Una delle sfide chiave del machine learning è la necessità di grandi quantità di dati. La raccolta di set di dati di addestramento per i modelli di apprendimento automatico comporta rischi per la privacy, la sicurezza e l’elaborazione che le organizzazioni preferirebbero evitare.
Una tecnica che può aiutare ad affrontare alcune di queste sfide è “l’ apprendimento federato “. Distribuendo l’addestramento dei modelli tra i dispositivi degli utenti, l’apprendimento federato consente di sfruttare l’apprendimento automatico riducendo al minimo la necessità di raccogliere i dati degli utenti.
Apprendimento automatico basato su cloud
Il processo tradizionale per lo sviluppo di applicazioni di apprendimento automatico consiste nel raccogliere un grande set di dati, addestrare un modello sui dati ed eseguire il modello addestrato su un server cloud che gli utenti possono raggiungere tramite diverse applicazioni come ricerca web, traduzione, generazione di testo e immagini elaborazione .
Ogni volta che l’applicazione desidera utilizzare il modello di apprendimento automatico, deve inviare i dati dell’utente al server in cui risiede il modello.
In molti casi, l’invio di dati al server è inevitabile. Ad esempio, questo paradigma è inevitabile per i sistemi di raccomandazione dei contenuti perché parte dei dati e dei contenuti necessari per l’inferenza del machine learning risiede sul server cloud.
Ma in applicazioni come il completamento automatico del testo o il riconoscimento facciale, i dati sono locali per l’utente e il dispositivo. In questi casi, sarebbe preferibile che i dati rimangano sul dispositivo dell’utente anziché essere inviati al cloud.
Fortunatamente, i progressi nell’intelligenza artificiale perimetrale hanno permesso di evitare l’invio di dati utente sensibili ai server delle applicazioni. Conosciuto anche come TinyML , questa è un’area di ricerca attiva e cerca di creare modelli di apprendimento automatico che si adattano a smartphone e altri dispositivi degli utenti. Questi modelli consentono di eseguire l’inferenza sul dispositivo. Le grandi aziende tecnologiche stanno cercando di portare alcune delle loro applicazioni di apprendimento automatico sui dispositivi degli utenti per migliorare la privacy.
L’apprendimento automatico su dispositivo ha diversi vantaggi aggiuntivi. Queste applicazioni possono continuare a funzionare anche quando il dispositivo non è connesso a Internet. Offrono inoltre il vantaggio di risparmiare larghezza di banda quando gli utenti utilizzano connessioni a consumo. E in molte applicazioni, l’inferenza sul dispositivo è più efficiente dal punto di vista energetico rispetto all’invio di dati al cloud.
Formazione di modelli di machine learning su dispositivo
L’inferenza sul dispositivo è un importante aggiornamento della privacy per le applicazioni di apprendimento automatico. Ma rimane una sfida: gli sviluppatori hanno ancora bisogno di dati per addestrare i modelli che spingeranno sui dispositivi degli utenti. Ciò non rappresenta un problema quando l’organizzazione che sviluppa i modelli possiede già i dati (ad esempio, una banca possiede le sue transazioni) o i dati sono di dominio pubblico (ad esempio, Wikipedia o articoli di notizie).
Ma se un’azienda desidera addestrare modelli di apprendimento automatico che coinvolgono informazioni riservate dell’utente come e-mail, registri di chat o foto personali, la raccolta di dati di formazione comporta molte sfide. L’azienda dovrà assicurarsi che la sua politica di raccolta e conservazione sia conforme alle varie normative sulla protezione dei dati e sia anonimizzata per rimuovere le informazioni di identificazione personale (PII).
Una volta addestrato il modello di machine learning, il team di sviluppatori deve prendere decisioni in merito alla conservazione o all’eliminazione dei dati di addestramento. Dovranno inoltre disporre di una politica e di una procedura per continuare a raccogliere dati dagli utenti per riqualificare e aggiornare regolarmente i loro modelli.
Questo è il problema degli indirizzi di apprendimento federato.
Apprendimento federato
L’idea principale alla base dell’apprendimento federato è quella di addestrare un modello di apprendimento automatico sui dati degli utenti senza la necessità di trasferire tali dati ai server cloud .
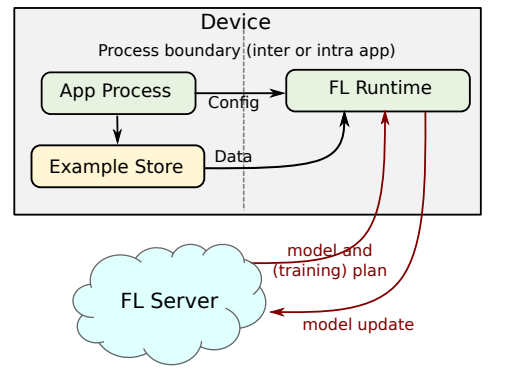
L’apprendimento federato inizia con un modello di apprendimento automatico di base nel server cloud. Questo modello è addestrato su dati pubblici (ad esempio, articoli di Wikipedia o il set di dati ImageNet) o non è stato addestrato affatto.
