Il clustering K-means è un algoritmo di apprendimento non supervisionato e, tra tutti gli algoritmi di apprendimento non supervisionato , il clustering K-means potrebbe essere il più utilizzato, grazie alla sua potenza e semplicità. Come funziona esattamente il clustering K-means?
La risposta breve è che il clustering K-means funziona creando un punto di riferimento (un centroide) per un numero desiderato di classi e quindi assegnando i punti dati ai cluster di classi in base al punto di riferimento più vicino. Anche se questa è una definizione rapida per il clustering K-means, prendiamoci un po ‘di tempo per approfondire il clustering K-means e ottenere una migliore intuizione di come funziona.
Definizione di clustering
Prima di esaminare gli algoritmi esatti utilizzati per eseguire il clustering K-means, prendiamoci un po ‘di tempo per definire il clustering in generale.
I cluster sono solo gruppi di elementi e il raggruppamento consiste semplicemente nel mettere elementi in quei gruppi. Nel senso della scienza dei dati , gli algoritmi di clustering mirano a fare due cose:
Assicurati che tutti i punti dati in un cluster siano il più simili possibile tra loro.
Assicurati che tutti i punti dati nei diversi cluster siano il più possibile dissimili tra loro.
Gli algoritmi di raggruppamento raggruppano gli elementi in base a una metrica di somiglianza. Questo viene spesso fatto trovando il “centroide” dei diversi gruppi possibili nel set di dati, anche se non esclusivamente. Esistono diversi algoritmi di clustering, ma l’obiettivo di tutti gli algoritmi di clustering è lo stesso, determinare i gruppi intrinseci a un set di dati.
K-Means Clustering
K-Means Clustering è uno dei tipi di algoritmi di clustering più vecchi e più comunemente usati e funziona in base alla quantizzazione vettoriale . C’è un punto nello spazio selezionato come origine, quindi i vettori vengono disegnati dall’origine a tutti i punti dati nel set di dati.
In generale, il clustering K-means può essere suddiviso in cinque diversi passaggi:
Posiziona tutte le istanze in sottoinsiemi, dove il numero di sottoinsiemi è uguale a K.
Trova il punto / centroide medio delle partizioni del cluster appena create.
Sulla base di questi centroidi, assegna ogni punto a un cluster specifico.
Calcola le distanze da ogni punto ai centroidi e assegna punti ai cluster in cui la distanza dal centroide è la minima.
Dopo che i punti sono stati assegnati ai cluster, trova il nuovo centroide dei cluster.
I passaggi precedenti vengono ripetuti fino al termine del processo di formazione.

Nella fase iniziale, i centroidi sono posizionati da qualche parte tra i punti dati.
In alternativa, dopo che i centroidi sono stati posizionati, possiamo concepire il clustering di K-means come uno scambio avanti e indietro tra due diverse fasi: etichettatura dei punti dati e aggiornamento dei centroidi.
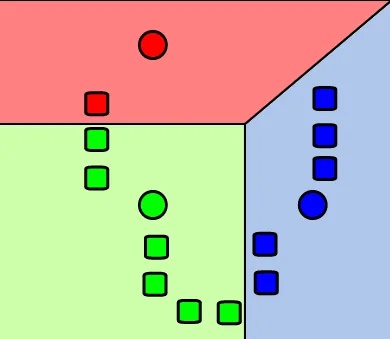
Nella seconda fase, una metrica della distanza come la distanza euclidea viene utilizzata per calcolare a quale centroide un dato punto è più vicino, quindi i punti vengono assegnati alla classe di quel centroide.
Nella fase di etichettatura del punto dati, ad ogni punto dati viene assegnata un’etichetta che lo colloca nel cluster appartenente al centroide più vicino. Il centroide più vicino viene in genere determinato utilizzando la distanza euclidea al quadrato, sebbene sia possibile utilizzare altre metriche di distanza come la distanza di Manhattan, Cosine e Jaccard a seconda del tipo di dati inseriti nell’algoritmo di clustering.
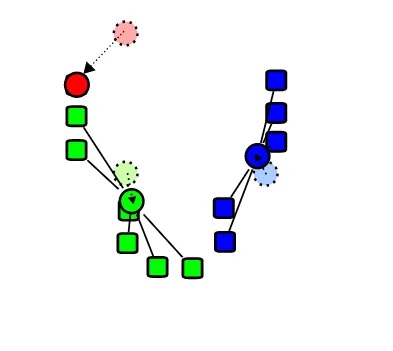
Nella terza fase, il centroide viene spostato sulla media di tutti i punti dati. Le classi vengono quindi riassegnate.
