Riepilogo: il vertice HW AI 2020
Il 3 ° vertice annuale sull’hardware AI si è concluso la scorsa settimana, dopo quattro giorni di presentazioni, panel e discussioni strabilianti sull’esplosione del Cambriano nell’IA. Per oltre due anni, molti di noi osservatori del settore hanno aspettato che i giocatori, grandi e piccoli, presentassero i parametri di riferimento per la produzione di silicio funzionante. Negli anni precedenti, solo NVIDIA ha fornito (o dovrei dire superato) il tipo di miglioramenti che mi aspettavo. Sfortunatamente, quest’anno, abbiamo dovuto accontentarci ancora una volta di presentazioni PowerPoint piene di affermazioni che erano al massimo ottimistiche. Su una nota più brillante, mentre NVIDIA governa ancora il data center, i potenziali concorrenti sembrano finalmente avvicinarsi ai prodotti reali. Molti ora stanno spedendo i loro campioni ai grandi clienti che realizzeranno o distruggeranno i sogni dei loro investitori. Immergiamoci ed esaminiamo chi mi entusiasma e chi continua a deludere. Vorrei sottolineare che né NVIDIA né Intel hanno presentato quest’anno, probabilmente per ragioni molto diverse.
Ero entusiasta che nientemeno che David Patterson abbia dato il via all’evento con un keynote sull’intelligenza artificiale all’avanguardia di Google. Mentre il discorso sulla riduzione delle dimensioni del problema e TPU-V3 è stato entusiasmante, la cosa più importante che ho imparato da Patterson è che sebbene i benchmark non mentano, potrebbero non raccontare l’intera storia. In particolare, ha sottolineato che il TPU-V3 e il suo contemporaneo NVIDIA V100 sono più o meno nello stesso campo di battaglia quando si tratta di risultati MLPerf. Ma internamente, gli ingegneri di Google utilizzano BFloat16 più efficiente invece di IEEE fp16 e l’impatto è enorme. Patterson ha anche notato che la maggior parte dei professionisti utilizza ancora il formato IEEE fp32 molto più lento per aumentare la precisione, facendomi chiedere se gli utenti esterni di TPU-V3 abbiano effettuato il passaggio e realizzato questi vantaggi.
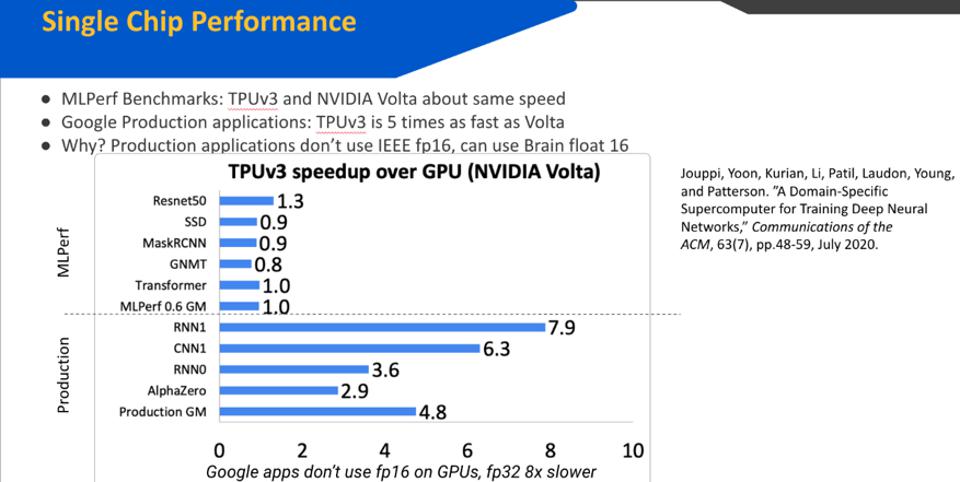
Figura 1: TPU-V3 offre prestazioni notevolmente migliori utilizzando il formato BFloat16.
Una delle aziende che ha fatto alcune grandi rivelazioni all’evento è stata la furtiva startup SambaNova. Proprio come GraphCore del Regno Unito, SambaNova e la sua piattaforma di elaborazione delle inferenze si concentrano sulla risoluzione di alcuni dei più grandi modelli di intelligenza artificiale, tra cui l’elaborazione del linguaggio naturale, l’elaborazione di immagini scientifiche e modelli di raccomandazione. In particolare, i modelli di raccomandazione stanno diventando la prossima grande novità nell’intelligenza artificiale, sebbene siano difficili da accelerare a causa delle gigantesche tabelle incorporate che queste applicazioni manipolano. Credo che questo sia un esempio di una tendenza significativa che vedremo svilupparsi nei prossimi anni. I concorrenti di NVIDIA si concentreranno sulle applicazioni che sono troppo massicce per essere gestite da una GPU o sulle applicazioni di fascia bassa che voleranno sotto lo schermo radar di NVIDIA.