Nella fase successiva, diversi dispositivi utente si offrono volontari per addestrare il modello. Questi dispositivi conservano i dati dell’utente rilevanti per l’applicazione del modello, come i registri delle chat e le sequenze di tasti.
Questi dispositivi scaricano il modello base in un momento opportuno, ad esempio quando si trovano su una rete Wi-Fi e sono collegati a una presa di corrente (l’addestramento è un’operazione ad alta intensità di calcolo e scaricherà la batteria del dispositivo se eseguita in un momento improprio) . Quindi addestrano il modello sui dati locali del dispositivo.
Dopo l’addestramento, restituiscono il modello addestrato al server. Gli algoritmi di apprendimento automatico più diffusi come le reti neurali profonde e le macchine vettoriali di supporto sono parametrici. Una volta addestrati, codificano i modelli statistici dei loro dati in parametri numerici e non hanno più bisogno dei dati di addestramento per l’inferenza. Pertanto, quando il dispositivo invia il modello addestrato al server, non contiene dati utente non elaborati.
Una volta che il server riceve i dati dai dispositivi dell’utente, aggiorna il modello di base con i valori dei parametri aggregati dei modelli addestrati dall’utente.
Il ciclo di apprendimento federato deve essere ripetuto più volte prima che il modello raggiunga il livello di accuratezza ottimale desiderato dagli sviluppatori. Una volta che il modello finale è pronto, può essere distribuito a tutti gli utenti per l’inferenza sul dispositivo.
Limiti dell’apprendimento federato
L’apprendimento federato non si applica a tutte le applicazioni di apprendimento automatico. Se il modello è troppo grande per essere eseguito sui dispositivi degli utenti, lo sviluppatore dovrà trovare altre soluzioni alternative per preservare la privacy dell’utente.
D’altra parte, gli sviluppatori devono assicurarsi che i dati sui dispositivi degli utenti siano rilevanti per l’applicazione. Il tradizionale ciclo di sviluppo dell’apprendimento automatico prevede pratiche intensive di pulizia dei dati in cui gli ingegneri dei dati rimuovono i punti dati fuorvianti e colmano le lacune in cui i dati mancano. Addestrare modelli di machine learning su dati irrilevanti può fare più male che bene.
Quando i dati di addestramento si trovano sul dispositivo dell’utente, i tecnici dei dati non hanno modo di valutare i dati e assicurarsi che siano vantaggiosi per l’applicazione. Per questo motivo, l’apprendimento federato deve essere limitato alle applicazioni in cui i dati dell’utente non necessitano di preelaborazione.
Un altro limite del machine learning federato è l’etichettatura dei dati. La maggior parte dei modelli di machine learning è supervisionata , il che significa che richiedono esempi di addestramento etichettati manualmente da annotatori umani. Ad esempio, il set di dati ImageNet è un repository crowdsourcing che contiene milioni di immagini e le loro classi corrispondenti.
Nell’apprendimento federato, a meno che i risultati non possano essere dedotti dalle interazioni dell’utente (ad esempio, prevedendo la parola successiva che l’utente sta digitando), gli sviluppatori non possono aspettarsi che gli utenti facciano di tutto per etichettare i dati di addestramento per il modello di apprendimento automatico. L’apprendimento federato è più adatto per applicazioni di apprendimento non supervisionato come la modellazione linguistica.
Implicazioni sulla privacy dell’apprendimento federato
Sebbene l’invio di parametri del modello addestrato al server sia meno sensibile alla privacy rispetto all’invio di dati utente, ciò non significa che i parametri del modello siano completamente privi di dati privati.
In effetti, molti esperimenti hanno dimostrato che i modelli di apprendimento automatico addestrati potrebbero memorizzare i dati degli utenti e gli attacchi di inferenza dell’appartenenza possono ricreare i dati di addestramento in alcuni modelli attraverso tentativi ed errori.
Un importante rimedio alle preoccupazioni sulla privacy dell’apprendimento federato consiste nell’eliminare i modelli addestrati dall’utente dopo che sono stati integrati nel modello centrale. Il server cloud non ha bisogno di memorizzare singoli modelli una volta aggiornato il modello di base.
Un’altra misura che può aiutare è aumentare il pool di formatori modello. Ad esempio, se un modello deve essere addestrato sui dati di 100 utenti, gli ingegneri possono aumentare il proprio pool di formatori a 250 o 500 utenti. Per ogni iterazione di addestramento, il sistema invierà il modello base a 100 utenti casuali dal pool di addestramento. In questo modo, il sistema non raccoglie costantemente parametri addestrati da un singolo utente.
Infine, aggiungendo un po’ di rumore ai parametri addestrati e utilizzando tecniche di normalizzazione, gli sviluppatori possono ridurre considerevolmente la capacità del modello di memorizzare i dati degli utenti.
L’apprendimento federato sta guadagnando popolarità poiché affronta alcuni dei problemi fondamentali della moderna intelligenza artificiale. I ricercatori sono costantemente alla ricerca di nuovi modi per applicare l’apprendimento federato a nuove applicazioni di intelligenza artificiale e superarne i limiti. Sarà interessante vedere come si evolverà il campo in futuro.