OPENAI RILASCIA GPT-3, IL MODELLO PIÙ GRANDE FINORA
I RICERCATORI OPENAI HANNO PUBBLICATO UN DOCUMENTO CHE DESCRIVE LO SVILUPPO DI GPT-3, UN MODELLO LINGUISTICO ALL’AVANGUARDIA COMPOSTO DA 175 MILIARDI DI PARAMETRI.
Il precedente modello OpenAI GPT aveva 1,5 miliardi di parametri ed era il modello più grande di allora, che è stato presto eclissato dal Megatron di NVIDIA, con 8 miliardi di parametri seguiti dal Turing NLG di Microsoft che aveva 17 miliardi di parametri. Ora OpenAI trasforma le tabelle rilasciando un modello 10 volte più grande di Turing NLG.
Gli attuali sistemi di PNL fanno ancora fatica a imparare da alcuni esempi. Con GPT-3, i ricercatori dimostrano che il ridimensionamento dei modelli linguistici migliora notevolmente le prestazioni agnostiche, con pochi scatti, a volte persino raggiungendo la competitività con precedenti approcci di perfezionamento all’avanguardia.
Le attività di elaborazione del linguaggio naturale vanno dalla generazione di articoli alla traduzione in lingua e alla risposta a domande di prova standardizzate.
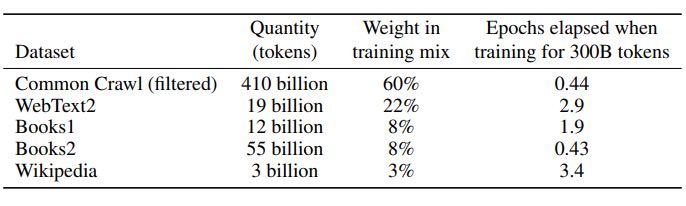
I ricercatori hanno addestrato 8 diverse dimensioni di modello che vanno da 125 milioni di parametri a 175 miliardi di parametri, l’ultimo dei quali è GPT-3.
Come GPT-3 ha trafitto altri modelli
Per GPT-3, il team di OpenAI ha utilizzato lo stesso modello e architettura di GPT-2 che include inizializzazione modificata, pre-normalizzazione e tokenizzazione reversibile insieme a schemi di attenzione sparsi densi e localmente alternati negli strati del trasformatore.
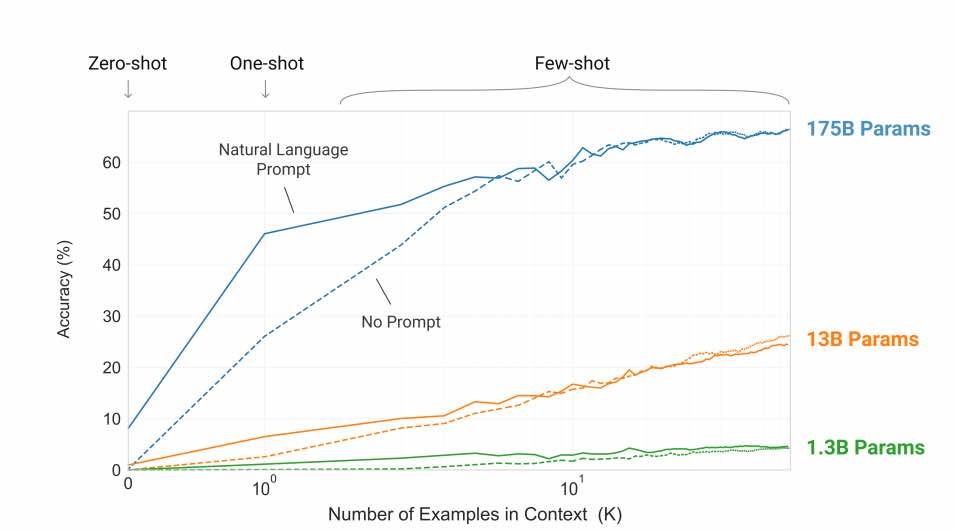
I ricercatori affermano che i modelli più grandi fanno un uso sempre più efficiente delle informazioni contestuali. Come si può vedere nella trama sopra, le “curve di apprendimento contestuali” più ripide per i modelli di grandi dimensioni mostrano una migliore capacità di apprendimento dalle informazioni contestuali.
Per la formazione, i ricercatori hanno utilizzato una combinazione di parallelismo modello all’interno di ciascuna matrice moltiplicata e parallelismo modello.
GPT-3 è stato addestrato sulle GPU V100 da parte di un cluster ad alta larghezza di banda fornito da Microsoft.