I risultati dello studio possono essere molto utili per le applicazioni di machine learning che necessitano di un’inferenza rapida e precisa sui dispositivi finali
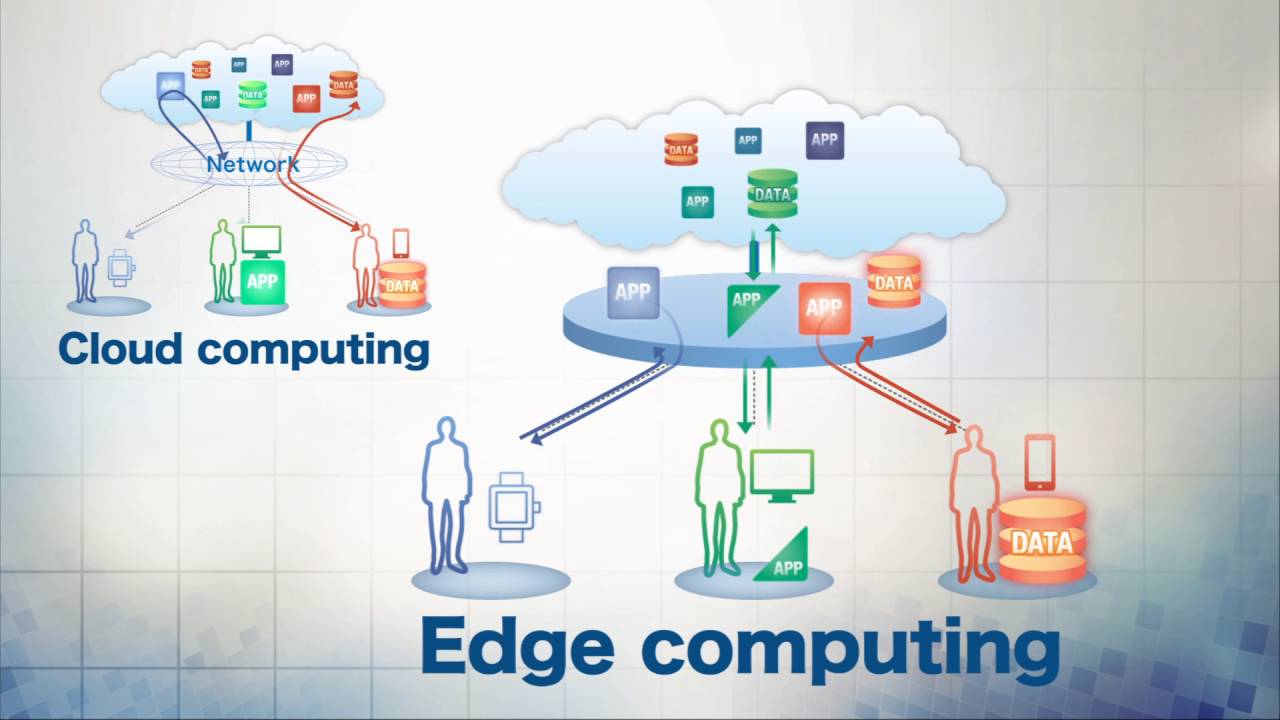
Siamo in un’era affascinante in cui anche i dispositivi con poche risorse, come i sensori dell’Internet of Things (IoT), possono utilizzare algoritmi di deep learning per affrontare problemi complessi come la classificazione delle immagini o l’elaborazione del linguaggio naturale (il ramo dell’intelligenza artificiale che si occupa di dare computer la capacità di comprendere la lingua parlata e scritta allo stesso modo degli esseri umani). Tuttavia, il deep learning nei sensori IoT potrebbe non essere in grado di garantire i requisiti di qualità del servizio (QoS) come l’accuratezza dell’inferenza e la latenza. Con la crescita esponenziale dei dati raccolti da miliardi di dispositivi IoT, è emersa la necessità di passare a un modello distribuito in cui parte dell’elaborazione avvenga ai margini della rete ( edge computing), più vicino a dove vengono creati i dati, anziché inviarli al cloud per l’elaborazione e l’archiviazione.
I ricercatori di IMDEA Networks Andrea Fresa (PhD Student) e Jaya Prakash Champati (Research Assistant Professor) hanno condotto uno studio in cui hanno presentato l’algoritmo AMR² , che fa uso dell’infrastruttura di edge computing (elaborazione, analisi e archiviazione dei dati più vicino a dove viene generato per consentire analisi e risposte più rapide e quasi in tempo reale) per aumentare la precisione dell’inferenza del sensore IoT osservando i vincoli di latenza e dimostrando che il problema è stato risolto. Il documento ” An Offloading Algorithm for Maximizing Inference Accuracy on Edge Device in an Edge Intelligence System ” è stato pubblicato questa settimana alla conferenza MSWiM.
Per capire cos’è l’inferenza, dobbiamo prima spiegare che l’apprendimento automatico funziona in due fasi principali. Il primo si riferisce alla formazione quando lo sviluppatore alimenta il proprio modello con una serie di dati curati in modo che possa “apprendere” tutto ciò che deve sapere sul tipo di dati che analizzerà. La fase successiva è l’ inferenza : il modello può fare previsioni basate su dati reali per produrre risultati attuabili.
Nella loro pubblicazione, i ricercatori hanno concluso che l’accuratezza dell’inferenza è aumentata fino al 40% quando si confronta l’algoritmo AMR² con le tecniche di pianificazione di base. Hanno anche scoperto che un algoritmo di pianificazione efficiente è essenziale per supportare correttamente gli algoritmi di apprendimento automatico ai margini della rete.
“I risultati del nostro studio potrebbero essere estremamente utili per le applicazioni di Machine Learning (ML) che necessitano di un’inferenza rapida e accurata sui dispositivi finali. Pensa a un servizio come Google Foto, ad esempio, che classifica gli elementi dell’immagine. Possiamo garantire il ritardo di esecuzione utilizzando l’algoritmo AMR², che può essere molto fruttuoso per uno sviluppatore che può utilizzarlo nella progettazione per garantire che i ritardi non siano visibili all’utente”, spiega Andrea Fresa.
L’ostacolo principale che hanno incontrato nella conduzione di questo studio è dimostrare le prestazioni teoriche dell’algoritmo AMR² e convalidarlo utilizzando un banco di prova sperimentale composto da un Raspberry Pi e un server connesso tramite una LAN . “Per dimostrare i limiti delle prestazioni di AMR², abbiamo utilizzato idee fondamentali dalla programmazione lineare e strumenti dalla ricerca operativa”, sottolinea Fresa.
Tuttavia, con questo lavoro, i ricercatori di IMDEA Networks hanno gettato le basi per ricerche future che consentiranno di eseguire applicazioni di apprendimento automatico (ML) ai margini della rete in modo rapido e accurato.
