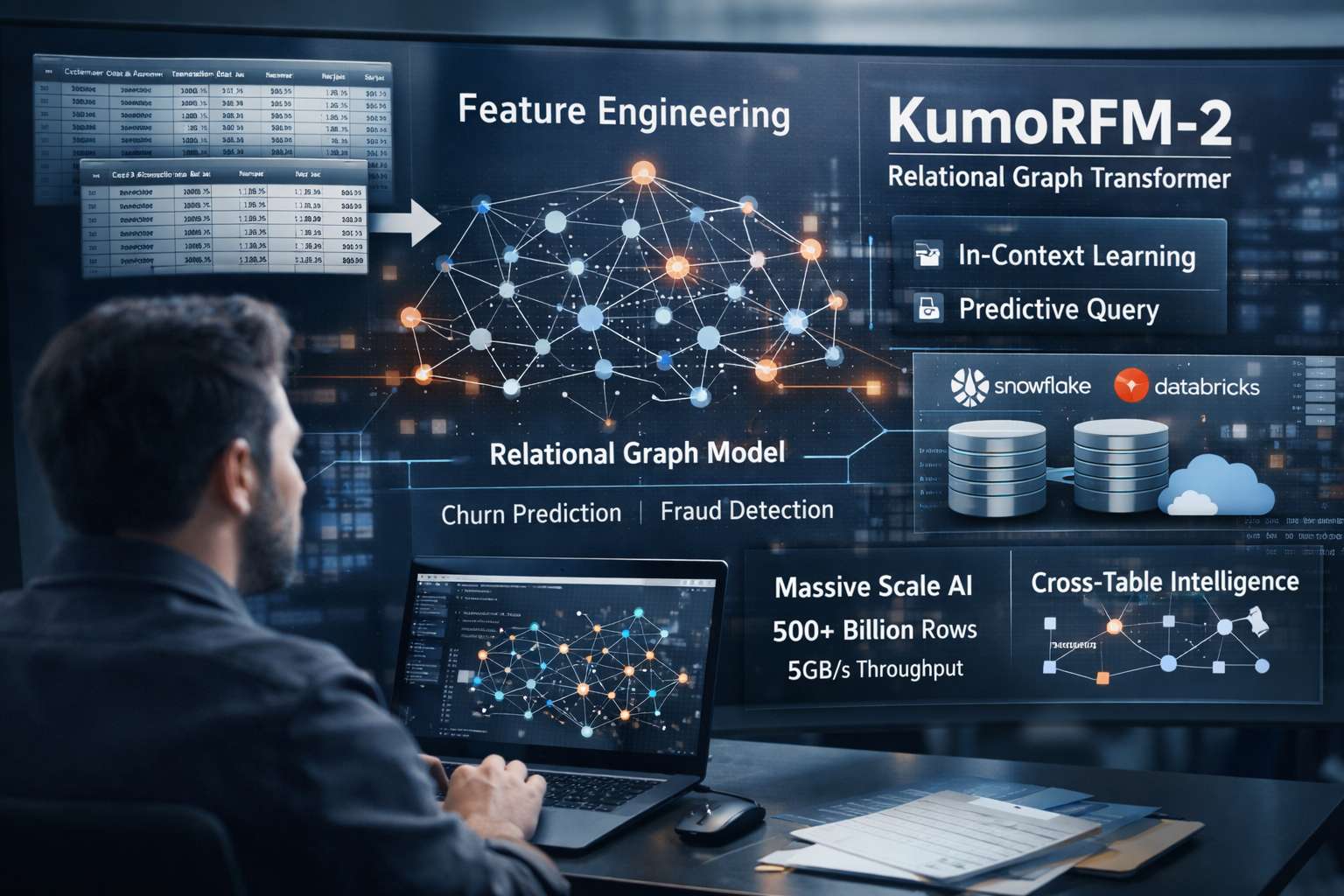
L’ecosistema del machine learning enterprise è stato per decenni vincolato a un processo lineare e frammentato, caratterizzato dalla creazione di pipeline specifiche per ogni singolo task predittivo. Questo approccio richiede tipicamente mesi di ingegneria delle caratteristiche (feature engineering), durante i quali i data scientist devono estrarre e appiattire i dati provenienti da database relazionali complessi in singole tabelle “piatte”. In questo passaggio cruciale, gran parte della ricchezza semantica e dei collegamenti intrinseci tra le entità del database viene inevitabilmente persa. KumoRFM-2 nasce per eliminare questa barriera, introducendo il concetto di modello fondazionale applicato direttamente ai grafi relazionali. Invece di addestrare un modello da zero per ogni specifica esigenza, come la churn rate o la prevenzione delle frodi, KumoRFM-2 utilizza un’unica architettura pre-addestrata su vasti volumi di dati strutturati, capace di comprendere le connessioni tra tabelle senza interventi manuali.
