Se hai letto in passato di tecniche di apprendimento senza supervisione , potresti aver trovato il termine ” autoencoder “. Gli autoencoder sono uno dei modi principali in cui vengono sviluppati modelli di apprendimento non supervisionato . Ma cos’è esattamente un autoencoder?
In breve, gli autoencoder funzionano prendendo i dati, comprimendo e codificando i dati, quindi ricostruendo i dati dalla rappresentazione della codifica. Il modello viene addestrato finché la perdita non viene ridotta al minimo e i dati vengono riprodotti il più fedelmente possibile. Attraverso questo processo, un autoencoder può apprendere le caratteristiche importanti dei dati. Sebbene questa sia una rapida definizione di un autoencoder, sarebbe utile dare un’occhiata più da vicino agli autoencoder e ottenere una migliore comprensione di come funzionano. Questo articolo tenterà di demistificare gli autoencoder, spiegando l’architettura degli autoencoder e le loro applicazioni.
Cos’è un Autoencoder?
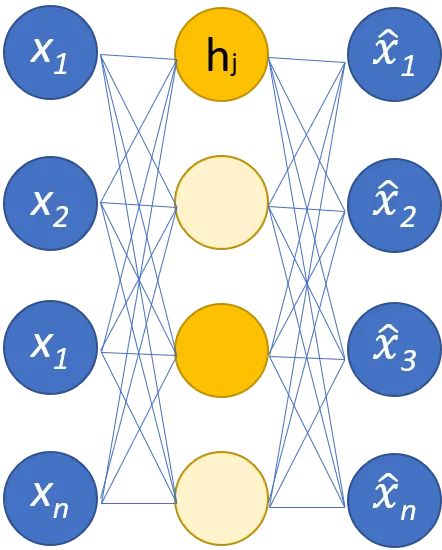
Gli autoencoder sono reti neurali. Le reti neurali sono composte da più livelli e l’aspetto che definisce un autoencoder è che i livelli di input contengono esattamente la stessa quantità di informazioni del livello di output. Il motivo per cui il livello di input e il livello di output hanno lo stesso numero di unità è che un autoencoder mira a replicare i dati di input. Emette una copia dei dati dopo averli analizzati e ricostruiti senza supervisione.
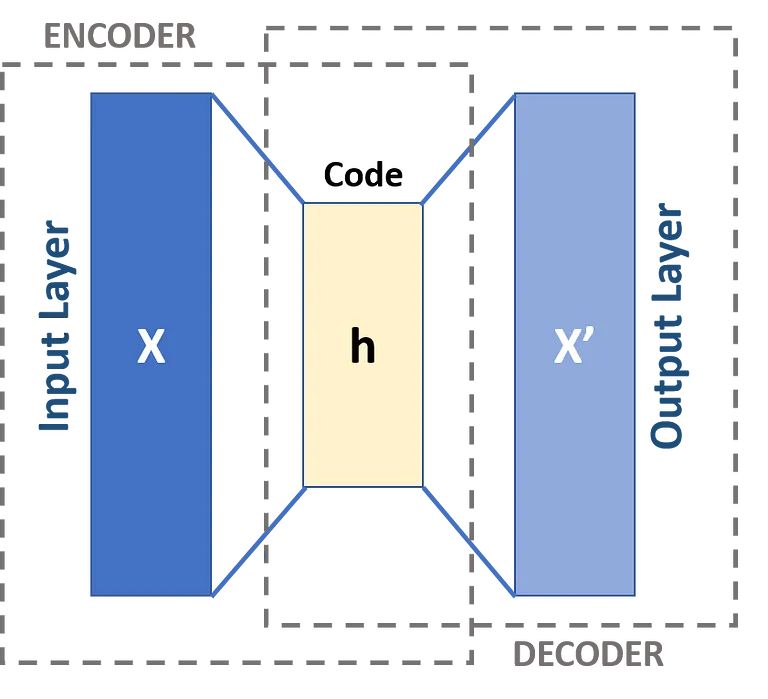
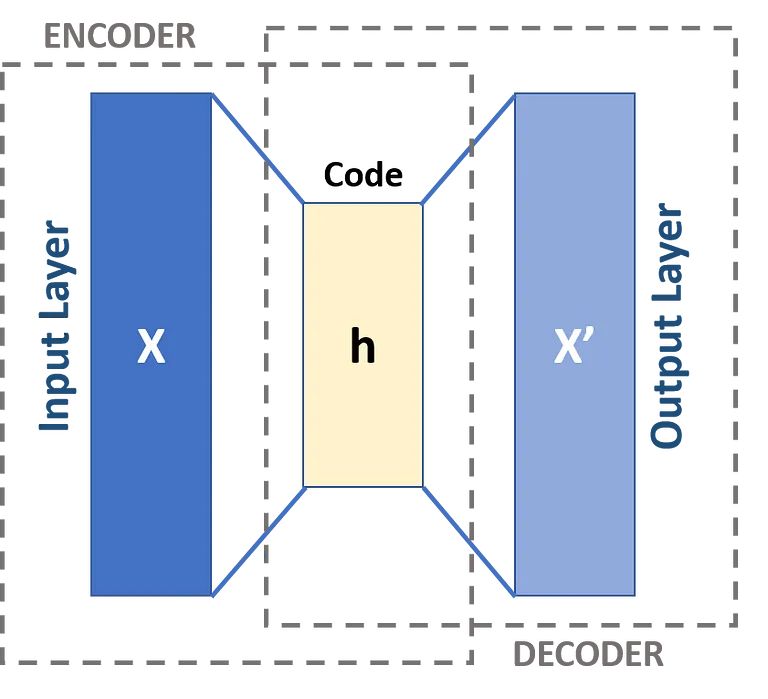
I dati che si muovono attraverso un autoencoder non vengono mappati direttamente dall’input all’output, il che significa che la rete non si limita a copiare i dati di input. Ci sono tre componenti in un autoencoder: una parte di codifica (input) che comprime i dati, un componente che gestisce i dati compressi (o collo di bottiglia) e una parte decoder (output). Quando i dati vengono inseriti in un codificatore automatico, vengono codificati e quindi compressi in una dimensione inferiore. La rete viene quindi addestrata sui dati codificati / compressi e produce una ricreazione di quei dati.