Sospetto che SambaNova si stia avvicinando alla preparazione della produzione, come evidenziato dal rilascio dei dati sulle prestazioni. Il primo è stato uno scatto a NVIDIA per Bert-Large, che mostrava un throughput 16 volte superiore alla metà della latenza, con una dimensione batch di uno. Tuttavia, questo è un confronto con la NVIDIA V100 di tre anni. Quando SambaNova verrà finalmente lanciato, mi aspetto un confronto con il più recente A100.
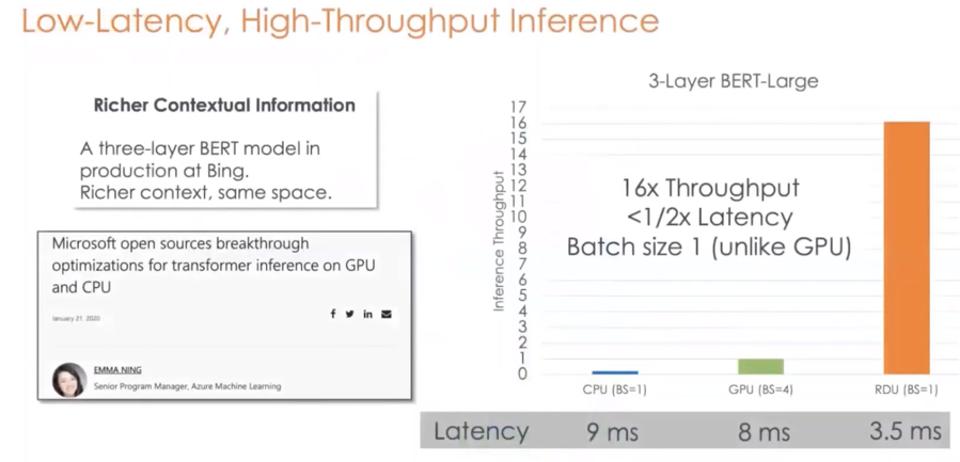
Figura 2: SambaNova afferma che il suo chip può superare di 16 volte una GPU NVIDIA V100, con una latenza migliore.
Devo dire che Groq rimane un po ‘un enigma per me. Il fondatore e CEO, Jonathan Ross, afferma che il suo chip è l’unico processore AI da 1000 TOPS: un’affermazione impressionante per essere sicuri. Al vertice, ha affermato che la società sta inviando campioni a grandi clienti, ma ha rifiutato di fornire confronti significativi che consentano a tutti noi di “raggruppare” le capacità del chip. Data l’eredità di Google TPU dell’azienda, non ho motivo di dubitare che il primo prodotto sarà piuttosto impressionante. Ma dovremo aspettare ancora un po ‘per vedere alcuni numeri di prestazioni!

Figura 3: Groq, la startup fondata dagli inventori di Google TPU, sta campionando la sua piattaforma AI per selezionare i clienti.
Rispetto al bagliore di alcune altre società presenti all’evento, Ziad Ashgar di Qualcomm è stato un soffio di calma fiducia in se stessi e sicurezza. Come ho detto su Forbesprima, credo che il Cloud AI100 (ora in campionamento) sia un forte concorrente e una valida alternativa a NVIDIA per il cloud edge e l’AI 5G. Capace di completare 400 TOPS consumando solo 75 watt, Cloud AI100 è una delle piattaforme di inferenza più efficienti annunciate fino ad oggi. Ashgar ha inserito tutto questo nel contesto della visione dell’azienda per l’intelligenza distribuita, dai dispositivi Snapdragon mobili e incorporati all’edge cloud e ai provider di servizi cloud di primo livello. Qualcomm vuole che tutti sappiano che la società ha una visione e una tecnologia impressionante da offrire, insieme a uno degli stack di software AI più affermati del settore. Devo ammettere che sono un fan.
Mitico
OK, ora torniamo ai tavoli da disegno. Mythic è stata una delle startup di più alto profilo a concentrarsi sull’elaborazione analogica per l’IA. L’azienda ha la visione di eseguire calcoli a matrice all’interno di chip di memoria Flash. Anche se questo può sembrare folle, è uno degli sviluppi più eccitanti che potrebbero concretizzarsi tra oggi e il Quantum computing, l’ultima tecnologia di elaborazione della nostra vita. Il flash è molto denso e consuma pochissima energia, soprattutto quando è spento. Le prime ricerche prevedono che questo approccio potrebbe migliorare l’efficienza di almeno un ordine di grandezza. Restate sintonizzati per questo!

Figura 4: Mythic si impegna a costruire il primo acceleratore AI analogico di produzione basato sulla memoria flash.
