Una nuova architettura di rete neurale progettata dai ricercatori di intelligenza artificiale di DarwinAI e dell’Università di Waterloo consentirà di eseguire la segmentazione delle immagini su dispositivi informatici a bassa potenza e capacità di calcolo.
La segmentazione è il processo di determinazione dei confini e delle aree degli oggetti nelle immagini. Noi umani eseguiamo la segmentazione senza uno sforzo cosciente, ma rimane una sfida fondamentale per i sistemi di apprendimento automatico. È fondamentale per la funzionalità di robot mobili, auto a guida autonoma e altri sistemi di intelligenza artificiale che devono interagire e navigare nel mondo reale.
Fino a poco tempo, la segmentazione richiedeva reti neurali di grandi dimensioni e ad alta intensità di calcolo. Ciò ha reso difficile eseguire questi modelli di deep learning senza una connessione ai server cloud.
Nel loro ultimo lavoro, gli scienziati di DarwinAI e dell’Università di Waterloo sono riusciti a creare una rete neurale che fornisce una segmentazione quasi ottimale ed è abbastanza piccola da adattarsi a dispositivi con risorse limitate. Chiamata AttendSeg, la rete neurale è descritta in dettaglio in un documento che è stato accettato alla Conference on Computer Vision and Pattern Recognition (CVPR) di quest’anno.
Classificazione, rilevamento e segmentazione degli oggetti
Uno dei motivi principali del crescente interesse per i sistemi di apprendimento automatico sono i problemi che possono risolvere nella visione artificiale . Alcune delle applicazioni più comuni dell’apprendimento automatico nella visione artificiale includono la classificazione delle immagini, il rilevamento di oggetti e la segmentazione.
La classificazione delle immagini determina se un determinato tipo di oggetto è presente in un’immagine o meno. Il rilevamento degli oggetti migliora ulteriormente la classificazione delle immagini e fornisce il riquadro di delimitazione in cui si trovano gli oggetti rilevati.
La segmentazione è disponibile in due versioni: segmentazione semantica e segmentazione delle istanze. La segmentazione semantica specifica la classe di oggetti di ogni pixel in un’immagine di input. La segmentazione delle istanze separa le singole istanze di ogni tipo di oggetto. Per scopi pratici, l’output delle reti di segmentazione è solitamente presentato colorando i pixel. La segmentazione è di gran lunga il tipo più complicato di attività di classificazione.

Sopra: classificazione delle immagini vs. rilevamento di oggetti e segmentazione semantica (credito: codebasics ).
La complessità delle reti neurali convoluzionali (CNN), l’architettura di apprendimento profondo comunemente utilizzata nelle attività di visione artificiale, viene solitamente misurata dal numero di parametri che hanno. Più parametri ha una rete neurale, maggiore sarà la memoria e la potenza di calcolo che richiederà.
RefineNet, una popolare rete neurale di segmentazione semantica, contiene più di 85 milioni di parametri. A 4 byte per parametro, significa che un’applicazione che utilizza RefineNet richiede almeno 340 megabyte di memoria solo per eseguire la rete neurale. E dato che le prestazioni delle reti neurali dipendono in gran parte dall’hardware in grado di eseguire rapide moltiplicazioni di matrici, significa che il modello deve essere caricato sulla scheda grafica o su qualche altra unità di calcolo parallelo, dove la memoria è più scarsa della RAM del computer.
Apprendimento automatico per dispositivi periferici
A causa dei requisiti hardware, la maggior parte delle applicazioni di segmentazione delle immagini richiede una connessione Internet per inviare immagini a un server cloud in grado di eseguire modelli di deep learning di grandi dimensioni. La connessione cloud può porre limiti aggiuntivi alla posizione in cui è possibile utilizzare la segmentazione delle immagini. Ad esempio, se un drone o un robot opererà in ambienti in cui non è disponibile una connessione Internet, eseguire la segmentazione delle immagini diventerà un compito impegnativo. In altri domini, gli agenti di intelligenza artificiale lavoreranno in ambienti sensibili e l’invio di immagini al cloud sarà soggetto a vincoli di privacy e sicurezza. Il ritardo causato dal viaggio di andata e ritorno verso il cloud può essere proibitivo nelle applicazioni che richiedono una risposta in tempo reale dai modelli di machine learning. E vale la pena notare che l’hardware di rete stesso consuma molta energia,
Per tutti questi motivi (e alcuni altri), l’ IA edge e il tiny machine learning (TinyML) sono diventati aree di interesse e di ricerca calde sia nel mondo accademico che nel settore dell’IA applicata . L’obiettivo di TinyML è creare modelli di machine learning che possano essere eseguiti su dispositivi con limitazioni di memoria e alimentazione senza la necessità di una connessione al cloud.
