Più di 10 anni fa, Marc Andreesen ha pubblicato sul Wall Street Journal il suo famoso “Perché il software sta mangiando il mondo”. Spiega, dal punto di vista di un investitore, perché le società di software stanno rilevando interi settori.
In qualità di fondatore di un’azienda che abilita GraphQL all’edge , voglio condividere la mia prospettiva sul motivo per cui credo che l’edge stia effettivamente mangiando il mondo. Daremo una rapida occhiata al passato, esamineremo il presente e oseremo dare una sbirciatina al futuro sulla base delle osservazioni e del ragionamento dei primi principi.
Una breve storia delle CDN
Le applicazioni Web utilizzano il modello client-server da oltre quattro decenni. Un client invia una richiesta a un server che esegue un programma server Web e restituisce il contenuto per l’applicazione Web. Sia il client che il server sono solo computer connessi a Internet.
Nel 1998, cinque studenti del MIT hanno osservato questo e hanno avuto un’idea semplice: distribuiamo i file in molti data center in tutto il pianeta, collaborando con i fornitori di telecomunicazioni per sfruttare la loro rete. È nata l’idea di una cosiddetta rete di distribuzione dei contenuti (CDN).
I CDN hanno iniziato non solo a memorizzare immagini, ma anche file video e tutti i dati che puoi immaginare. Questi punti di presenza (PoP) sono il limite, tra l’altro. Sono server distribuiti in tutto il pianeta, a volte centinaia o migliaia di server con lo scopo di archiviare copie dei dati a cui si accede di frequente.
Sebbene l’obiettivo iniziale fosse fornire l’infrastruttura giusta e “farla funzionare”, quei CDN sono stati difficili da usare per molti anni. Una rivoluzione nell’esperienza dello sviluppatore (DX) per le CDN è iniziata nel 2014. Invece di caricare manualmente i file del tuo sito Web e poi doverli connettere con una CDN, queste due parti sono state raggruppate insieme. Servizi come surge.sh, Netlify e Vercel (fka Now) hanno preso vita.
Ormai, è uno standard assoluto del settore distribuire le risorse statiche del tuo sito Web tramite una CDN.
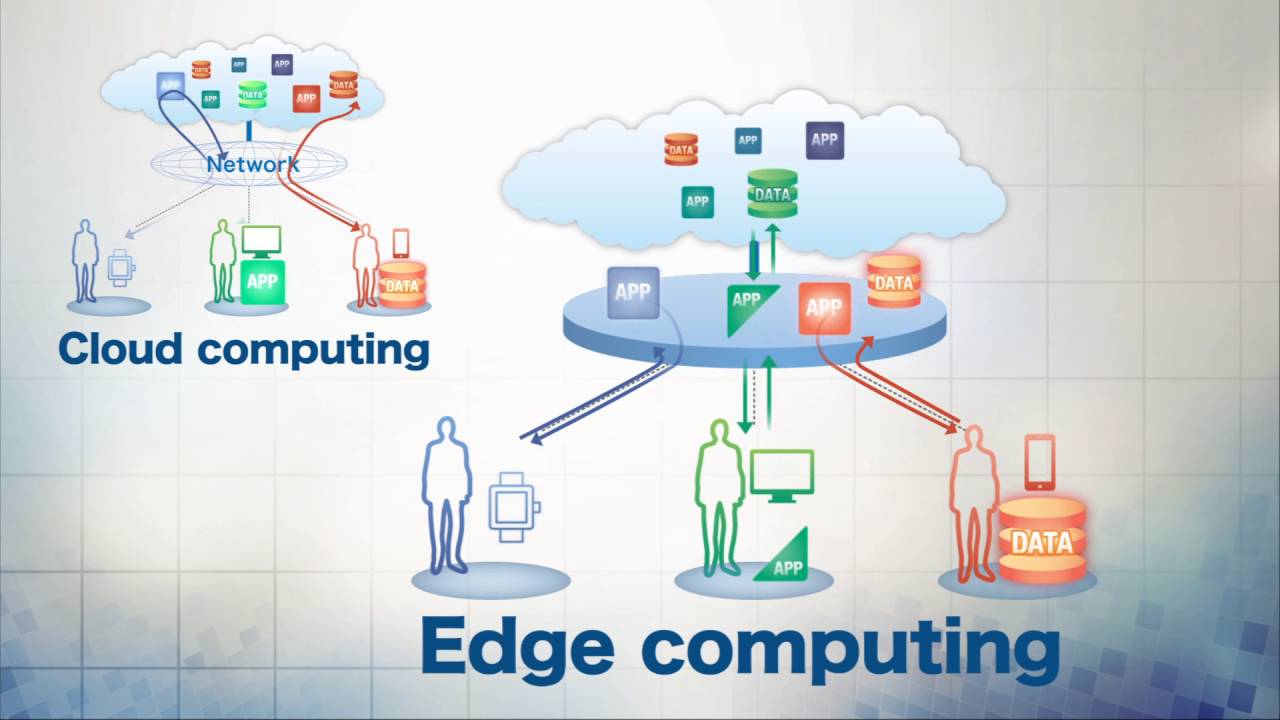
Ok, quindi ora abbiamo spostato le risorse statiche sul bordo. Ma per quanto riguarda l’informatica? E che dire dei dati dinamici archiviati nei database? Possiamo ridurre le latenze anche per questo, avvicinandolo all’utente? Se é cosi, come?
