Un tipo comune di modello di apprendimento automatico che è riuscito a essere estremamente utile nelle competizioni di scienza dei dati è un modello di aumento del gradiente. L’aumento del gradiente è fondamentalmente il processo di conversione di modelli di apprendimento deboli in modelli di apprendimento forti. Ma come si ottiene esattamente questo? Diamo uno sguardo più da vicino agli algoritmi di aumento del gradiente e comprendiamo meglio come un modello di aumento del gradiente converte gli studenti deboli in studenti forti.
Definizione del potenziamento del gradiente
Questo articolo ha lo scopo di darti una buona intuizione su cosa sia l’aumento del gradiente, senza molte interruzioni della matematica che sta alla base degli algoritmi. Una volta che hai apprezzato il modo in cui l’aumento del gradiente opera a un livello elevato, sei incoraggiato ad andare più a fondo ed esplorare la matematica che lo rende possibile.
Cominciamo definendo cosa significa “stimolare” uno studente. Gli studenti deboli vengono convertiti in studenti forti adattando le proprietà del modello di apprendimento. Esattamente quale algoritmo di apprendimento viene potenziato?
I modelli di potenziamento funzionano aumentando un altro modello di apprendimento automatico comune, un albero decisionale.
Un modello di albero decisionale funziona suddividendo un set di dati in porzioni sempre più piccole e, una volta che i sottoinsiemi non possono essere ulteriormente suddivisi, il risultato è un albero con nodi e foglie. I nodi in un albero decisionale sono i punti in cui le decisioni sui punti dati vengono prese utilizzando diversi criteri di filtro. Le foglie in un albero decisionale sono i punti dati che sono stati classificati. Gli algoritmi dell’albero decisionale possono gestire dati sia numerici che categoriali e le suddivisioni dell’albero si basano su variabili / caratteristiche specifiche.
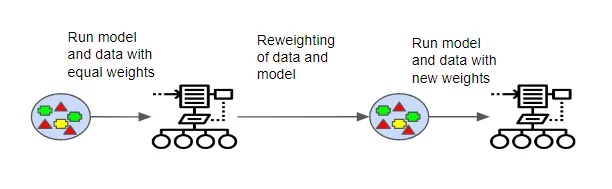
Un tipo di algoritmo di potenziamento è l’ algoritmo AdaBoost . Gli algoritmi AdaBoost iniziano addestrando un modello di albero decisionale e assegnando un peso uguale a ogni osservazione. Dopo che il primo albero è stato valutato per l’accuratezza, i pesi per le diverse osservazioni vengono regolati. Il peso delle osservazioni che erano facili da classificare è stato abbassato, mentre quello delle osservazioni difficili da classificare è stato aumentato. Un secondo albero viene creato utilizzando questi pesi regolati, con l’obiettivo che le previsioni del secondo albero siano più accurate delle previsioni del primo albero.
Il modello ora è costituito dalle previsioni per l’albero originale e il nuovo albero (o Albero 1 + Albero 2). La precisione della classificazione viene valutata ancora una volta sulla base del nuovo modello. Viene creato un terzo albero in base all’errore calcolato per il modello e i pesi vengono nuovamente regolati. Questo processo continua per un dato numero di iterazioni e il modello finale è un modello di insieme che utilizza la somma ponderata delle previsioni fatte da tutti gli alberi costruiti in precedenza.
Il processo sopra descritto utilizza gli alberi decisionali ei predittori / modelli di base, tuttavia è possibile eseguire un approccio di potenziamento con un’ampia gamma di modelli come i numerosi modelli standard di classificatore e regressore. I concetti chiave da comprendere sono che i predittori successivi apprendono dagli errori commessi da quelli precedenti e che i predittori vengono creati in sequenza.
Il vantaggio principale del potenziamento degli algoritmi è che impiegano meno tempo per trovare le previsioni correnti rispetto ad altri modelli di apprendimento automatico. Tuttavia, è necessario prestare attenzione quando si utilizzano algoritmi di boosting, poiché sono inclini all’overfitting.