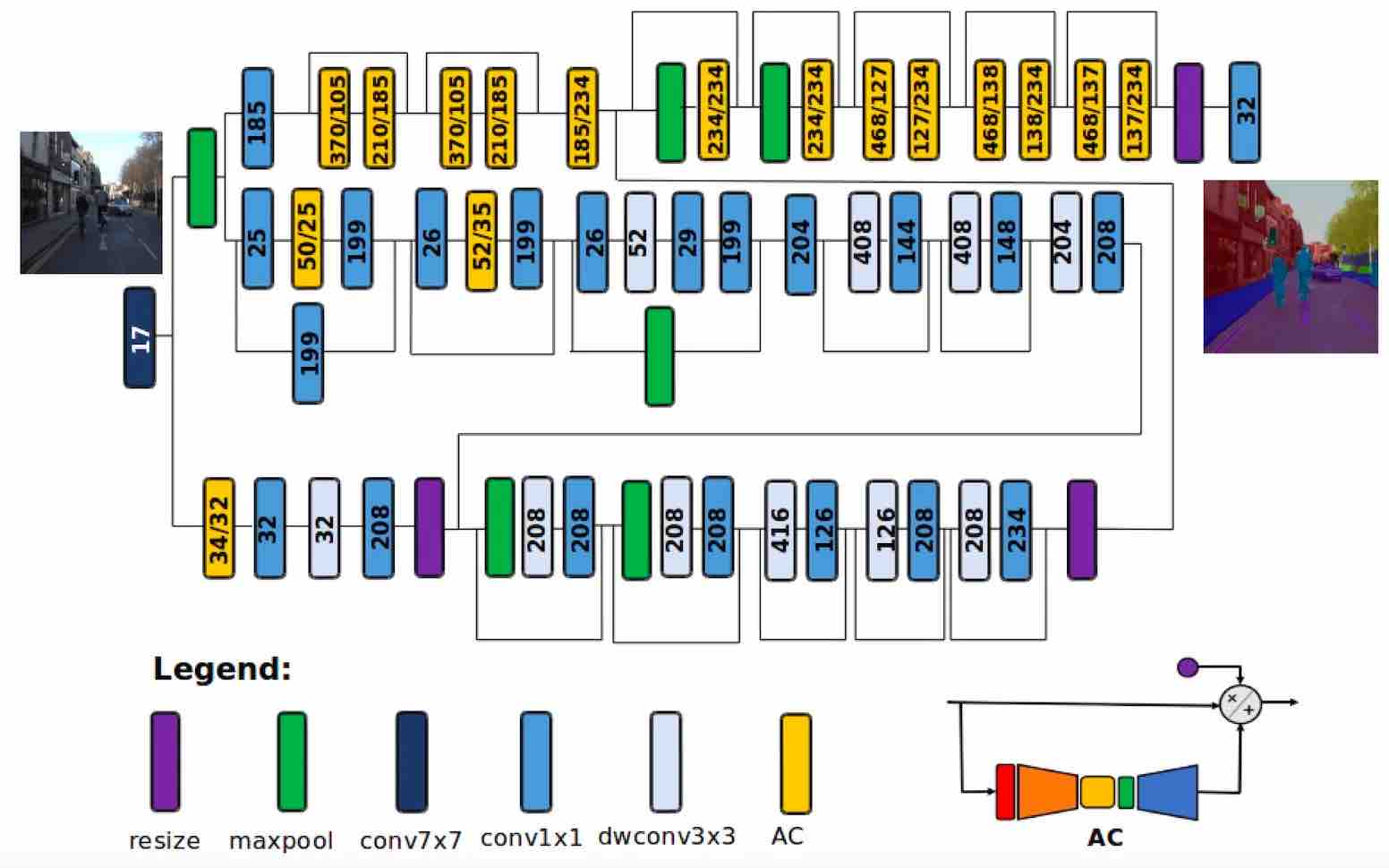
Sopra: l’architettura della rete neurale a segmentazione semantica su dispositivo AttendSeg.