Benvenuti al limite
Diamo un’occhiata a due aspetti del bordo:
1. Calcola
e
2. Dati.
In entrambe le aree assistiamo a un’incredibile innovazione che cambierà completamente il modo in cui funzionano le applicazioni di domani.
Calcolare, dobbiamo
Cosa succede se una richiesta HTTP in entrata non deve arrivare fino al data center che vive molto, molto lontano? E se potesse essere servito direttamente accanto all’utente? Benvenuto in edge computing.
Più ci spostiamo da un data center centralizzato a molti data center decentralizzati, più dobbiamo affrontare una nuova serie di compromessi.
Invece di essere in grado di scalare su una macchina robusta con centinaia di GB di RAM per la tua applicazione, al limite, non hai questo lusso. Immagina di voler eseguire la tua applicazione in 500 edge location, tutte vicino ai tuoi utenti. L’acquisto di una macchina robusta 500 volte semplicemente non sarà economico. È semplicemente troppo costoso. L’opzione è per una configurazione più piccola e minima.
Un modello di architettura che si presta bene a questi vincoli è Serverless. Invece di ospitare tu stesso una macchina, scrivi semplicemente una funzione, che poi viene eseguita da un sistema intelligente quando necessario. Non devi più preoccuparti dell’astrazione di un singolo server: scrivi semplicemente funzioni che vengono eseguite e sostanzialmente scalabili all’infinito.
Come puoi immaginare, queste funzioni dovrebbero essere piccole e veloci. Come potremmo raggiungerlo? Qual è un buon runtime per quelle funzioni veloci e piccole?
In questo momento, ci sono due risposte popolari a questo problema nel settore: utilizzo di JavaScript V8 isolati o utilizzo di WebAssembly (WASM).
Gli isolati JavaScript V8, resi popolari in Cloudflare Workers , ti consentono di eseguire un motore JavaScript completo all’edge. Quando Cloudflare ha introdotto i lavoratori nel 2017, sono stati i primi a fornire questo nuovo modello di calcolo semplificato per l’edge.
Da allora, vari fornitori, tra cui Stackpath , Fastly e il nostro buon vecchio Akamai , hanno rilasciato anche le loro piattaforme di edge computing: è iniziata una nuova rivoluzione.
