Definizione di modelli generativi e GANL’architettura GANProcesso di formazione GANApplicazioni GAN
I GAN (Generative Adversarial Network) sono tipi di architetture di reti neurali in grado di generare nuovi dati conformi ai modelli appresi. I GAN possono essere utilizzati per generare immagini di volti umani o altri oggetti, per eseguire la traduzione da testo a immagine, per convertire un tipo di immagine in un altro e per migliorare la risoluzione delle immagini (super risoluzione) tra le altre applicazioni. Poiché i GAN possono generare dati completamente nuovi, sono a capo di molti sistemi, applicazioni e ricerche di IA all’avanguardia. Ma come funzionano esattamente i GAN? Esploriamo come funzionano i GAN e diamo uno sguardo ad alcuni dei loro usi principali.
Definizione di modelli generativi e GAN
Un GAN è un esempio di un modello generativo. La maggior parte dei modelli di intelligenza artificiale può essere suddivisa in una delle due categorie: modelli supervisionati e non supervisionati. I modelli di apprendimento supervisionato vengono tipicamente utilizzati per discriminare tra diverse categorie di input, per classificare. Al contrario, i modelli non supervisionati vengono generalmente utilizzati per riassumere la distribuzione dei dati, spesso apprendendo una distribuzione gaussiana dei dati. Poiché apprendono la distribuzione di un set di dati, possono estrarre campioni da questa distribuzione appresa e generare nuovi dati.
Diversi modelli generativi hanno metodi diversi per generare dati e calcolare le distribuzioni di probabilità. Ad esempio, il modello Naive Bayes funziona calcolando una distribuzione di probabilità per le varie caratteristiche di input e la classe generativa. Quando il modello Naive Bayes esegue il rendering di una previsione, calcola la classe più probabile prendendo la probabilità delle diverse variabili e combinandole insieme. Altri modelli generativi di apprendimento non profondo includono Gaussian Mixture Models e Latent Dirichlet Allocation (LDA). I modelli generativi basati su una profonda inclinazione includono Restricted Boltzmann Machines (RBM) , Variational Autoencoder (VAE) e, naturalmente, GAN.
I Generative Adversarial Network sono stati proposti per la prima volta da Ian Goodfellow nel 2014 e sono stati migliorati da Alec Redford e altri ricercatori nel 2015, portando a un’architettura standardizzata per i GAN. I GAN sono in realtà due reti diverse unite insieme. I GAN sono composti da due metà: un modello di generazione e un modello di discriminazione, noto anche come generatore e discriminatore.
L’architettura GAN
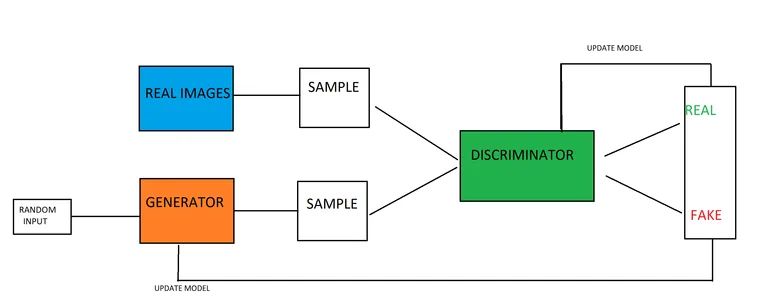
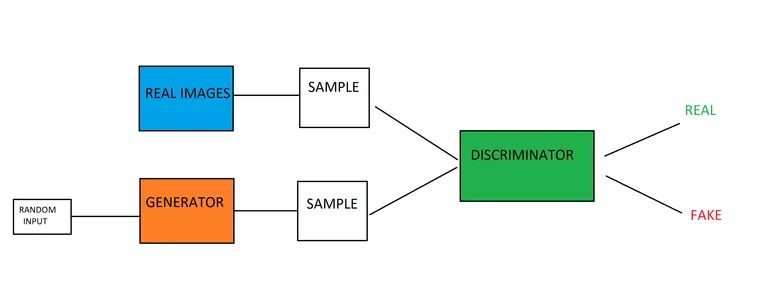
Le reti generative antagoniste sono costruite da un modello generatore e un modello discriminatore messi insieme. Il compito del modello generatore è creare nuovi esempi di dati, basati sui modelli che il modello ha appreso dai dati di addestramento. Il lavoro del modello discriminatore è analizzare le immagini (supponendo che sia addestrato sulle immagini) e determinare se le immagini sono generate / false o autentiche.
I due modelli sono messi l’uno contro l’altro, addestrati in modo teorico del gioco. L’obiettivo del modello generatore è produrre immagini che ingannino il suo avversario: il modello discriminatore. Nel frattempo, il compito del modello discriminatore è quello di superare il suo avversario, il modello generatore, e catturare le immagini false che il generatore produce. Il fatto che i modelli siano messi l’uno contro l’altro si traduce in una corsa agli armamenti in cui entrambi i modelli migliorano. Il discriminatore ottiene un feedback su quali immagini erano autentiche e quali immagini sono state prodotte dal generatore, mentre il generatore riceve informazioni su quali delle sue immagini sono state contrassegnate come false dal discriminatore. Entrambi i modelli migliorano durante l’addestramento, con l’obiettivo di addestrare un modello di generazione in grado di produrre dati falsi che sono fondamentalmente indistinguibili da dati reali e genuini.
