
“L’empatia, evidentemente, esisteva solo all’interno della comunità umana, mentre l’intelligenza in una certa misura poteva essere trovata in ogni filone.”
Philip K. Dick
I dilemmi morali fanno parte della natura umana. Sebbene le azioni possano essere condensate in semplici caselle di controllo sì o no, le intenzioni tuttavia ricadono in una zona grigia intangibile, che è molto difficile da decifrare. Ora, se le macchine, che sono innatamente binarie (0 e 1), hanno il compito di prendere decisioni simili a incroci etici, le possibilità di comportamenti irregolari sono piuttosto alte. Solo in questo caso, la colpa non migliorerebbe le macchine. Il dominio dell’apprendimento per rinforzo, in particolare, che cerca di imitare le funzioni cognitive della mente umana, può essere un buon posto per studiare le macchine nelle incertezze morali.
I ricercatori Adrien Ecoffet e Joel Lehman, ex Uber AI, pur riconoscendo l’incertezza morale, hanno proposto un formalismo che traduce intuizioni filosofiche nel campo dell’apprendimento per rinforzo.
In un quadro filosofico, “salvare una vita” può essere immediatamente associato alla buona volontà. Tuttavia, per tradurre lo stesso nel mondo delle macchine potrebbe essere necessario “ruotare il 5 ° giunto del braccio del robot di 3 gradi in senso orario”. Uno dei contributi chiave di questo lavoro è fornire concrete implementazioni dell’incertezza morale , colmando il divario tra opzioni e azioni.
Filosofia attraverso l’obiettivo di RL
“Rimane un’incertezza fondamentale: quale teoria etica dovrebbe seguire un agente intelligente?”
Uno dei vantaggi della traduzione dell’incertezza morale da un quadro filosofico a un processo decisionale sequenziale è che altre chiare complicazioni del processo decisionale morale del mondo reale diventano chiare, il che può suggerire problemi di ricerca concreti o connessioni con la ricerca esistente in RL.
Per esplorare quali metodi possono essere quantificati in un quadro decisionale, i ricercatori hanno esplorato quanto segue:
Massimizzare la dignità della scelta attesa
Voto stocastico
Nash Voting
Votazione della varianza
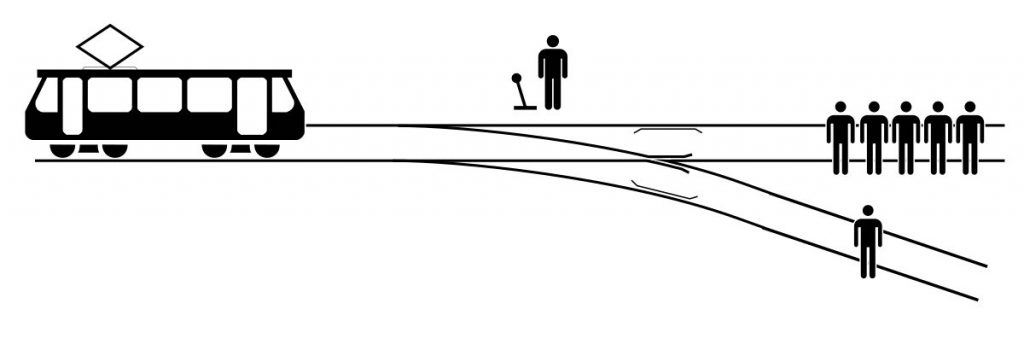
Tutti gli esperimenti in questo lavoro si basano su quattro ambienti gridworld correlati che prendono in giro le differenze tra i vari sistemi di voto. Questi ambienti sono tutti basati sul popolare problema dei trolley, usati per evidenziare intuizioni morali e conflitti tra teorie etiche. Il problema del carrello è un difficile dilemma etico in cui un osservatore ha il controllo del cambio di direzione del carrello. L’osservatore ha solo due opzioni: uccidere cinque persone e salvarne una o salvarne cinque e uccidere una persona. In quest’ultimo caso, il numero di persone salvate è elevato, ma ciò porrebbe anche una domanda su ciò che ha spinto l’osservatore a decidere che una persona meritava di morire.