Un modello di calcolo alternativo al motore JavaScript V8 che si presta perfettamente all’edge è WebAssembly. WebAssembly, apparso per la prima volta nel 2017, è una tecnologia in rapida crescita con grandi aziende come Mozilla, Amazon, Arm, Google, Microsoft e Intel che investono molto in essa . Ti consente di scrivere codice in qualsiasi linguaggio e compilarlo in un binario portatile, che può essere eseguito ovunque, sia in un browser che in vari ambienti server.
WebAssembly è senza dubbio uno degli sviluppi più importanti per il web degli ultimi 20 anni. Alimenta già i motori di scacchi e gli strumenti di progettazione nel browser, funziona sulla Blockchain e probabilmente sostituirà Docker .
Dati
Sebbene disponiamo già di alcune offerte di edge computing, il più grande ostacolo al successo della rivoluzione perimetrale è portare i dati all’edge . Se i tuoi dati sono ancora in un data center lontano, non guadagni nulla spostando il tuo computer accanto all’utente: i tuoi dati sono ancora il collo di bottiglia. Per mantenere la promessa principale dell’edge e velocizzare le cose per gli utenti, non c’è modo di trovare soluzioni per distribuire anche i dati.
Probabilmente ti starai chiedendo: “Non possiamo semplicemente replicare i dati in tutto il pianeta nei nostri 500 data center e assicurarci che siano aggiornati?”
Sebbene ci siano nuovi approcci per replicare i dati in tutto il mondo come Litestream , che si è unito di recente a fly.io, sfortunatamente non è così facile. Immagina di avere 100 TB di dati che devono essere eseguiti in un cluster partizionato di più macchine. Copiare quei dati 500 volte semplicemente non è economico.
Sono necessari metodi per essere ancora in grado di archiviare tonnellate di dati del camion portandoli al limite.
In altre parole, con un vincolo sulle risorse, come possiamo distribuire i nostri dati in modo intelligente ed efficiente, in modo da poter avere ancora questi dati rapidamente disponibili all’edge?
In una tale situazione di risorse limitate, ci sono due metodi che l’industria sta già utilizzando (e lo fa da decenni): lo sharding e la memorizzazione nella cache.
Frammento o non frammento
Nello sharding, dividi i tuoi dati in più set di dati in base a determinati criteri. Ad esempio, selezionando il paese dell’utente per suddividere i dati, in modo da poterli archiviare in diverse geolocalizzazioni.
Raggiungere un framework di partizionamento orizzontale generale che funzioni per tutte le applicazioni è piuttosto impegnativo. Negli ultimi anni sono state fatte molte ricerche in questo settore. Facebook, ad esempio, ha inventato il suo framework di sharding chiamato Shard Manager , ma anche quello funzionerà solo in determinate condizioni e ha bisogno di molti ricercatori per farlo funzionare. Vedremo ancora molte innovazioni in questo spazio, ma non sarà l’unica soluzione per portare i dati al limite.
La cache è il re
L’altro approccio è la memorizzazione nella cache. Invece di archiviare tutti i 100 TB del mio database all’edge, posso impostare un limite, ad esempio, di 1 GB e archiviare solo i dati a cui si accede più frequentemente. Conservare solo i dati più popolari è un problema ben compreso in informatica, con l’ algoritmo LRU (utilizzato meno di recente) che è una delle soluzioni più famose qui.
Potresti chiederti: “Perché allora non usiamo tutti la memorizzazione nella cache con LRU per i nostri dati all’edge e chiamiamo un giorno?”
Beh, non così in fretta. Vogliamo che i dati siano corretti e aggiornati: in definitiva, vogliamo la coerenza dei dati. Ma aspetta! Nella coerenza dei dati, hai una gamma dei suoi punti di forza: dalla consistenza più debole o “coerenza finale” fino alla “coerenza forte”. Ci sono anche molti livelli intermedi, ad es. “Leggi la mia coerenza di scrittura”.