Il cuore pulsante di KumoRFM-2 è rappresentato dalla sua architettura a trasformatori di grafi relazionali, un’evoluzione significativa rispetto alle reti neurali a grafo (GNN) tradizionali. Mentre le GNN classiche tendono a limitare l’analisi alle vicinanze locali dei nodi, il Relational Graph Transformer di Kumo implementa un sistema di attenzione gerarchica che opera su tre livelli distinti. Il primo livello analizza le singole tabelle attraverso meccanismi di attenzione a livello di riga e colonna, catturando le distribuzioni dei valori all’interno dei campi. Il secondo livello estende questa analisi attraverso le tabelle, utilizzando l’attenzione a grafo per seguire le chiavi esterne (foreign keys) e preservare l’integrità delle relazioni tra entità diverse. Infine, il terzo livello introduce l’attenzione cross-sample, che permette al modello di confrontare diversi esempi di contesto per affinare la precisione della previsione. Questa struttura permette al modello di mappare l’intera topologia del database, rendendo obsoleta la necessità di aggregazioni manuali dei dati.
Una delle caratteristiche più dirompenti di KumoRFM-2 è la sua capacità di eseguire l’apprendimento nel contesto (In-Context Learning o ICL). Analogamente a quanto avviene con i grandi modelli linguistici (LLM) che possono rispondere a nuove istruzioni senza essere riaddestrati, KumoRFM-2 può generare previsioni accurate semplicemente ricevendo alcuni esempi di contesto al momento dell’interrogazione. Questo significa che il modello non necessita di una fase di addestramento specifica per ogni nuovo task aziendale. Il sistema genera automaticamente dei sottografi del database che contengono esempi rilevanti e risultati noti, permettendo al motore di inferenza di generalizzare istantaneamente. I dati indicano che KumoRFM-2 può raggiungere prestazioni superiori ai modelli supervisionati tradizionali utilizzando solo una minima frazione dei dati etichettati che sarebbero normalmente necessari, garantendo una velocità di implementazione superiore rispetto ai metodi classici.
Per rispondere alle esigenze delle grandi organizzazioni, KumoRFM-2 è stato ingegnerizzato per operare su scale massicce, supportando dataset che superano i 500 miliardi di righe. Questo traguardo è reso possibile da un motore a grafo personalizzato che esegue accessi ai dati ad alta velocità, raggiungendo un throughput di circa 5 gigabyte al secondo e gestendo fino a 20 milioni di lookup al secondo. L’architettura è progettata per integrarsi nativamente con le infrastrutture cloud già esistenti, come Snowflake e Databricks. Attraverso il Predictive Query Language (PQL), un linguaggio di interrogazione simile al SQL, gli utenti possono formulare domande predittive in linguaggio naturale. Il sistema traduce queste richieste in operazioni complesse sul grafo sottostante, eliminando la necessità di spostare massicce quantità di dati al di fuori dei perimetri di sicurezza aziendali e garantendo che la predizione diventi una funzione integrata del database stesso.
KumoRFM-2 ha dimostrato di superare i benchmark di riferimento del settore, inclusi gli ensemble di modelli specifici per dati tabulari e i sistemi basati su gradient boosting. Oltre alla precisione, l’aspetto fondamentale è la resilienza del modello: KumoRFM-2 mantiene un’elevata affidabilità anche in scenari di scarsità di dati storici o quando i dataset sono incompleti. Il modello è in grado di gestire situazioni in cui mancano ampie porzioni di collegamenti relazionali o in cui le colonne di input presentano un alto grado di rumore statistico. Questa robustezza trasforma il machine learning da un esercizio di precisione manuale a uno strumento industriale solido e scalabile, capace di fornire risposte immediate a domande di business complesse senza i colli di bottiglia tipici della data science tradizionale.