Allora perché dovresti voler addestrare una rete per ricostruire solo i dati che le vengono forniti? Il motivo è che la rete apprende l ‘”essenza” o le caratteristiche più importanti dei dati di input. Dopo aver addestrato la rete, è possibile creare un modello in grado di sintetizzare dati simili, con l’aggiunta o la sottrazione di determinate caratteristiche di destinazione. Ad esempio, è possibile addestrare un codificatore automatico su immagini sgranate e quindi utilizzare il modello addestrato per rimuovere la grana / rumore dall’immagine.
Architettura Autoencoder
Diamo un’occhiata all’architettura di un autoencoder. Discuteremo qui l’architettura principale di un autoencoder. Ci sono variazioni su questa architettura generale che discuteremo nella sezione seguente.
Come accennato in precedenza, un autoencoder può essere essenzialmente suddiviso in tre diversi componenti: l’encoder, un collo di bottiglia e il decoder.
La parte codificatore dell’autoencoder è tipicamente una rete feedforward densamente connessa. Lo scopo degli strati di codifica è quello di prendere i dati di input e comprimerli in una rappresentazione di spazio latente, generando una nuova rappresentazione dei dati che ha una dimensionalità ridotta.
I livelli di codice, o il collo di bottiglia, si occupano della rappresentazione compressa dei dati. Il codice del collo di bottiglia è progettato con cura per determinare le parti più rilevanti dei dati osservati, o per mettere in un altro modo le caratteristiche dei dati che sono più importanti per la ricostruzione dei dati. L’obiettivo qui è determinare quali aspetti dei dati devono essere preservati e quali possono essere scartati. Il codice del collo di bottiglia deve bilanciare due diverse considerazioni: dimensione della rappresentazione (quanto è compatta la rappresentazione) e rilevanza della variabile / caratteristica. Il collo di bottiglia esegue un’attivazione basata sugli elementi sui pesi e sui pregiudizi della rete. Il livello del collo di bottiglia è talvolta chiamato anche rappresentazione latente o variabili latenti.
