DALL-E 2, il futuro della ricerca sull’IA e il modello di business di OpenAI
Il laboratorio di ricerca sull’intelligenza artificiale OpenAI ha fatto di nuovo notizia, questa volta con DALL-E 2, un modello di apprendimento automatico in grado di generare immagini straordinarie da descrizioni di testo. DALL-E 2 si basa sul successo del suo predecessore DALL-E e migliora la qualità e la risoluzione delle immagini di output grazie a tecniche avanzate di deep learning .
L’annuncio di DALL-E 2 è stato accompagnato da una campagna sui social media degli ingegneri di OpenAI e del suo CEO, Sam Altman, che hanno condiviso su Twitter meravigliose foto create dal modello di apprendimento automatico generativo.
DALL-E 2 mostra fino a che punto è arrivata la comunità di ricerca sull’IA per sfruttare il potere del deep learning e affrontare alcuni dei suoi limiti. Fornisce inoltre una prospettiva su come i modelli di apprendimento profondo generativo potrebbero finalmente sbloccare nuove applicazioni creative che tutti possono utilizzare. Allo stesso tempo, ci ricorda alcuni degli ostacoli che rimangono nella ricerca sull’IA e le controversie che devono essere risolte.
La bellezza di DALL-E 2
Come altri importanti annunci OpenAI, DALL-E 2 viene fornito con un documento dettagliato e un post sul blog interattivo che mostra come funziona il modello di apprendimento automatico. C’è anche un video che fornisce una panoramica di ciò che la tecnologia è in grado di fare e quali sono i suoi limiti.
DALL-E 2 è un “modello generativo”, una branca speciale dell’apprendimento automatico che crea output complessi invece di eseguire attività di previsione o classificazione sui dati di input. Fornisci a DALL-E 2 una descrizione testuale e genera un’immagine che si adatta alla descrizione.
I modelli generativi sono un’area di ricerca calda che ha ricevuto molta attenzione con l’introduzione delle reti generative contraddittorio (GAN) nel 2014. Il campo ha visto enormi miglioramenti negli ultimi anni e i modelli generativi sono stati utilizzati per un’ampia varietà di compiti, inclusa la creazione di facce artificiali, deepfake , voci sintetizzate e altro ancora.
Tuttavia, ciò che distingue DALL-E 2 dagli altri modelli generativi è la sua capacità di mantenere la coerenza semantica nelle immagini che crea.
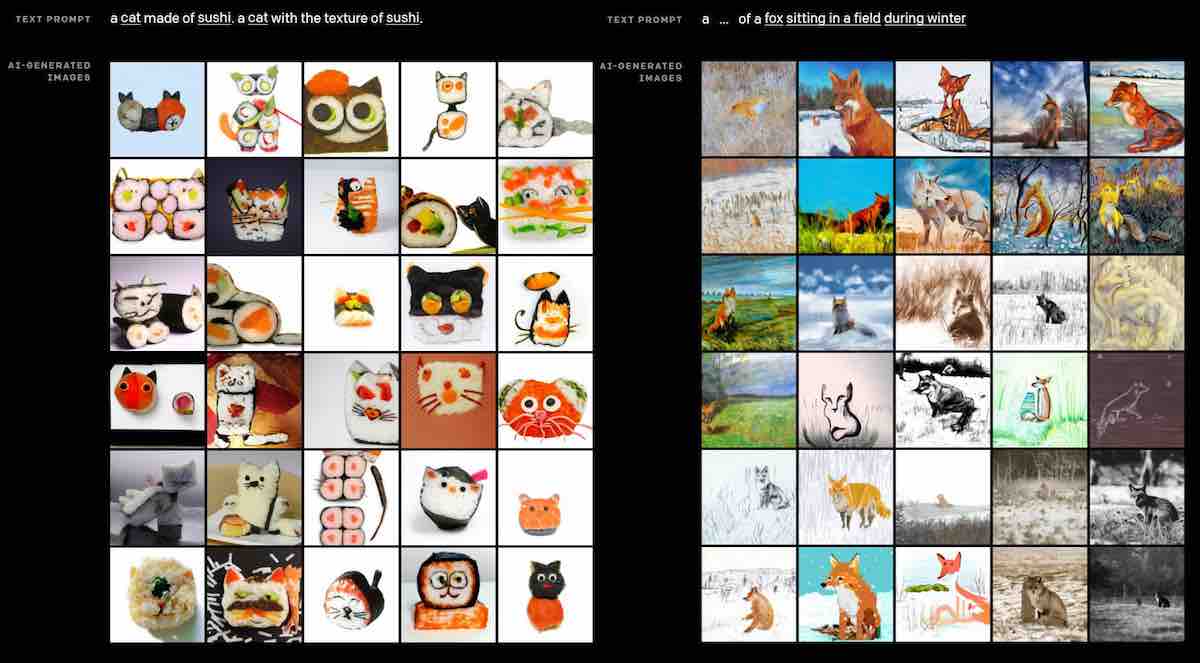
Ad esempio, le seguenti immagini (dal post del blog DALL-E 2) sono generate dalla descrizione “Un astronauta a cavallo”. Una delle descrizioni termina con “come un disegno a matita” e l’altra “in stile fotorealistico”.
