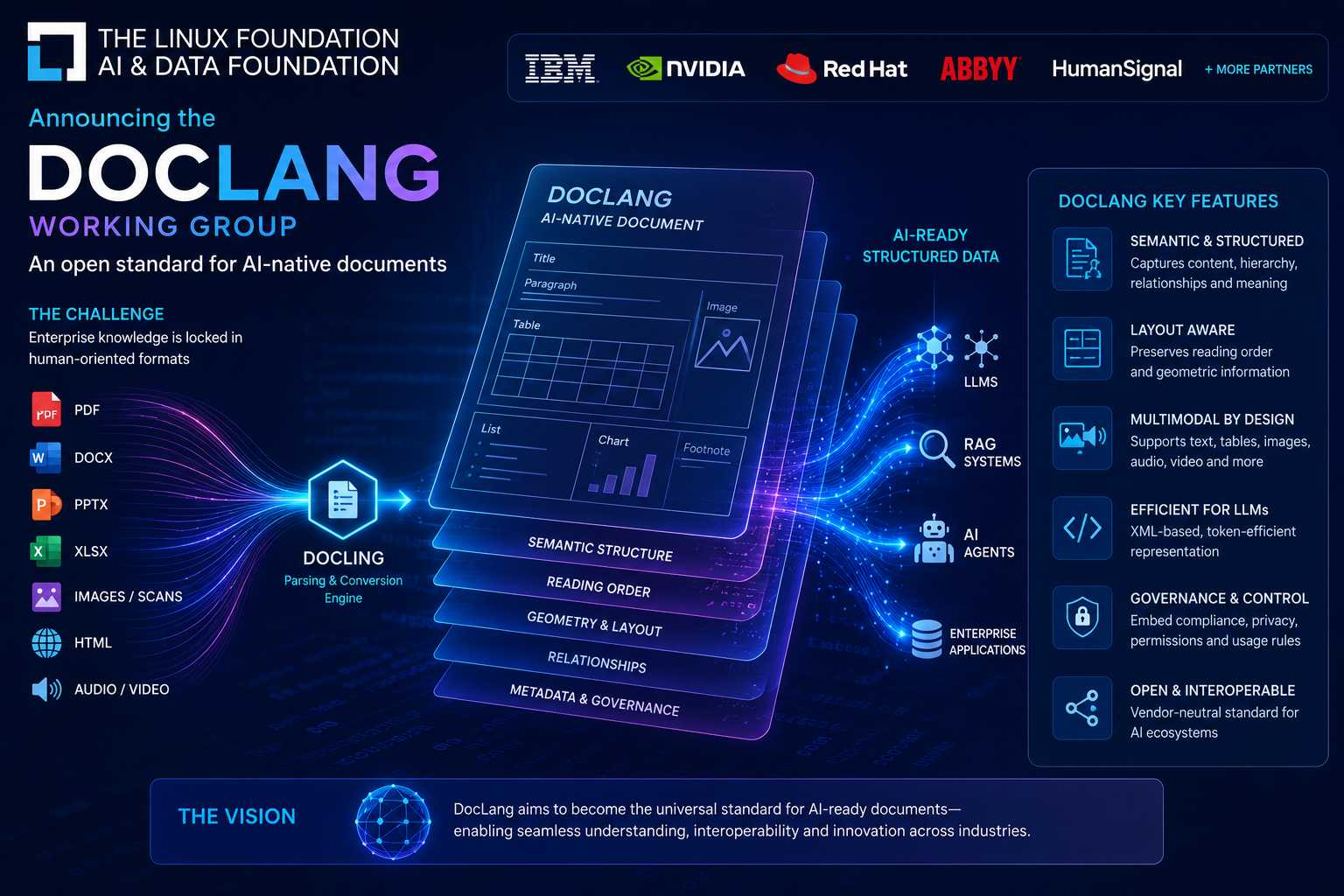
La Linux Foundation AI & Data Foundation ha annunciato la creazione del gruppo di lavoro dedicato a DocLang, una nuova specifica aperta progettata per definire un formato documentale nativo per l’intelligenza artificiale. L’iniziativa nasce dalla collaborazione tra IBM, NVIDIA, Red Hat, ABBYY, HumanSignal e altri partner industriali con l’obiettivo di creare un linguaggio comune per rappresentare documenti, immagini, tabelle, presentazioni e altri contenuti non strutturati in una forma più facilmente interpretabile da modelli linguistici, sistemi RAG e agenti autonomi.
L’idea alla base del progetto è che gran parte della conoscenza aziendale continua a essere conservata in formati pensati per la consultazione umana, come PDF, documenti Office, immagini e scansioni, che richiedono complessi processi di estrazione e normalizzazione prima di poter essere utilizzati efficacemente da sistemi AI. DocLang introduce invece una rappresentazione strutturata che conserva contemporaneamente contenuto, gerarchia semantica, relazioni tra elementi, ordine di lettura e informazioni geometriche relative al layout della pagina.
La specifica è stata progettata per essere particolarmente efficiente nell’elaborazione da parte dei modelli linguistici. Il formato utilizza una struttura XML controllata e una codifica orientata alla tokenizzazione dei LLM, riducendo il numero di token necessari per rappresentare documenti complessi rispetto a formati tradizionali come HTML o conversioni testuali non strutturate. Ogni elemento mantiene informazioni sulla propria funzione semantica, sulla posizione all’interno della pagina e sulle relazioni con gli altri componenti del documento.
Un aspetto rilevante riguarda il supporto nativo per contenuti multimodali. Oltre a testi, tabelle e moduli, DocLang è stato progettato per rappresentare anche immagini, trascrizioni audio, segmenti video e contenuti complessi attraverso un insieme uniforme di primitive strutturali. Questo approccio consente di utilizzare una rappresentazione comune per diverse tipologie di dati che oggi vengono normalmente trattate tramite pipeline separate.
La nuova specifica si integra inoltre con Docling, il framework open source sviluppato originariamente da IBM Research per la conversione di documenti in rappresentazioni strutturate. Docling svolge il ruolo di livello di acquisizione e parsing, trasformando PDF, DOCX, PPTX, fogli di calcolo, pagine HTML e immagini in strutture documentali organizzate. DocLang interviene successivamente come standard aperto per la rappresentazione e lo scambio di tali informazioni tra piattaforme, applicazioni e modelli AI differenti.
Tra le funzionalità previste figurano anche meccanismi per la gestione della governance dei dati, con la possibilità di incorporare metadati relativi a conformità, privacy, autorizzazioni di utilizzo e restrizioni per l’addestramento dei modelli. L’obiettivo è creare un livello documentale interoperabile che possa essere utilizzato in scenari enterprise, workflow agentici, sistemi di ricerca avanzata, piattaforme document intelligence e applicazioni di automazione basate su modelli generativi.
Secondo i promotori dell’iniziativa, la visione a lungo termine è quella di trasformare DocLang in uno standard aperto ampiamente adottato per i documenti AI-ready, svolgendo per l’ecosistema dell’intelligenza artificiale un ruolo simile a quello che il PDF ha avuto per la distribuzione e la conservazione dei documenti nell’era delle applicazioni orientate agli utenti umani.