Il livello del decodificatore è ciò che è responsabile di prendere i dati compressi e riconvertirli in una rappresentazione con le stesse dimensioni dei dati originali e inalterati. La conversione viene eseguita con la rappresentazione dello spazio latente creata dall’encoder.
L’architettura di base di un autoencoder è un’architettura feed-forward, con una struttura molto simile a un perceptron a strato singolo utilizzato nei perceptron multistrato. Proprio come le normali reti neurali feed-forward, l’auto-codificatore viene addestrato attraverso l’uso della backpropagation.
Attributi di un Autoencoder
Esistono vari tipi di autoencoder, ma tutti hanno determinate proprietà che li uniscono.
Gli autoencoder apprendono automaticamente. Non richiedono etichette e, se vengono forniti dati sufficienti, è facile ottenere un autoencoder per raggiungere prestazioni elevate su un tipo specifico di dati di input.
Gli autoencoder sono specifici dei dati. Ciò significa che possono comprimere solo dati molto simili ai dati su cui l’autoencoder è già stato addestrato. Anche gli autoencoder sono lossy, il che significa che gli output del modello saranno degradati rispetto ai dati di input.
Quando si progetta un autoencoder, gli ingegneri del machine learning devono prestare attenzione a quattro diversi iperparametri del modello: dimensione del codice, numero di livello, nodi per livello e funzione di perdita.
La dimensione del codice decide quanti nodi iniziano la parte centrale della rete e meno nodi comprimono maggiormente i dati. In un autoencoder profondo, mentre il numero di livelli può essere qualsiasi numero ritenuto appropriato dall’ingegnere, il numero di nodi in un livello dovrebbe diminuire man mano che l’encoder va avanti. Nel frattempo, vale l’opposto nel decodificatore, il che significa che il numero di nodi per strato dovrebbe aumentare man mano che gli strati del decodificatore si avvicinano allo strato finale. Infine, la funzione di perdita di un autoencoder è tipicamente o entropia incrociata binaria o errore quadratico medio. L’entropia incrociata binaria è appropriata per i casi in cui i valori di input dei dati sono in un intervallo 0 – 1.
Tipi di autoencoder
Come accennato in precedenza, esistono variazioni sulla classica architettura dell’autoencoder. Esaminiamo le diverse architetture di autoencoder.
Mentre gli autoencoder in genere hanno un collo di bottiglia che comprime i dati attraverso una riduzione dei nodi, gli autoencoder sparsi sono un’alternativa a quel tipico formato operativo. In una rete sparsa, i livelli nascosti mantengono le stesse dimensioni dei livelli del codificatore e del decodificatore. Vengono invece penalizzate le attivazioni all’interno di un dato layer, impostandolo in modo che la funzione di perdita catturi meglio le caratteristiche statistiche dei dati di input. Per dirla in un altro modo, mentre gli strati nascosti di un autoencoder sparso hanno più unità di un autoencoder tradizionale, solo una certa percentuale di esse è attiva in un dato momento. Le funzioni di attivazione di maggior impatto vengono preservate e altre vengono ignorate e questo vincolo aiuta la rete a determinare solo le caratteristiche più salienti dei dati di input.
Contrattivo
Gli autoencoder contrattuali sono progettati per resistere a piccole variazioni nei dati, mantenendo una rappresentazione coerente dei dati. Ciò si ottiene applicando una penalità alla funzione di perdita. Questa tecnica di regolarizzazione si basa sulla norma Frobenius della matrice Jacobiana per le attivazioni dell’encoder in ingresso. L’effetto di questa tecnica di regolarizzazione è che il modello è costretto a costruire una codifica in cui input simili avranno codifiche simili.
Convoluzionale
Gli autoencoder convoluzionali codificano i dati di input suddividendo i dati in sottosezioni e quindi convertendo queste sottosezioni in semplici segnali che vengono sommati per creare una nuova rappresentazione dei dati. Simile alle reti neurali di convoluzione, un autoencoder convoluzionale è specializzato nell’apprendimento dei dati di immagine e utilizza un filtro che viene spostato attraverso l’intera immagine sezione per sezione. Le codifiche generate dal livello di codifica possono essere utilizzate per ricostruire l’immagine, riflettere l’immagine o modificare la geometria dell’immagine. Una volta che i filtri sono stati appresi dalla rete, possono essere utilizzati su qualsiasi input sufficientemente simile per estrarre le caratteristiche dell’immagine.