Il modello rimane coerente nel disegnare l’astronauta seduto sul dorso del cavallo e tenendo le mani davanti. Questo tipo di coerenza si mostra nella maggior parte degli esempi condivisi da OpenAI.
Gli esempi seguenti (anche dal sito Web di OpenAI) mostrano un’altra caratteristica di DALL-E 2, che consiste nel generare variazioni di un’immagine di input. Qui, invece di fornire a DALL-E 2 una descrizione testuale, gli fornisci un’immagine e tenta di generare altre forme della stessa immagine. Qui, DALL-E mantiene le relazioni tra gli elementi dell’immagine, tra cui la ragazza, il laptop, le cuffie, il gatto, le luci della città sullo sfondo e il cielo notturno con luna e nuvole.
Altri esempi suggeriscono che DALL-E 2 sembra comprendere la profondità e la dimensionalità, una grande sfida per gli algoritmi che elaborano immagini 2D.
Anche se gli esempi sul sito Web di OpenAI sono stati selezionati con cura, sono impressionanti. E gli esempi condivisi su Twitter mostrano che DALL-E 2 sembra aver trovato il modo di rappresentare e riprodurre le relazioni tra gli elementi che compaiono in un’immagine, anche quando sta “inventando” qualcosa per la prima volta.
In effetti, per dimostrare quanto sia buono DALL-E 2, Altman si è rivolto a Twitter e ha chiesto agli utenti di suggerire suggerimenti per alimentare il modello generativo. I risultati (vedi il thread qui sotto) sono affascinanti.
La scienza dietro DALL-E 2
DALL-E 2 sfrutta i modelli CLIP e di diffusione, due tecniche avanzate di deep learning create negli ultimi anni. Ma in fondo, condivide lo stesso concetto di tutte le altre reti neurali profonde: l’apprendimento della rappresentazione.
Considera un modello di classificazione delle immagini. La rete neurale trasforma i colori dei pixel in un insieme di numeri che ne rappresentano le caratteristiche. Questo vettore è talvolta chiamato anche “incorporamento” dell’input. Tali caratteristiche vengono quindi mappate sul livello di output, che contiene un punteggio di probabilità per ciascuna classe di immagine che il modello dovrebbe rilevare. Durante l’addestramento, la rete neurale cerca di apprendere le migliori rappresentazioni delle caratteristiche che discriminano tra le classi.
Idealmente, il modello di apprendimento automatico dovrebbe essere in grado di apprendere funzionalità latenti che rimangono coerenti in diverse condizioni di illuminazione, angoli e ambienti di sfondo. Ma come è stato spesso visto, i modelli di deep learning spesso imparano le rappresentazioni sbagliate. Ad esempio, una rete neurale potrebbe pensare che i pixel verdi siano una caratteristica della classe “pecora” perché tutte le immagini di pecore che ha visto durante l’allenamento contengono molta erba. Un altro modello che è stato addestrato su immagini di pipistrelli scattate durante la notte potrebbe considerare l’oscurità una caratteristica di tutte le immagini di pipistrelli e classificare erroneamente le immagini di pipistrelli scattate durante il giorno. Altri modelli potrebbero diventare sensibili agli oggetti centrati nell’immagine e posizionati davanti a un certo tipo di sfondo.