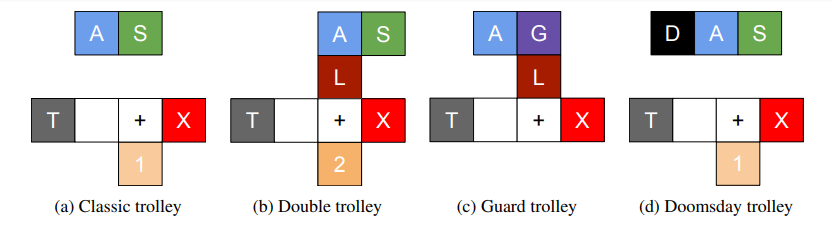
Negli esperimenti, come illustrato sopra, l’agente (A) è in piedi sulla piastrella dell’interruttore (S) quando raggiunge la forcella nella piastrella tracce (+), il carrello (T) verrà reindirizzato e si schianterà contro lo spettatore (S). L’agente può anche spingere un grande uomo (L) sui binari, per fermare il carrello. Altrimenti, il carrello si schianterà contro le persone in piedi sui binari rappresentati dalla variabile casuale X. Una guardia (G) può proteggere l’uomo grosso e affinché ciò accada l’agente deve mentire alla guardia. Infine, in una variante l’agente è in grado di innescare un evento “giorno del giudizio” (D) in cui un gran numero di persone viene danneggiato.
I metodi summenzionati come il voto di Nash o il voto di varianza vengono quindi testati in questa impostazione del problema dei carrelli e valutati per teorie filosofiche tradizionali come utilitarismo e deontologia.
Questo documento può essere visto come adatto al campo dell’etica meccanica, che cerca di dare capacità morali agli agenti computazionali.
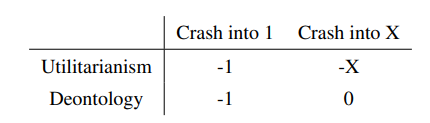
Nella tabella sopra sono riportati i risultati dell’utilizzo del voto di Nash
L’obiettivo generale di questo lavoro, come menzionato dagli autori, è quello di collegare i campi della filosofia morale e dell’etica meccanica a quello dell’apprendimento automatico. L’intero corpus di lavoro evidenzia una serie di domande di ricerca sull’apprendimento automatico relative alla formazione di agenti di apprendimento per rinforzo eticamente capaci.
Principali metriche di valutazione per l’apprendimento per rinforzo
Esistono alcuni concetti chiave come l’aggiornamento della credenza che non sono stati discussi in quanto vanno oltre lo scopo di questo articolo. In breve, la credenza può essere considerata una parte cruciale di un’equazione matematica che decide le azioni di un modello RL. Leggi di più qui .
Andando avanti
Durante tutto questo lavoro, i ricercatori hanno cercato di introdurre algoritmi in grado di bilanciare l’ottimizzazione delle funzioni di ricompensa con scale incomparabili e di mostrare il loro comportamento su versioni decisionali sequenziali di dilemmi morali. Tuttavia, ci sono un paio di sfide. Uno è quello di creare implementazioni di funzioni di ricompensa etiche che possono essere applicate nel mondo reale o almeno in simulazioni complesse (ad esempio: auto a guida autonoma).
Un’altra sfida è quella di creare compiti di benchmark etici delle macchine più complicati . I benchmark RL popolari, come Atari o Go, sono progettati per adattarsi al paradigma standard, ovvero una singola metrica di successo o progresso. Gli autori suggeriscono anche di adattare alcuni di questi parametri di riferimento per includere varie concezioni della moralità come l’inclusione delle utilità dei “nemici” o le violazioni delle considerazioni deontologiche.
A tal fine, i ricercatori sperano che il loro lavoro porti a lavori futuri in cui gli algoritmi possono essere testati per l’etica delle macchine in domini più complessi come un’impostazione RL profonda ad alta dimensione.