Il bordo è un sistema distribuito. E quando si tratta di dati in un sistema distribuito, si applicano le leggi del teorema CAP . L’idea è che dovrai fare dei compromessi se vuoi che i tuoi dati siano fortemente coerenti. In altre parole, quando vengono scritti nuovi dati, non vorrai più vedere i dati più vecchi.
Una coerenza così forte in una configurazione globale è possibile solo se le diverse parti del sistema distribuito sono unite in consenso su ciò che è appena accaduto, almeno una volta. Ciò significa che se si dispone di un database distribuito a livello globale, avrà comunque bisogno di almeno un messaggio inviato a tutti gli altri data center in tutto il mondo, il che introduce una latenza inevitabile. Persino FaunaDB, un nuovo brillante database SQL, non può aggirare questo fatto . Onestamente, non esiste un pranzo gratis: se vuoi una forte coerenza, dovrai accettare che includa un certo sovraccarico di latenza.
Ora potresti chiedere: “Ma abbiamo sempre bisogno di una forte coerenza?” La risposta è, dipende. Esistono molte applicazioni per le quali non è necessaria una forte coerenza per funzionare. Uno di questi è, ad esempio, questo piccolo negozio online di cui potresti aver sentito parlare: Amazon .
Amazon ha creato un database chiamato DynamoDB , che funziona come un sistema distribuito con capacità di scala estrema. Tuttavia, non è sempre del tutto coerente. Sebbene lo abbiano reso “il più coerente possibile” con molti trucchi intelligenti come spiegato qui , DynamoDB non garantisce una forte coerenza.
Credo che un’intera generazione di app sarà in grado di funzionare perfettamente con la coerenza finale. In effetti, probabilmente hai già pensato ad alcuni casi d’uso: i feed dei social media sono a volte leggermente obsoleti ma in genere veloci e disponibili. Blog e giornali offrono alcuni millisecondi o addirittura secondi di ritardo per gli articoli pubblicati. Come vedete, ci sono molti casi in cui l’eventuale coerenza è accettabile.
Supponiamo di stare bene con l’eventuale coerenza: cosa ci guadagniamo da ciò? Significa che non dobbiamo aspettare fino a quando un cambiamento è stato riconosciuto. Con ciò, non abbiamo più il sovraccarico di latenza durante la distribuzione dei nostri dati a livello globale.
Arrivare a una “buona” consistenza finale, però, non è neanche facile. Dovrai affrontare questo piccolo problema chiamato “invalidazione della cache”. Quando i dati sottostanti cambiano, la cache deve essere aggiornata. Sì, avete indovinato: è un problema estremamente difficile. Così difficile che è diventata una gag ricorrente nella comunità informatica.
Perche’e’cosi difficile? Devi tenere traccia di tutti i dati che hai memorizzato nella cache e dovrai invalidarli o aggiornarli correttamente una volta che l’origine dati sottostante cambia. A volte non controlli nemmeno l’origine dati sottostante. Ad esempio, immagina di utilizzare un’API esterna come l’API Stripe. Dovrai creare una soluzione personalizzata per invalidare quei dati.
In breve, ecco perché stiamo costruendo Stellate, rendendo questo difficile problema più sopportabile e persino fattibile da risolvere fornendo agli sviluppatori gli strumenti giusti. Se GraphQL, un protocollo e uno schema API fortemente tipizzati, non esistessero, sarò franco: non avremmo creato questa azienda. Solo con forti vincoli puoi gestire questo problema.
Credo che entrambi si adatteranno maggiormente a queste nuove esigenze e che nessuna singola azienda può “risolvere i dati”, ma piuttosto abbiamo bisogno che l’intero settore lavori su questo .
C’è molto altro da dire su questo argomento, ma per ora sento che il futuro in questo settore è luminoso e sono entusiasta di ciò che verrà.
Il futuro: è qui, è ora
Con tutti i progressi tecnologici e i vincoli previsti, diamo uno sguardo al futuro. Sarebbe presuntuoso farlo senza menzionare Kevin Kelly .
