (deployment pendenti, livelli di staffing di on-call in un weekend festivo, un impegno verso un cliente che rende inaccettabile qualunque rischio fino a lunedì) e nessuna telemetria rappresenta quel contesto. Non è una limitazione temporanea in attesa di modelli migliori, è un vincolo strutturale di ciò che l’osservabilità macchina può catturare.
La conseguenza di governance è meno spettacolare di quanto venga di solito venduto, ma è quella che fa la differenza: ogni azione di un agente autonomo che tocca infrastruttura deve registrarsi contro lo stesso strato di segnali vivi che governa gli esperimenti di caos. Stessi burn rate, stesse saturazioni, stesso trend di latenza. Se il budget di resilienza è sotto un floor definito, l’agente attende o escala, punto. E le azioni dell’agente vanno modellate come esperimenti, non solo loggate come eventi: la domanda non è se il restart è andato a buon fine, è se il suo blast radius era proporzionato alla capacità di assorbimento disponibile e quali effetti a cascata ha prodotto sulle dipendenze. È dato di chaos engineering, e serve a istruire la decisione successiva. Il circuit breaker che passa i casi ambigui a un umano non è una debolezza dell’architettura agentica; è precisamente ciò che la rende abbastanza affidabile da girare in produzione. Le organizzazioni che fanno girare agenti autonomi a scala in modo stabile non sono quelle con i modelli più sofisticati, sono quelle che hanno capito, prima che andasse male qualcosa di grosso, che ogni azione di agente è un evento di caos e che il livello di governance va costruito di conseguenza.
Il primo passo concreto è poco glamour: fare l’audit di ogni agente autonomo che oggi tocca l’infrastruttura, mappare la sua superficie d’azione contro i segnali di burn rate degli SLO, e definire le condizioni di floor sotto cui l’agente è obbligato ad attendere o escalare. Quell’audit, nella stragrande maggioranza dei casi, fa emergere agenti che stanno agendo completamente fuori dalla contabilità di resilienza dell’azienda. Conviene trovarli prima che li trovi la produzione.