Google rilascia un nuovo set di dati per la comprensione avanzata degli oggetti 3D
Uno dei set di dati di riconoscimento del movimento umano più valutati nel deep learning
Imodelli di apprendimento automatico per le attività di visione artificiale sono stati ampiamente addestrati sulle foto. Tuttavia, esiste un’ampia possibilità di scalare fino a una gamma più ampia di applicazioni come realtà aumentata, autonomia, robotica e attività di recupero delle immagini se addestriamo questi modelli su oggetti 3D . Raggiungere questo obiettivo è stato un compito in salita poiché c’è una carenza di grandi set di dati del mondo reale di oggetti in 3D, rispetto ai set di dati 2D come ImageNet, COCO e Open Images.
Ora Google ha rilasciato il set di dati Objectron, che è una raccolta di brevi video clip incentrati sugli oggetti che catturano un ampio set di oggetti comuni da varie angolazioni. Insieme al set di dati, la ricerca descrive anche una nuova soluzione di rilevamento di oggetti 3D .
Objectron Dataset
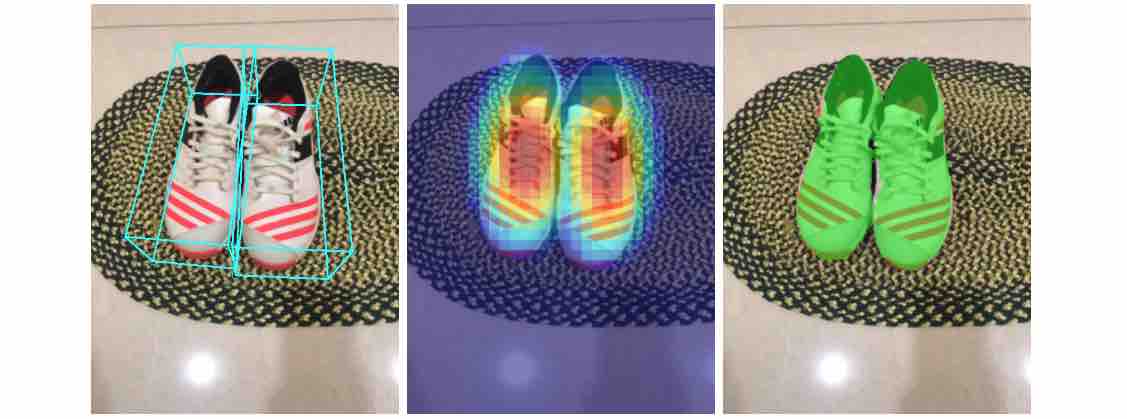
Il set di dati Objectron contiene video clip e immagini nelle seguenti categorie: biciclette, libri, fotocamere, bottiglie, sedie, tazze, scarpe e laptop. Consiste di 15.000 videoclip annotati e 4 milioni di immagini raccolte da un campione geo-diversificato che copre dieci paesi in cinque continenti. I dati contengono:
Riquadri di delimitazione annotati manualmente, che descrivono la posizione, l’orientamento e la dimensione di ciascun oggetto
I video clip contengono metadati di realtà aumentata come pose della telecamera e nuvole di punti sparse.
Una versione casuale dei fotogrammi annotati denominata set di dati elaborato per le immagini e formato SequenceExample per i video
Script per eseguire la valutazione
Supporto di script per caricare i dati in librerie di deep learning come Tensorflow, PyTorch e Jax per visualizzare il set di dati.
Soluzione di rilevamento di oggetti 3D
Il team di Google ha anche rilasciato una soluzione di rilevamento di oggetti 3D per quattro categorie di oggetti: scarpe, sedie, tazze e fotocamere. Questi modelli vengono addestrati utilizzando il set di dati Objectron. I modelli vengono rilasciati in MediaPipe. MediaPipe è una multipiattaforma open source che offre soluzioni di machine learning personalizzabili per media live e streaming; trova applicazioni nel rilevamento e tracciamento della posa umana, rilevamento della mano, rilevamento dell’iride, rilevamento di oggetti 3D e rilevamento del viso.
Nel modello a stadio singolo proposto all’inizio di quest’anno, la posa e le dimensioni fisiche di un oggetto sono state determinate utilizzando un’unica immagine RGB. Alcune delle caratteristiche di questo modello includono:
Un’architettura codificatore-decodificatore basata su MobileNetv2
Previsione della forma dell’oggetto utilizzando il rilevamento e la regressione
Utilizzo di un algoritmo di stima della posa ben consolidato per ottenere le coordinate 3D finali per il riquadro di delimitazione
Il modello è leggero e può essere eseguito in tempo reale su dispositivi mobili
Il nuovo modello di rilevamento di oggetti 3D, tuttavia, utilizza un’architettura a due stadi, un netto miglioramento rispetto al suo predecessore, menzionato sopra, che utilizzava un modello a stadio singolo. La prima fase di questo modello utilizza il modello TensorFlow Object Detection per trovare il ritaglio 2D dell’oggetto. Il ritaglio 2D viene utilizzato per determinare il riquadro di delimitazione 3D nella seconda fase. Per evitare di utilizzare il rilevamento degli oggetti per ogni fotogramma, il modello determina anche simultaneamente il ritaglio 2D per il fotogramma successivo.
Architettura della soluzione di rilevamento di oggetti 3D
Per valutare le prestazioni dei modelli di rilevamento 3D, è stata utilizzata una statistica di similarità 3D intersezione sull’unione (IoU). Chiamato anche indice Jaccard, IoU viene utilizzato per misurare la somiglianza e la diversità dei set di campioni; è comunemente usato per attività di visione artificiale che misurano quanto i riquadri di delimitazione siano vicini alla verità fondamentale.
Google ha proposto un algoritmo per la stima di valori 3D IoU accurati per i box di delimitazione. Utilizzando l’algoritmo di ritaglio del poligono di Sutherland-Hodgman, il team ha prima calcolato i punti di intersezione tra le facce delle due caselle e successivamente viene calcolato il volume di questa intersezione. Infine, questo volume calcolato dell’intersezione e dell’unione di due scatole viene utilizzato per il calcolo dell’IoU.
Calcolo dell’IoU
Con l’apertura del set di dati e l’introduzione del modello di rilevamento degli oggetti in due fasi, Google spera di consentire una ricerca più ampia nei campi della sintesi della vista, dell’apprendimento non supervisionato e della rappresentazione 3D migliorata .