Denoising
Gli autoencoder di denoising introducono rumore nella codifica, risultando in una codifica che è una versione danneggiata dei dati di input originali. Questa versione danneggiata dei dati viene utilizzata per addestrare il modello, ma la funzione di perdita confronta i valori di output con l’input originale e non con l’input danneggiato. L’obiettivo è che la rete sia in grado di riprodurre la versione originale e non danneggiata dell’immagine. Confrontando i dati danneggiati con i dati originali, la rete apprende quali caratteristiche dei dati sono più importanti e quali sono non importanti / corruzioni. In altre parole, affinché un modello possa effettuare il denoising delle immagini danneggiate, deve aver estratto le caratteristiche importanti dei dati dell’immagine.
Variazionale
Gli autoencoder variazionali operano facendo ipotesi su come vengono distribuite le variabili latenti dei dati. Un autoencoder variazionale produce una distribuzione di probabilità per le diverse caratteristiche delle immagini di addestramento / degli attributi latenti. Durante l’addestramento, il codificatore crea distribuzioni latenti per le diverse funzionalità delle immagini di input.
Poiché il modello apprende le caratteristiche o le immagini come distribuzioni gaussiane invece di valori discreti, è in grado di essere utilizzato per generare nuove immagini. La distribuzione gaussiana viene campionata per creare un vettore, che viene immesso nella rete di decodifica, che restituisce un’immagine basata su questo vettore di campioni. In sostanza, il modello apprende le caratteristiche comuni delle immagini di addestramento e assegna loro una certa probabilità che si verifichino. La distribuzione di probabilità può quindi essere utilizzata per decodificare un’immagine, generando nuove immagini che assomigliano alle immagini originali di addestramento.
Durante il training della rete, i dati codificati vengono analizzati e il modello di riconoscimento emette due vettori, disegnando la media e la deviazione standard delle immagini. Viene creata una distribuzione in base a questi valori. Questo viene fatto per i diversi stati latenti. Il decodificatore quindi prende campioni casuali dalla distribuzione corrispondente e li utilizza per ricostruire gli input iniziali alla rete.
Applicazioni Autoencoder
Gli autoencoder possono essere utilizzati per un’ampia varietà di applicazioni , ma in genere vengono utilizzati per attività come la riduzione della dimensionalità, l’ eliminazione del rumore dei dati, l’estrazione di funzionalità, la generazione di immagini, la previsione da sequenza a sequenza e sistemi di raccomandazione.
Il denoising dei dati è l’uso di autoencoder per eliminare granulosità / rumore dalle immagini. Allo stesso modo, gli autoencoder possono essere utilizzati per riparare altri tipi di danni alle immagini, come immagini sfocate o sezioni mancanti di immagini. La riduzione della dimensionalità può aiutare le reti ad alta capacità ad apprendere caratteristiche utili delle immagini, il che significa che gli autoencoder possono essere utilizzati per aumentare la formazione di altri tipi di reti neurali. Questo vale anche per l’utilizzo di autoencoder per l’estrazione di funzionalità, poiché gli autoencoder possono essere utilizzati per identificare le funzionalità di altri set di dati di addestramento per addestrare altri modelli.
In termini di generazione di immagini, gli autoencoder possono essere utilizzati per generare false immagini umane o personaggi animati, che ha applicazioni nella progettazione di sistemi di riconoscimento facciale o nell’automazione di alcuni aspetti dell’animazione.
I modelli di previsione da sequenza a sequenza possono essere utilizzati per determinare la struttura temporale dei dati, il che significa che un autoencoder può essere utilizzato per generare il successivo anche in una sequenza. Per questo motivo, un autoencoder potrebbe essere utilizzato per generare video. Infine, gli autoencoder profondi possono essere utilizzati per creare sistemi di raccomandazione rilevando modelli relativi all’interesse dell’utente, con il codificatore che analizza i dati di coinvolgimento dell’utente e il decodificatore che crea raccomandazioni che si adattano ai modelli stabiliti.