Imparare le rappresentazioni sbagliate è in parte il motivo per cui le reti neurali sono fragili, sensibili ai cambiamenti nell’ambiente e scarse nel generalizzare oltre i loro dati di addestramento. È anche il motivo per cui le reti neurali addestrate per un’applicazione devono essere messe a punto per altre applicazioni: le caratteristiche degli strati finali della rete neurale sono generalmente molto specifiche per attività e non possono essere generalizzate ad altre applicazioni.
In teoria, potresti creare un enorme set di dati di addestramento che contenga tutti i tipi di variazioni di dati che la rete neurale dovrebbe essere in grado di gestire. Ma creare ed etichettare un tale set di dati richiederebbe un immenso sforzo umano ed è praticamente impossibile.
Questo è il problema che risolve il Contrastive Learning-Image Pre-training (CLIP). CLIP addestra due reti neurali in parallelo su immagini e relative didascalie. Una delle reti apprende le rappresentazioni visive nell’immagine e l’altra apprende le rappresentazioni del testo corrispondente. Durante l’allenamento, le due reti cercano di regolare i propri parametri in modo che immagini e descrizioni simili producano incorporamenti simili.
Uno dei principali vantaggi di CLIP è che non è necessario che i suoi dati di addestramento siano etichettati per un’applicazione specifica. Può essere addestrato sull’enorme numero di immagini e descrizioni sciolte che si possono trovare sul web. Inoltre, senza i rigidi confini delle categorie classiche, CLIP può apprendere rappresentazioni più flessibili e generalizzare a un’ampia varietà di attività. Ad esempio, se un’immagine è descritta come “un ragazzo che abbraccia un cucciolo” e un’altra come “un ragazzo che cavalca un pony”, il modello sarà in grado di apprendere una rappresentazione più solida di cosa sia un “ragazzo” e come si relaziona ad altri elementi nelle immagini.
ANNUNCIO
CLIP ha già dimostrato di essere molto utile per l’apprendimento zero-shot e pochi-shot , in cui un modello di machine learning viene mostrato al volo per eseguire attività per le quali non è stato addestrato.
L’altra tecnica di apprendimento automatico utilizzata in DALL-E 2 è la “diffusione”, una sorta di modello generativo che impara a creare immagini rumorizzando e denoising gradualmente i suoi esempi di addestramento. I modelli di diffusione sono come gli autoencoder , che trasformano i dati di input in una rappresentazione di incorporamento e quindi riproducono i dati originali dalle informazioni di incorporamento.
DALL-E addestra un modello CLIP su immagini e didascalie. Quindi utilizza il modello CLIP per addestrare il modello di diffusione. Fondamentalmente, il modello di diffusione utilizza il modello CLIP per generare gli incorporamenti per il prompt di testo e la sua immagine corrispondente. Quindi prova a generare l’immagine che corrisponde al testo.
Controversie su deep learning e ricerca sull’IA
Per il momento, DALL-E 2 sarà messo a disposizione solo di un numero limitato di utenti che si sono iscritti alla lista d’attesa. Dal rilascio di GPT-2 , OpenAI è stata riluttante a rilasciare i suoi modelli di intelligenza artificiale al pubblico. GPT-3, il suo modello linguistico più avanzato, è disponibile solo tramite un’interfaccia API . Non è possibile accedere al codice effettivo e ai parametri del modello.
La politica di OpenAI di non rilasciare i suoi modelli al pubblico non è andata bene con la comunità dell’IA e ha attirato critiche da parte di alcune rinomate figure del settore.
DALL-E 2 ha anche riportato alla luce alcuni dei disaccordi di lunga data sull’approccio preferito all’intelligenza artificiale generale. L’ultima innovazione di OpenAI ha sicuramente dimostrato che con la giusta architettura e i pregiudizi induttivi, puoi ancora spremere di più dalle reti neurali.
I fautori degli approcci di apprendimento profondo puro hanno colto al volo l’opportunità di sminuire i loro critici, incluso un recente saggio dello scienziato cognitivo Gary Marcus intitolato ” L’apprendimento profondo sta colpendo un muro “. Marcus sostiene un approccio ibrido che combina reti neurali con sistemi simbolici.