Aumento gradiente
Vedremo ora uno degli algoritmi di boosting più comuni. I modelli Gradient Boosting (GBM) sono noti per la loro elevata precisione e aumentano i principi generali utilizzati in AdaBoost.
La differenza principale tra un modello di aumento del gradiente e AdaBoost è che i GBM utilizzano un metodo diverso per calcolare quali studenti stanno identificando erroneamente i punti dati. AdaBoost calcola dove un modello ha prestazioni inferiori esaminando i punti dati che sono fortemente ponderati. Nel frattempo, i GBM utilizzano i gradienti per determinare l’accuratezza degli studenti, applicando una funzione di perdita a un modello. Le funzioni di perdita sono un modo per misurare l’accuratezza dell’adattamento di un modello sul set di dati, calcolare un errore e ottimizzare il modello per ridurre tale errore. I GBM consentono all’utente di ottimizzare una funzione di perdita specifica in base all’obiettivo desiderato.
Prendendo come esempio la funzione di perdita più comune – Mean Squared Error (MSE) , la discesa del gradiente viene utilizzata per aggiornare le previsioni in base a un tasso di apprendimento predefinito, con l’obiettivo di trovare i valori in cui la perdita è minima.
Per renderlo più chiaro:
Previsioni del nuovo modello = variabili di output – vecchie previsioni imperfette.
In un senso più statistico, i GBM mirano a trovare modelli rilevanti nei residui di un modello, regolando il modello per adattarlo al modello e portare i residui il più vicino possibile allo zero. Se dovessi eseguire una regressione sulle previsioni del modello, i residui sarebbero distribuiti intorno a 0 (adattamento perfetto) e i GBM stanno trovando modelli all’interno dei residui e aggiornando il modello attorno a questi modelli.
In altre parole, le previsioni vengono aggiornate in modo che la somma di tutti i residui sia il più vicino possibile a 0, il che significa che i valori previsti saranno molto vicini ai valori effettivi.
Si noti che un’ampia varietà di altre funzioni di perdita (come la perdita logaritmica) può essere utilizzata da un GBM. MSE è stato selezionato sopra per motivi di semplicità.
Variazioni sui modelli di aumento del gradiente
I modelli di aumento del gradiente sono algoritmi avidi che sono inclini a overfitting su un set di dati. Questo può essere protetto con diversi metodi che possono migliorare le prestazioni di un GBM.
I GBM possono essere regolati con quattro diversi metodi: Shrinkage, Tree Constraints, Stochastic Gradient Boosting e Penalized Learning.
Restringimento
Come accennato in precedenza, nei GBM le previsioni vengono sommate in modo sequenziale. In “Restringimento” vengono regolate le aggiunte di ogni albero alla somma complessiva. Vengono applicati pesi che rallentano la velocità di apprendimento dell’algoritmo, rendendo necessaria l’aggiunta di più alberi al modello, il che in genere migliora la robustezza e le prestazioni del modello. Il compromesso è che il modello impiega più tempo per addestrarsi.
Vincoli dell’albero
Vincolare l’albero con varie modifiche come l’aggiunta di più profondità all’albero o l’aumento del numero di nodi o foglie nell’albero può rendere più difficile l’adattamento del modello. L’imposizione di un vincolo al numero minimo di osservazioni per divisione ha un effetto simile. Ancora una volta, il compromesso è che il modello impiegherà più tempo per addestrarsi.
Campionamento Casuale
I singoli studenti possono essere creati attraverso un processo stocastico, basato su sottocampioni selezionati casualmente del set di dati di formazione. Ciò ha l’effetto di ridurre le correlazioni tra gli alberi, che protegge dall’eccessivo adattamento. Il set di dati può essere sottocampionato prima di creare gli alberi o prima di considerare una divisione nell’albero.
Apprendimento penalizzato
Oltre a vincolare il modello limitando la struttura dell’albero, è possibile utilizzare un albero di regressione. Gli alberi di regressione hanno valori numerici associati a ciascuna delle foglie e questi funzionano come pesi e possono essere regolati con funzioni di regolarizzazione comuni come la regolarizzazione L1 e L2.