Ènoto che i modelli di apprendimento automatico funzionano meglio con dati su larga scala ben curati. Tuttavia, raccogliere e curare è una delle maggiori sfide al momento. Ci sono aziende da miliardi di dollari come Scale.ai che hanno aperto il loro negozio con l’unico scopo di annotare i dati. L’intero processo di raccolta dei dati è così noioso che è diventato redditizio per pochi. Ma stiamo ancora parlando di ciò che accade prima che i dati arrivino a una pipeline ML. Il rumore può insinuarsi anche in set di dati di alta qualità .
Tali informazioni possono rientrare nelle seguenti categorie:
Errori di etichettatura umana
Ingresso da luoghi o orari diversi
Hardware di acquisizione rumoroso
Ma come si valuta il valore di un singolo dato (informazioni)? La formazione di un modello sull’intero set di dati e l’utilizzo delle prestazioni di previsione in quanto il valore può essere semplice. Tuttavia, la valutazione del valore di una specifica informazione può essere complicata in set di dati su larga scala.
Al riguardo, la valutazione dei dati è cresciuta fino a diventare uno spazio ampiamente ricercato. Metriche come i valori di Shapley vengono utilizzate per decidere a quale parte dei dati dovrebbe essere data più priorità.
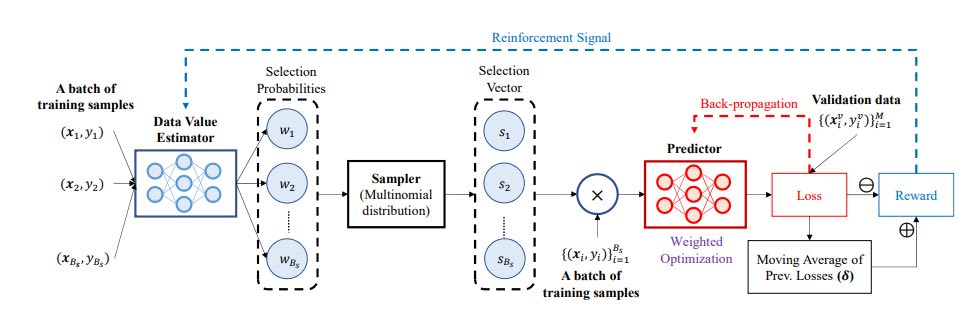
Ora, per rendere solido l’intero processo di valutazione dei dati e facilitare l’apprendimento adattivo dei valori dei dati congiuntamente al modello predittore dell’attività target, i ricercatori di Google Cloud AI e UCLA hanno proposto un framework di meta-learning: valutazione dei dati utilizzando Reinforcement Learning (DVRL) .
DVRL è uno stimatore del valore dei dati che apprende quanto è probabile che ogni informazione possa essere utilizzata nella formazione del modello predittore. Questo strumento per la stima del valore dei dati viene addestrato utilizzando un segnale di rinforzo della ricompensa, che viene ottenuto su un piccolo set di validazione che fornisce approfondimenti sull’esecuzione dell’attività target.
Invece di trattare tutti i campioni di dati allo stesso modo, questo lavoro suggerisce di assegnare determinate informazioni come una priorità inferiore per ottenere un modello di prestazioni più elevato.
Procedura dettagliata per la valutazione dei dati mediante DVRL:
Una serie di campioni di training viene alimentata con DVRL che fornisce un output, che è una probabilità di selezione di una distribuzione multinomiale
Sulla base di questa distribuzione multinomiale, il campionatore restituisce il vettore di selezione
Il modello predittore dell’attività di destinazione viene addestrato su campioni con un vettore di selezione mediante l’ottimizzazione della discesa gradiente.
I valori dei dati non sono altro che le probabilità di selezione, che classificano i campioni in base alla loro importanza
La perdita viene valutata su un piccolo set di validazione e confrontata con la media mobile delle perdite precedenti per determinare la ricompensa
Seguendo questa ricompensa, il segnale di rinforzo aggiorna lo stimatore del valore dei dati.
In breve, DVRL integra la valutazione dei dati con l’addestramento del modello predittore dell’attività target e determina una ricompensa quantificando le prestazioni, che a sua volta viene utilizzato come segnale di rinforzo per apprendere la probabilità che ciascun dato venga utilizzato nell’addestramento del modello predittore.
Gli esperimenti dimostrano che DVRL supera costantemente tutti i parametri di riferimento come Data Shapley, LOO e Influence Function. I ricercatori affermano che la tendenza alla scoperta di etichette rumorose per DVRL può essere molto vicina all’ottimale, in particolare per i set di dati per adulti, CIFAR-10 e fiori.
Key Takeaways
Questo lavoro non solo fornisce un quadro per la valutazione dei dati, ma pone anche il significato della valutazione dei dati nel suggerire migliori pratiche per la raccolta dei dati. Per le organizzazioni che vendono dati, i framework di valutazione dei dati possono aiutare a determinare il prezzo corretto basato sui valori dei sottoinsiemi di dati. Gli autori hanno scritto che potrebbe consentire nuove possibilità per costruire set di dati di training su larga scala in un modo molto più economico.
Secondo gli autori, i principali contributi possono essere riassunti come segue:
È stato proposto un nuovo framework di meta-learning per la valutazione dei dati ottimizzato con il modello predittore di attività target
Dimostrazione di come il DVRL superi significativamente i metodi concorrenti su molti set di dati di immagini, tabulari e linguistici
DVRL, a differenza dei metodi precedenti, è scalabile in set di dati di grandi dimensioni e modelli complessi e la sua complessità computazionale non dipende direttamente dalla dimensione del set di addestramento