Sulla base degli esempi condivisi dal team di OpenAI, DALL-E 2 sembra manifestare alcune delle capacità di buon senso che da così tanto tempo mancano nei sistemi di deep learning. Ma resta da vedere quanto sia profonda questa stabilità semantica e di buon senso, e come DALL-E 2 e i suoi successori tratteranno concetti più complessi come la composizionalità.
Il documento DALL-E 2 menziona alcuni dei limiti del modello nella generazione di testo e scene complesse. Rispondendo ai numerosi tweet diretti a suo modo, Marcus ha sottolineato che il documento DALL-E 2 in effetti dimostra alcuni dei punti che ha sottolineato nei suoi articoli e saggi.
Alcuni scienziati hanno sottolineato che, nonostante gli affascinanti risultati di DALL-E 2, alcune delle sfide chiave dell’intelligenza artificiale rimangono irrisolte. Melanie Mitchell, professoressa di complessità al Santa Fe Institute, ha sollevato alcune importanti domande in un thread su Twitter .
Mitchell ha fatto riferimento ai problemi di Bongard , un insieme di sfide che mettono alla prova la comprensione di concetti come identità, adiacenza, numerosità, concavità/convessità e chiusura/apertura.
“Noi umani possiamo risolvere questi enigmi visivi grazie alla nostra conoscenza di base dei concetti di base e alle nostre capacità di astrazione flessibile e analogia”, ha twittato Mitchell. “Se un tale sistema di intelligenza artificiale fosse creato, sarei convinto che il campo stia facendo veri progressi sull’intelligenza a livello umano. Fino ad allora, ammirerò gli straordinari prodotti dell’apprendimento automatico e dei big data, ma non li scambierò per progressi verso l’intelligenza generale”.
Il business case per DALL-E 2
Da quando è passato da una struttura no profit a una struttura a “profitto limitato”, OpenAI ha cercato di trovare l’equilibrio tra la ricerca scientifica e lo sviluppo del prodotto. La partnership strategica dell’azienda con Microsoft le ha fornito solidi canali per monetizzare alcune delle sue tecnologie, tra cui GPT-3 e Codex.
In un post sul blog , Altman ha suggerito un possibile lancio del prodotto DALL-E 2 in estate. Molti analisti stanno già suggerendo applicazioni per DALL-E 2, come creare grafica per articoli (potrei sicuramente usarne alcuni per i miei) e apportare modifiche di base alle immagini. DALL-E 2 consentirà a più persone di esprimere la propria creatività senza la necessità di abilità speciali con strumenti.
Altman suggerisce che i progressi nell’IA ci stanno portando verso “un mondo in cui le buone idee sono il limite per ciò che possiamo fare, non le abilità specifiche”.
In ogni caso, le applicazioni più interessanti di DALL-E emergeranno man mano che sempre più utenti ci armeggeranno. Ad esempio, l’idea di Copilot e Codex è emersa quando gli utenti hanno iniziato a utilizzare GPT-3 per generare codice sorgente per il software.
Se OpenAI rilascia un servizio API a pagamento alla GPT-3, sempre più persone saranno in grado di creare app con DALL-E 2 o integrare la tecnologia nelle applicazioni esistenti. Ma come nel caso di GPT-3, costruire un modello di business attorno a un potenziale prodotto DALL-E 2 avrà le sue sfide uniche. Molto dipenderà dai costi di formazione e di esecuzione di DALL-E 2, i cui dettagli non sono ancora stati pubblicati.
E in quanto titolare della licenza esclusiva per la tecnologia di GPT-3, Microsoft sarà il principale vincitore di qualsiasi innovazione basata su DALL-E 2 perché sarà in grado di farlo in modo più rapido ed economico. Come GPT-3, DALL-E 2 ricorda che mentre la comunità di intelligenza artificiale continua a gravitare verso la creazione di reti neurali più grandi addestrate su set di dati di addestramento sempre più grandi, il potere continuerà a essere consolidato in alcune aziende molto ricche che hanno le risorse finanziarie e risorse tecniche necessarie per la ricerca sull’IA