Con AttendSeg, i ricercatori di DarwinAI e dell’Università di Waterloo hanno cercato di affrontare le sfide della segmentazione semantica su dispositivo.
“L’idea di AttendSeg è stata trainata sia dalla nostra volontà di avanzare il campo di TinyML e le esigenze del mercato che abbiamo visto come DarwinAI,” Alexander Wong, co-fondatore di DarwinAI e professore associato presso l’Università di Waterloo, ha detto TechTalks . “Esistono numerose applicazioni industriali per approcci di segmentazione edge-ready altamente efficienti, e questo è il tipo di feedback insieme alle esigenze di mercato che vedo che guida tale ricerca”.
Il documento descrive AttendSeg come “una rete di segmentazione semantica profonda a bassa precisione e altamente compatta su misura per le applicazioni TinyML”.
Il modello di deep learning AttendSeg esegue la segmentazione semantica con una precisione quasi alla pari con RefineNet, riducendo il numero di parametri a 1,19 milioni. È interessante notare che i ricercatori hanno anche scoperto che l’abbassamento della precisione dei parametri da 32 bit (4 byte) a 8 bit (1 byte) non ha comportato una significativa riduzione delle prestazioni, consentendo loro di ridurre l’impronta di memoria di AttendSeg di un fattore quattro . Il modello richiede poco più di un megabyte di memoria, che è abbastanza piccolo da adattarsi alla maggior parte dei dispositivi periferici.
“[I parametri a 8 bit] non rappresentano un limite in termini di generalizzabilità della rete sulla base dei nostri esperimenti e dimostrano che la rappresentazione a bassa precisione può essere molto vantaggiosa in questi casi (devi solo usare la precisione necessaria), “Ha detto Wong.

Sopra: gli esperimenti mostrano che AttendSeg fornisce una segmentazione semantica ottimale riducendo il numero di parametri e l’impronta di memoria.
Condensatori di attenzione per visione artificiale
AttendSeg sfrutta i “condensatori di attenzione” per ridurre le dimensioni del modello senza compromettere le prestazioni. I meccanismi di auto-attenzione sono una serie che migliorano l’efficienza delle reti neurali concentrandosi sulle informazioni che contano. Le tecniche di auto-attenzione sono state un vantaggio nel campo dell’elaborazione del linguaggio naturale . Sono stati un fattore determinante nel successo delle architetture di apprendimento profondo come Transformers. Mentre le precedenti architetture come le reti neurali ricorrenti avevano una capacità limitata su lunghe sequenze di dati, Transformers utilizzava meccanismi di auto-attenzione per espandere la loro portata. I modelli di deep learning come GPT-3 sfruttano Transformers e l’auto-attenzione per sfornare lunghe stringhe di testo che ( almeno superficialmente ) mantengono la coerenza su lunghi intervalli.
I ricercatori di intelligenza artificiale hanno anche sfruttato i meccanismi di attenzione per migliorare le prestazioni delle reti neurali convoluzionali. L’anno scorso, Wong ei suoi colleghi hanno introdotto i condensatori di attenzione come un meccanismo di attenzione molto efficiente in termini di risorse e li hanno applicati ai modelli di apprendimento automatico del classificatore di immagini .
“[Attention condensers] consentono architetture di reti neurali profonde molto compatte che possono comunque raggiungere prestazioni elevate, rendendole molto adatte per applicazioni edge / TinyML”, ha affermato Wong.
