OpenAI ha recentemente presentato un innovativo approccio alla sicurezza dei modelli linguistici, denominato “allineamento deliberativo”, progettato per affrontare i tentativi di jailbreak sfruttando le capacità di ragionamento avanzato dei modelli stessi.
Il 20 dicembre 2024, durante l’evento “Shipmas”, OpenAI ha illustrato questo metodo come parte integrante del rilascio del modello “o3”. L’allineamento deliberativo si basa su due componenti principali:
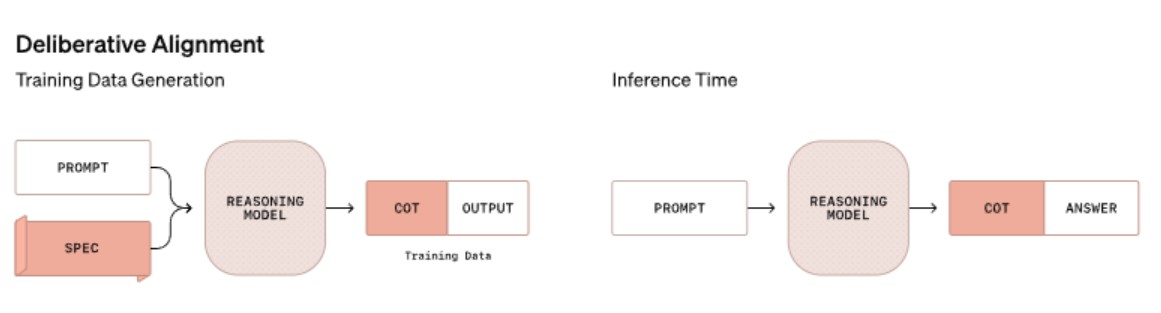
- Insegnamento Diretto delle Specifiche di Sicurezza: Il modello viene istruito utilizzando testi che delineano chiaramente le specifiche di sicurezza, redatti in linguaggio naturale comprensibile sia dagli esseri umani che dalle macchine.
- Ragionamento Prima della Risposta: Prima di fornire una risposta, il modello è addestrato a riflettere sulle specifiche di sicurezza attraverso una tecnica nota come “catena di pensieri” (Chain of Thought, CoT), assicurando che le risposte siano conformi alle linee guida di sicurezza.
Questo approccio mira a superare le limitazioni dei modelli linguistici di grandi dimensioni (LLM), che spesso forniscono risposte immediate senza una valutazione approfondita delle implicazioni di sicurezza. Tradizionalmente, i modelli deducono le regole di sicurezza attraverso l’analisi di numerosi esempi durante l’addestramento, il che può portare a interpretazioni errate o incomplete.
L’allineamento deliberativo rappresenta una novità significativa, poiché combina l’insegnamento esplicito delle regole di sicurezza con la capacità del modello di applicare tali regole attraverso un processo di ragionamento prima di generare una risposta. OpenAI sottolinea che questo metodo ha mostrato risultati superiori rispetto alle tecniche precedenti, come l’apprendimento per rinforzo con feedback umano (RLHF) o con feedback AI.
Il processo di addestramento prevede l’utilizzo di dataset contenenti prompt di sistema relativi alla sicurezza, applicando sia la messa a punto supervisionata (SFT) che l’apprendimento per rinforzo (RL). Un aspetto rilevante è l’impiego di dati sintetici, che riduce la dipendenza da dati etichettati manualmente, rendendo il processo più efficiente.
Il modello “o1” è stato il primo a implementare l’allineamento deliberativo. Nei test interni ed esterni, “o1” ha dimostrato una maggiore resistenza ai tentativi di jailbreak e una riduzione delle risposte dannose rispetto a modelli come “GPT-4o”, “Claude 3.5 Sonnet” e “Gemini 1.5 Pro”.
OpenAI riconosce che, con l’aumento dell’intelligenza e dell’autonomia dei modelli come “o1” e “o3”, cresce anche il potenziale rischio derivante da errori di allineamento o uso improprio. L’allineamento deliberativo rappresenta un passo avanti significativo negli sforzi per mitigare tali rischi, offrendo risultati promettenti per il futuro sviluppo di modelli AI sicuri e affidabili.