Allo stesso tempo, riconosco che è impossibile prevedere dove sta andando la nostra rivoluzione tecnologica, né sapere quali prodotti o aziende concrete guideranno e vinceranno in questo settore tra 25 anni. Potremmo avere aziende completamente nuove all’avanguardia, una che non è nemmeno stata creata.
Ci sono alcune tendenze che possiamo prevedere, tuttavia, perché stanno già accadendo in questo momento. Nel suo libro del 2016 Inevitable , Kevin Kelly ha discusso delle prime dodici forze tecnologiche che stanno plasmando il nostro futuro. Proprio come il titolo del suo libro, ecco otto di queste forze:
Cognizione : la cognizione delle cose, AKA rendere le cose più intelligenti. Ciò richiederà sempre più calcoli direttamente dove è necessario. Ad esempio, non sarebbe pratico eseguire la classificazione stradale di un’auto a guida autonoma nel cloud, giusto?
Flusso : avremo sempre più flussi di informazioni in tempo reale da cui le persone dipendono. Questo può anche essere critico per la latenza: immaginiamo di controllare un robot per completare un’attività. Non vuoi instradare i segnali di controllo su metà del pianeta se non necessario. Tuttavia, un flusso costante di informazioni, applicazioni di chat, dashboard in tempo reale o un gioco online non possono essere critici per la latenza e quindi devono utilizzare il vantaggio.
Proiezione: sempre più cose nella nostra vita riceveranno schermate. Dagli smartwatch ai frigoriferi e persino alla tua bilancia digitale. Con ciò, questi dispositivi saranno spesso connessi a Internet, formando la nuova generazione dell’edge.
Condivisione: la crescita della collaborazione su larga scala è inevitabile. Immagina di lavorare su un documento con un tuo amico che si trova nella stessa città. Bene, perché rimandare tutti quei dati a un data center dall’altra parte del globo? Perché non archiviare il documento proprio accanto a voi due?
Filtraggio: sfrutteremo un’intensa personalizzazione per anticipare i nostri desideri. Questo potrebbe effettivamente essere uno dei maggiori driver per l’edge computing. Poiché la personalizzazione riguarda una persona o un gruppo, è un caso d’uso perfetto per eseguire il calcolo edge accanto a loro. Accelera le cose e i millisecondi equivalgono ai profitti. Lo vediamo già utilizzato nei social network, ma stiamo vedendo anche una maggiore adozione nell’e-commerce.
Interagire: immergendoci sempre di più nel nostro computer per massimizzare il coinvolgimento, questa immersione sarà inevitabilmente personalizzata e verrà eseguita direttamente o molto vicino ai dispositivi dell’utente.
Tracciamento: il Grande Fratello è qui. Saremo più tracciati e questo è inarrestabile. Più sensori in tutto raccoglieranno tonnellate e tonnellate di dati. Questi dati non possono essere sempre trasferiti al data center centrale. Pertanto, le applicazioni del mondo reale dovranno prendere decisioni rapide in tempo reale.
Inizio: ironia della sorte, ultimo ma non meno importante, è il fattore “inizio”. Gli ultimi 25 anni sono serviti da piattaforma importante. Tuttavia, non facciamo affidamento sulle tendenze che vediamo. Abbracciamoli in modo da poter creare il massimo beneficio. Non solo per noi sviluppatori, ma per tutta l’umanità nel suo insieme. Prevedo che nei prossimi 25 anni la merda diventerà reale. Questo è il motivo per cui dico che l’edge caching sta mangiando il mondo.
Come accennato in precedenza, i problemi che i programmatori devono affrontare non saranno di competenza di un’azienda, ma richiedono l’aiuto dell’intero settore. Vuoi aiutarci a risolvere questo problema? Sto solo dicendo ciao? Rivolgiti in qualsiasi momento.