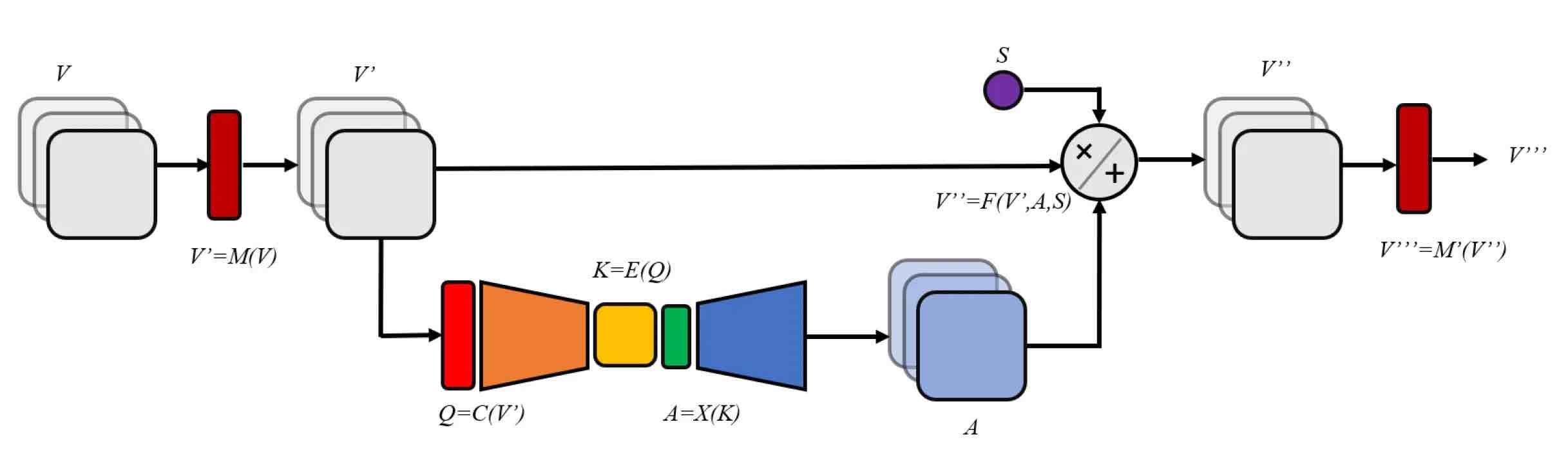
Sopra: i condensatori di attenzione migliorano le prestazioni delle reti neurali convoluzionali in modo efficiente in termini di memoria.
Progettazione guidata da macchine di reti neurali
Una delle sfide principali della progettazione di reti neurali TinyML è trovare l’architettura con le migliori prestazioni rispettando al contempo il budget computazionale del dispositivo di destinazione.
Per affrontare questa sfida, i ricercatori hanno utilizzato la ” sintesi generativa ” , una tecnica di apprendimento automatico che crea architetture di reti neurali basate su obiettivi e vincoli specifici. Fondamentalmente, invece di giocherellare manualmente con tutti i tipi di configurazioni e architetture, i ricercatori forniscono uno spazio problematico al modello di apprendimento automatico e lasciano che scopra la migliore combinazione.
“Il processo di progettazione guidato dalla macchina qui sfruttato (sintesi generativa) richiede che l’essere umano fornisca un prototipo di progetto iniziale e requisiti operativi desiderati specificati dall’uomo (ad es. Dimensioni, precisione, ecc.) E il processo di progettazione MD prende il sopravvento nell’apprendimento da esso e la generazione del design dell’architettura ottimale su misura in base ai requisiti operativi e alle attività e ai dati disponibili “, ha affermato Wong.
Per i loro esperimenti, i ricercatori hanno utilizzato la progettazione guidata dalla macchina per mettere a punto AttendSeg per Nvidia Jetson, kit hardware per robotica e applicazioni di intelligenza artificiale edge. Ma AttendSeg non è limitato a Jetson.
“In sostanza, la rete neurale AttendSeg funzionerà velocemente sulla maggior parte dell’hardware edge rispetto alle reti proposte in precedenza in letteratura”, ha affermato Wong. “Tuttavia, se si desidera generare un AttendSeg ancora più personalizzato per un particolare componente hardware, è possibile utilizzare l’approccio di esplorazione della progettazione guidata dalla macchina per creare una nuova rete altamente personalizzata”.
AttendSeg ha ovvie applicazioni per droni, robot e veicoli autonomi, dove la segmentazione semantica è un requisito fondamentale per la navigazione. Ma la segmentazione sul dispositivo può avere molte più applicazioni.
“Questo tipo di rete neurale di segmentazione altamente compatta e altamente efficiente può essere utilizzato per un’ampia varietà di cose, che vanno dalle applicazioni di produzione (ad esempio, ispezione di parti / valutazione della qualità, controllo robotico), applicazioni mediche (ad esempio, analisi cellulare, segmentazione del tumore), applicazioni di telerilevamento satellitare (ad esempio, segmentazione della copertura del suolo) e applicazioni mobili (ad esempio, segmentazione umana per la realtà aumentata) “, ha detto Wong.