IL NUOVO MODELLO AI DI GOOGLE PUÒ ACCEDERE A DISTINTI RICORDI DI ENTITÀ CON DATI MINORI
I ricercatori del colosso tecnologico Google hanno introdotto un nuovo modello di intelligenza artificiale recentemente noto come Entities as Experts (EAE). Concentrandosi sul problema di acquisire conoscenze dichiarative nei parametri appresi di un modello di linguaggio, questo nuovo modello ha la capacità di accedere a memorie distinte delle entità menzionate in un pezzo di testo.
Uno dei componenti popolari nella comprensione del testo sono i modelli di sequenza di reti neurali che sono pre-addestrati come modelli di linguaggio. È stato suggerito che i modelli di linguaggio neurale potrebbero prendere il posto di basi di conoscenza curate o corpora testuali per compiti come rispondere alle domande.
Dietro le entità come esperti (EAE)
I ricercatori si sono concentrati sullo sviluppo di modelli di sequenze neurali che catturano le conoscenze necessarie per rispondere alle domande. I ricercatori hanno addestrato questo modello per prevedere estensioni mascherate nel testo di Wikipedia in inglese. Formano inoltre il modello EAE per accedere alle memorie solo per le menzioni delle entità e per accedere alle memorie corrette per ciascuna entità menzionata. Associando i ricordi a entità specifiche, EAE può imparare ad accedervi scarsamente.
Come funziona EAE
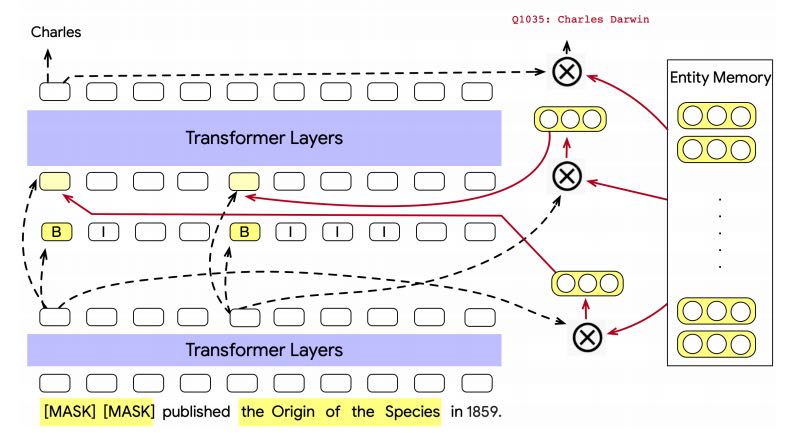
L’architettura del modello di base segue il Transformer interleaved con il livello di memoria dell’entità. Il modello EAE ha due matrici di incorporamento, che sono token e incorporamenti di entità. I ricercatori hanno valutato la capacità di EAE di acquisire conoscenze dichiarative utilizzando le sonde di conoscenza cloze e l’attività di risposta alle domande di TriviaQA.
Nella figura sopra, del modello EAE, l’output del layer trasformatore iniziale viene utilizzato per prevedere i limiti di menzione, recuperare gli embeddi di entità dalla memoria dell’entità e costruire input per il successivo layer del trasformatore, aumentato con gli embedding di entità recuperati del precedentemente recuperato incorporamenti di entità dalla memoria.
Lo strato finale del trasformatore può essere collegato a più teste specifiche per attività. In questo modello, l’output del blocco trasformatore finale è collegato a head specifici dell’attività, che sono la previsione token e la previsione entità. La testa di previsione del token prevede token mascherati per un’attività di cloze e la testa di previsione dell’entità prevede l’ID entità per ogni intervallo di menzione dell’entità, ovvero il collegamento di entità.
Nei cloze test, un modello deve recuperare le parole in una menzione cancellata associando correttamente
la menzione con il contesto della frase circostante. Il recupero dell’entità, dopo il primo strato di trasformatore sopra menzionato, viene quindi supervisionato con un obiettivo che collega l’entità durante la pre-formazione.
In questo modello, il livello di memoria dell’entità è strettamente legato ai livelli neurali basati sulla memoria, che possono essere visti come una rete di memoria in cui l’accesso alla memoria è supervisionato attraverso il collegamento di entità e ogni slot di memoria corrisponde a una rappresentazione di entità appresa.
Come è diverso dagli altri modelli
Secondo i ricercatori, a differenza dei precedenti sforzi per integrare la conoscenza dell’entità nei modelli di sequenza, questo modello di intelligenza artificiale non si basa su una base di conoscenza esterna per le sue rappresentazioni di entità. Invece, li impara direttamente dal testo, insieme a tutti gli altri parametri del modello.
Set di dati utilizzato
I ricercatori costruiscono il corpus formativo di contesti accoppiati con etichette di entità citate
dalla discarica dell’inglese Wikipedi a. Per la valutazione del modello EAE, i ricercatori hanno usato il set di dati TriviaQA , che è un set di dati su larga scala che contiene coppie di domande e risposte. Il set di dati è un set di dati di comprensione della lettura che contiene oltre 650.000 triple di domande e risposte.
I ricercatori hanno affermato di utilizzare una quantità minore di dati per addestrare e testare il modello. I dati di Wikipedia vengono preelaborati rimuovendo il 20% delle menzioni di entità scelte a caso. I ricercatori hanno inoltre creato set di sviluppo e test che hanno la stessa forma dei dati di formazione.
Leggi anche qui una nuova tecnica che visualizza come i neuroni interagiscono in una rete neurale
Avvolgendo
Secondo i ricercatori, accedendo solo a una piccola parte dei suoi parametri al momento dell’inferenza, questo modello di intelligenza artificiale supera un modello molto più grande su TriviaQA. I ricercatori hanno affermato che Entities as Experts (EAE) supera un modello Transformer con 30 × i parametri e contiene una conoscenza più concreta di un BERT di dimensioni simili, secondo la sonda di conoscenza del modello di linguaggio (LAMA) .