Oltre a presentare il mio stato annuale del panorama industriale, sono stato onorato di essere stato invitato da Synopsys a ospitare una tavola rotonda sull’uso dell’IA per migliorare l’ottimizzazione del design dei semiconduttori. La piccola tavola rotonda ha coinvolto gli ingegneri Intel, Google e Synopsys e ha evidenziato il percorso AI di ciascuna azienda per ridurre i costi, migliorare la qualità e fornire chip più veloci a bassa potenza. Ho sentito molto da Synopsis sui risultati impressionantii suoi clienti hanno visto con AI. L’azienda EDA ha utilizzato l’IA per ottimizzare il processo di progettazione fisica (luogo e percorso) in modo che potesse essere fatto con meno ingegneri, in meno tempo. Questo processo ha aiutato l’azienda a creare prodotti dai SOC mobili agli acceleratori AI al di sopra della frequenza target, spesso con meno potenza e area dello stampo. Ora, team di ingegneri all’avanguardia utilizzano l’IA durante il processo di sviluppo con risultati impressionanti, ottenendo una migliore efficienza del chip del 30% con meno ingegneria. Il messaggio era chiaro: i team di semiconduttori utilizzano meglio l’intelligenza artificiale per ottimizzare la progettazione dei chip, altrimenti rimarranno indietro.
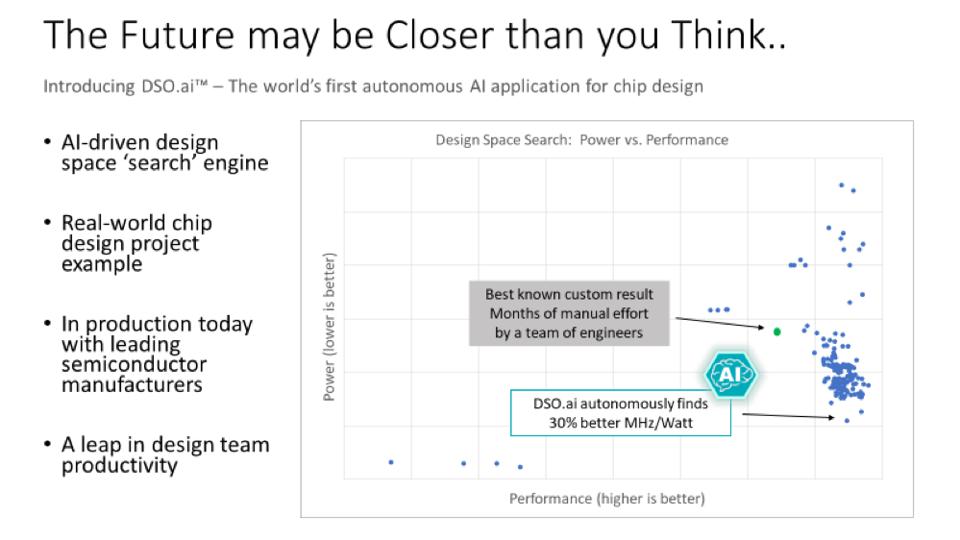
Figura 5: Synopsys sfrutta l’intelligenza artificiale per aiutare i team di semiconduttori a produrre chip migliori, con meno sforzi e tempo.
La società di software e servizi di intelligenza artificiale Codeplay ha presentato i suoi pensieri ed esperienze su come i partecipanti alla conferenza dovrebbero pensare alle vittorie di design. Ci sono stati alcuni bocconcini che ho portato via e inviato ai miei clienti. Codeplay ha fatto eco a ciò che ho consigliato ai miei clienti. Supponiamo che un’azienda come Facebook o Microsoft determini, dopo un ampio sviluppo e analisi, che l’architettura di una startup è degna di essere implementata. Ma prima di aprire quei tappi di champagne, renditi conto che tutto questo ha richiesto molto tempo, durante il quale l’incumbent, inevitabilmente, NVIDA ha migliorato le prestazioni o addirittura introdotto un nuovo e migliore chip. È improbabile che queste grandi aziende accetteranno molti rischi per risparmiare pochi dollari. Di conseguenza, dovresti aspettarti che il primo chip possa essere solo un chip di prova per distribuire il tuo secondo chip e non una fonte significativa di entrate. Questa regola non è sempre valida, poiché alcune IA potrebbero consentire soluzioni a problemi irrisolti che potrebbero produrre nuove entrate sostanziali. Ma è un possibile risultato per il quale qualsiasi startup deve tenere conto dei suoi piani e bruciare denaro. Come ci ha sempre ammonito il mio professore di informatica all’università (Fred Brooks, inventore dell’IBM 360): costruisci la prima soluzione e poi buttala via.
Figura 6: Codeplay ha presentato le sue esperienze e le intuizioni di anni di assistenza alle aziende di chip a ottenere risultati di progettazione.
Sono esausto e sospetto che lo sia anche tu se sei arrivato alla fine di questo blog! L’esplosione cambriana degli acceleratori di intelligenza artificiale è ancora nelle prime fasi di sperimentazione e innovazione. Non vedo l’ora di vedere cosa c’è dopo!
Karl Freund