Nella fase di aggiornamento del centroide, il centroide viene calcolato trovando la distanza media tra tutti i punti dati attualmente contenuti in un cluster.
Come scegliere il valore giusto per “K”
Considerando che K-significa clustering è un algoritmo non supervisionato e il numero di classi non è noto in anticipo, come si decide il numero appropriato di classi / il valore giusto per K?
Una tecnica per selezionare il valore K corretto è chiamata ” tecnica del gomito “. La tecnica del gomito consiste nell’esecuzione di un algoritmo di clustering K-mean per un intervallo di diversi valori K e nell’utilizzo di una metrica di precisione, tipicamente la somma dell’errore quadratico, per determinare quali valori di K danno i risultati migliori. La somma dell’errore quadratico viene determinata calcolando la distanza media tra il centroide di un cluster e i punti dati in quel cluster.
Il termine “tecnica del gomito” deriva dal fatto che quando si traccia l’ESS in relazione ai diversi valori di K, il grafico a linee risultante avrà spesso una forma a “gomito”, dove SSE diminuisce rapidamente per i primi pochi valori di K, ma poi si livella. In tali condizioni, il valore di K situato al gomito è il miglior valore per K, poiché ci sono rendimenti in rapida diminuzione dopo questo valore.
Mini-batch K-Means Clustering
Man mano che i set di dati crescono, aumenta anche il tempo di calcolo. Il completamento del clustering K-means di base può richiedere molto tempo se eseguito su set di dati di grandi dimensioni e, di conseguenza, sono state apportate modifiche al clustering K-means per consentire di ridurre i costi spaziali e temporali dell’algoritmo.
Il clustering Mini-Batch K-means è una variante del clustering K-means in cui la dimensione del set di dati considerato è limitata. Il clustering K-mean normale opera sull’intero set di dati / batch contemporaneamente, mentre il clustering K-means per mini-batch suddivide il set di dati in sottoinsiemi . I mini-batch vengono campionati in modo casuale dall’intero set di dati e per ogni nuova iterazione viene selezionato un nuovo campione casuale e utilizzato per aggiornare la posizione dei centroidi.
Nel clustering Mini-Batch K-Means, i cluster vengono aggiornati con una combinazione dei valori del mini-batch e una velocità di apprendimento. La velocità di apprendimento diminuisce durante le iterazioni ed è l’inverso del numero di punti dati inseriti in un cluster specifico. L’effetto della riduzione del tasso di apprendimento è che l’impatto dei nuovi dati si riduce e si ottiene la convergenza quando, dopo diverse iterazioni, non ci sono cambiamenti nei cluster.
I risultati degli studi sull’efficacia del clustering di mezzi K mini-batch suggeriscono che può ridurre con successo il tempo di calcolo con un leggero compromesso nella qualità del cluster.
Applicazioni di K-Means Clustering
Il clustering K-means può essere utilizzato in modo sicuro in qualsiasi situazione in cui i punti dati possono essere segmentati in gruppi / classi distinti. Di seguito sono riportati alcuni esempi di casi d’uso comuni per il clustering K-mean.
Il clustering K-means potrebbe essere applicato alla classificazione dei documenti, raggruppando i documenti in base a funzionalità come argomenti, tag, utilizzo delle parole, metadati e altre funzionalità del documento. Potrebbe anche essere utilizzato per classificare gli utenti come bot o meno in base a modelli di attività come post e commenti. Il clustering K-means può essere utilizzato anche per mettere le persone in gruppi in base ai livelli di preoccupazione durante il monitoraggio della loro salute, in base a caratteristiche come comorbidità, età, anamnesi del paziente, ecc.
Il clustering K-means può essere utilizzato anche per attività più aperte come la creazione di sistemi di raccomandazione. Gli utenti di un sistema come Netflix possono essere raggruppati in base a modelli di visualizzazione e contenuti simili consigliati. Il clustering K-means potrebbe essere utilizzato per attività di rilevamento di anomalie, evidenziando potenziali casi di frode o articoli difettosi.