Il ricercatore di Google Gaurav Menghani ha proposto un metodo per rendere “i modelli di deep learning più piccoli, più veloci e migliori”.
L’apprendimento profondo ha ampie applicazioni nell’analisi del sentimento, nella comprensione del linguaggio naturale, nella visione artificiale, ecc. La tecnologia sta crescendo a una velocità vertiginosa grazie alla rapida innovazione. Tuttavia, tali innovazioni richiedono un numero maggiore di parametri e risorse. In altre parole, il modello è buono quanto le metriche.
A tal fine, il ricercatore di Google Gaurav Menghani ha pubblicato un documento sull’efficienza del modello. L’indagine copre il panorama dell’efficienza dei modelli, dalle tecniche di modellazione al supporto hardware. Ha proposto un metodo per rendere “i modelli di deep learning più piccoli, più veloci e migliori”.
Sfide
Menghani sostiene che mentre i modelli più grandi e complicati si comportano bene nei compiti su cui sono addestrati, potrebbero non mostrare le stesse prestazioni se applicati a situazioni di vita reale.
Di seguito sono riportate le sfide che i professionisti affrontano durante la formazione e l’implementazione dei modelli:
Il costo della formazione e dell’implementazione di modelli di deep learning di grandi dimensioni è elevato. I modelli di grandi dimensioni richiedono molta memoria e lasciano un’impronta di carbonio maggiore.
Alcune applicazioni di deep learning devono essere eseguite in tempo reale su IoT e dispositivi intelligenti. Ciò richiede l’ottimizzazione dei modelli per dispositivi specifici.
Creazione di modelli di addestramento con il minor numero di dati possibile quando i dati dell’utente potrebbero essere sensibili.
I modelli standard potrebbero non essere sempre in grado di affrontare i vincoli delle nuove applicazioni.
L’addestramento e l’implementazione di più modelli sulla stessa infrastruttura per applicazioni diverse possono esaurire le risorse disponibili.
Un modello mentale
Menghani presenta un modello mentale completo di algoritmi, tecniche e strumenti per un deep learning efficiente . Ha cinque aree principali: tecniche di compressione, tecniche di apprendimento, automazione, architetture efficienti e infrastruttura (hardware).

Modello mentale
Tecniche di compressione : questi algoritmi e tecniche ottimizzano l’architettura del modello, tipicamente comprimendone i livelli. Uno degli esempi più popolari di tecnica di compressione è la quantizzazione, in cui il peso di uno strato viene compresso riducendone la precisione con una perdita minima di qualità.
Tecniche di apprendimento : questi algoritmi sono focalizzati sull’addestramento del modello per fare meno errori di previsione, richiedere meno dati e convergere più velocemente. Offre inoltre la possibilità di tagliare i parametri per ottenere un ingombro ridotto o un modello più efficiente. Un esempio di ciò è la distillazione che consente di migliorare l’accuratezza di un modello più piccolo insegnandogli a imitarne uno più grande.
Automazione : aiuta a migliorare le metriche principali di un determinato modello. L’ottimizzazione degli iperparametri (HPO) è un esempio di uno strumento di automazione in cui l’ottimizzazione degli iperparametri aumenta la precisione. Un’altra tecnica è la ricerca dell’architettura, in cui l’architettura del modello viene ottimizzata e la ricerca aiuta a trovare un modello che ottimizzi sia la perdita che l’accuratezza.
Architetture efficienti : questi sono blocchi fondamentali progettati da zero. Tali modelli sono superiori ai metodi di base come i livelli connessi e completamente connessi e gli RNN.
Infrastrutture : la costruzione di un modello efficiente richiede anche una solida base di infrastrutture e strumenti. Include framework di training modello come TensorFlow, PyTorch, ecc.
Guida all’efficienza
Menghani ha affermato che l’obiettivo finale è costruire modelli Pareto-ottimali. Efficienza paretiana significa che le risorse sono allocate nel modo economicamente più efficiente. Per costruire modelli Pareto-ottimali , i professionisti devono ottenere il miglior risultato possibile in una dimensione mantenendo l’altra costante. In genere, una di queste dimensioni è la qualità (metriche come accuratezza, precisione e richiamo) e l’altra è il footprint (metriche come dimensione del modello, latenza, RAM)
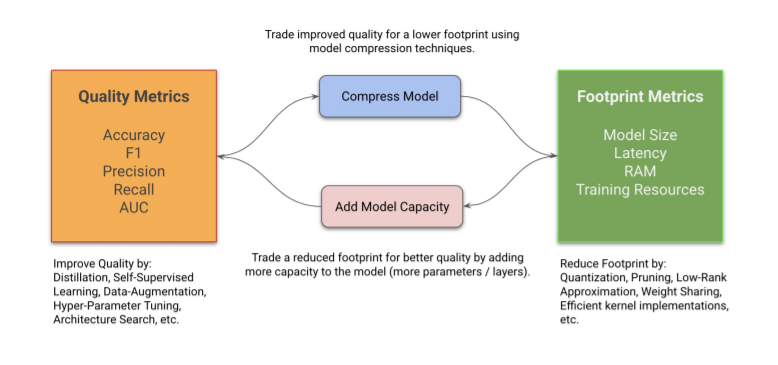
Suggerisce due metodi per ottenere il modello Pareto-ottimale:
Riduci e migliora i modelli sensibili all’impronta : questa è una strategia utile per i professionisti che desiderano ridurre l’impronta del modello senza compromettere la qualità. La riduzione può essere utile per la distribuzione sul dispositivo e l’ ottimizzazione lato server . Idealmente, dovrebbe avere una perdita minima, ma in alcuni casi la riduzione della capacità può essere compensata dalla fase di miglioramento.
Cresci, migliora e riduci per modelli sensibili alla qualità : questa strategia può essere utilizzata quando un professionista desidera implementare modelli di qualità migliore mantenendo lo stesso footprint. Qui la capacità viene prima aggiunta facendo crescere il modello e poi migliorata tramite tecniche di apprendimento , automazione ecc; posta questo, il modello è ristretto.