
Il recente successo dei modelli auto-supervisionati può essere attribuito al rinnovato interesse dei ricercatori nell’esplorazione dell’apprendimento contrastante, un paradigma dell’apprendimento auto-supervisionato. Ad esempio, gli umani possono identificare oggetti allo stato brado anche se non ricordiamo esattamente come si presenta l’oggetto.
Lo facciamo ricordando le funzionalità di alto livello e ignorando i dettagli a livello microscopico. Quindi, ora la domanda è: possiamo costruire algoritmi di apprendimento della rappresentazione che non si concentrano su dettagli a livello di pixel e codifichino solo funzioni di alto livello sufficienti a distinguere oggetti diversi? Con l’apprendimento contrastante, i ricercatori stanno cercando di affrontare questo problema.
Di recente, anche il SimCLR di Google ha dimostrato le implicazioni dell’apprendimento contrastivo, che vedremo brevemente alla fine di questo articolo.
Principio dell’apprendimento contrastivo
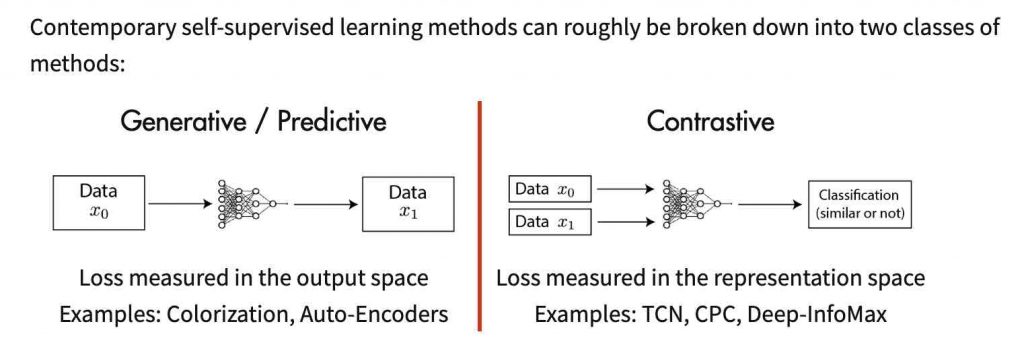
L’apprendimento contrastivo è un approccio per formulare il compito di trovare cose simili e dissimili per un modello ML. Utilizzando questo approccio, si può formare un modello di apprendimento automatico per classificare tra immagini simili e diverse.
Il funzionamento interno dell’apprendimento contrastivo può essere formulato come una funzione di punteggio, che è una metrica che misura la somiglianza tra due caratteristiche.
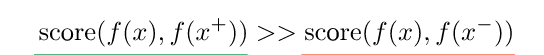
Qui
x + è un punto dati simile a x, indicato come campione positivo
x− è un punto dati diverso da x, indicato come campione negativo
Oltre a ciò, è possibile creare un classificatore softmax che classifica correttamente i campioni positivi e negativi. Un’applicazione simile di questa tecnica può essere trovata nel framework SimCLR recentemente introdotto .
Applicazione dell’apprendimento contrastivo

tramite Google AI
Google ha introdotto un framework chiamato “SimCLR” che utilizza l’apprendimento contrastante. Questo framework apprende innanzitutto rappresentazioni generiche di immagini su un set di dati senza etichetta e quindi viene perfezionato con un piccolo set di dati di immagini etichettate per un determinato compito di classificazione.
Le rappresentazioni di base vengono apprese massimizzando simultaneamente l’accordo tra diverse versioni o viste della stessa immagine e riducendo la differenza utilizzando l’apprendimento contrastivo.
Quando i parametri di una rete neurale vengono aggiornati usando questo obiettivo contrastante, le rappresentazioni delle viste corrispondenti si “attirano” a vicenda, mentre le rappresentazioni delle viste non corrispondenti si “respingono”.
In questo blog è stata fornita una spiegazione più dettagliata del documento originale .
La procedura è la seguente:
Innanzitutto, genera lotti di una determinata dimensione, ad esempio N dalle immagini grezze
Per ogni immagine in questo batch, viene applicata una funzione di trasformazione casuale per ottenere una coppia di due immagini
Ogni immagine aumentata in una coppia viene passata attraverso un codificatore per ottenere rappresentazioni di immagine.
Le rappresentazioni delle due immagini aumentate vengono quindi fatte passare attraverso uno strato denso non lineare seguito da una ReLU, a cui fa seguito un altro strato denso. Queste immagini vengono passate su una serie di questi livelli per applicare una trasformazione non lineare e proiettarla in una rappresentazione
Per ogni immagine aumentata nel batch, ottieni un vettore di incorporamento.
Ora, la somiglianza tra due versioni aumentate di un’immagine viene calcolata usando la somiglianza del coseno. SimCLR utilizza la “perdita NT-Xent” (perdita di entropia incrociata in scala di temperatura normalizzata), nota come perdita contrastante.

Innanzitutto, le coppie aumentate nel batch vengono prese una per una. Successivamente viene applicata una funzione softmax per trovare la probabilità che queste due immagini siano simili.
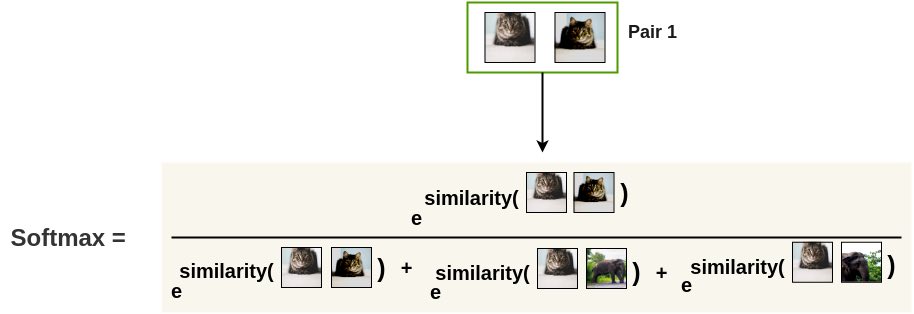
Come mostrato sopra, la funzione softmax può essere utilizzata per calcolare quanto sono simili le due immagini di gatto aumentato e tutte le immagini rimanenti nel batch vengono campionate come immagini diverse (coppia negativa).
In base alla perdita, le rappresentazioni dell’encoder e della testa di proiezione migliorano nel tempo e le rappresentazioni ottenute posizionano immagini simili più vicine nello spazio.
I risultati di SimCLR hanno dimostrato che ha sovraperformato i precedenti metodi auto-supervisionati su ImageNet.
Per saperne di più su questo argomento, controlla questo e questo .