Una volta creata una distribuzione gaussiana dei dati durante l’addestramento, è possibile utilizzare il modello generativo. Il modello generatore è inizialmente alimentato da un vettore casuale, che trasforma in base alla distribuzione gaussiana. In altre parole, il vettore semina la generazione. Quando il modello viene addestrato, lo spazio vettoriale sarà una versione compressa, o rappresentazione, della distribuzione gaussiana dei dati. La versione compressa della distribuzione dei dati viene definita spazio latente o variabili latenti. Successivamente, il modello GAN può quindi prendere la rappresentazione dello spazio latente e trarne dei punti, che possono essere dati al modello di generazione e utilizzati per generare nuovi dati molto simili ai dati di addestramento.
Il modello discriminatore è alimentato da esempi dell’intero dominio di addestramento, che è costituito da esempi di dati sia reali che generati. Gli esempi reali sono contenuti all’interno del set di dati di addestramento, mentre i dati falsi sono prodotti dal modello generativo. Il processo di addestramento del modello discriminatore è esattamente lo stesso dell’addestramento di base del modello di classificazione binaria.
Processo di formazione GAN
Diamo un’occhiata all’intero processo di formazione per un’ipotetica attività di generazione di immagini.
Per cominciare, il GAN viene addestrato utilizzando immagini autentiche e reali come parte del set di dati di addestramento. Questo imposta il modello discriminatore per distinguere tra immagini generate e immagini reali. Produce anche la distribuzione dei dati che il generatore utilizzerà per produrre nuovi dati.
Il generatore acquisisce un vettore di dati numerici casuali e li trasforma in base alla distribuzione gaussiana, restituendo un’immagine. Queste immagini generate, insieme ad alcune immagini autentiche dal set di dati di addestramento, vengono inserite nel modello discriminatore. Il discriminatore renderà una previsione probabilistica sulla natura delle immagini che riceve, fornendo un valore compreso tra 0 e 1, dove 1 è tipicamente immagini autentiche e 0 è un’immagine falsa.
C’è un doppio ciclo di feedback in gioco, poiché il discriminatore di terra è alimentato dalla verità di base delle immagini, mentre il generatore riceve un feedback sulle sue prestazioni dal discriminatore.
I modelli generativo e discriminatorio giocano tra loro a somma zero. Un gioco a somma zero è quello in cui i guadagni di una parte vengono a scapito dell’altra parte (la somma di entrambe le azioni è zero ex). Quando il modello discriminatore è in grado di distinguere con successo tra esempi reali e falsi, non vengono apportate modifiche ai parametri del discriminatore. Tuttavia, vengono apportati aggiornamenti di grandi dimensioni ai parametri del modello quando non riesce a distinguere tra immagini reali e false. L’inverso è vero per il modello generativo, viene penalizzato (e aggiornati i suoi parametri) quando non riesce a ingannare il modello discriminante, ma per il resto i suoi parametri rimangono invariati (o viene premiato).
Idealmente, il generatore è in grado di migliorare le sue prestazioni fino al punto in cui il discriminatore non può discernere tra le immagini false e quelle reali. Ciò significa che il discriminatore renderà sempre probabilità del 50% per immagini reali e false, il che significa che le immagini generate dovrebbero essere indistinguibili dalle immagini autentiche. In pratica, i GAN in genere non raggiungono questo punto. Tuttavia, il modello generativo non ha bisogno di creare immagini perfettamente simili per essere ancora utile per le numerose attività per cui vengono utilizzati i GAN.
Applicazioni GAN
I GAN hanno una serie di applicazioni diverse, la maggior parte delle quali ruota attorno alla generazione di immagini e componenti di immagini. I GAN sono comunemente utilizzati in attività in cui i dati immagine richiesti sono mancanti o limitati in una certa capacità, come metodo per generare i dati richiesti. Esaminiamo alcuni dei casi d’uso comuni per i GAN.
Generazione di nuovi esempi per i set di dati
I GAN possono essere utilizzati per generare nuovi esempi per semplici set di dati di immagini. Se hai solo una manciata di esempi di addestramento e ne hai bisogno di più, i GAN potrebbero essere utilizzati per generare nuovi dati di addestramento per un classificatore di immagini, generando nuovi esempi di addestramento con diversi orientamenti e angoli.
Generazione di volti umani unici
La donna in questa foto non esiste. L’immagine è stata generata da StyleGAN. Foto: Owlsmcgee tramite Wikimedia Commons, dominio pubblico (https://commons.wikimedia.org/wiki/File:Woman_1.jpg)
Quando sufficientemente addestrati, i GAN possono essere utilizzati per generare immagini estremamente realistiche di volti umani. Queste immagini generate possono essere utilizzate per aiutare ad addestrare i sistemi di riconoscimento facciale.
Traduzione da immagine a immagine
I GAN eccellono nella traduzione di immagini. I GAN possono essere utilizzati per colorare immagini in bianco e nero, tradurre schizzi o disegni in immagini fotografiche o convertire le immagini dal giorno alla notte.
Traduzione da testo a immagine
La traduzione da testo a immagine è possibile tramite l’uso di GAN . Quando viene fornito un testo che descrive un’immagine e l’immagine di accompagnamento, un GAN può essere addestrato a creare una nuova immagine quando viene fornita una descrizione dell’immagine desiderata.
Modifica e riparazione di immagini
I GAN possono essere utilizzati per modificare le fotografie esistenti. I GAN rimuovono elementi come pioggia o neve da un’immagine, ma possono anche essere utilizzati per riparare vecchie immagini danneggiate o immagini danneggiate.
Super risoluzione
La super risoluzione è il processo di acquisizione di un’immagine a bassa risoluzione e inserimento di più pixel nell’immagine, migliorando la risoluzione di quell’immagine. I GAN possono essere addestrati per acquisire un’immagine e generare una versione ad alta risoluzione di quell’immagine.