Con l’avvento delle API che offrono servizi all’avanguardia a portata di clic, la creazione di un negozio di machine learning è diventata più accessibile. Ma con una rapida democratizzazione , c’è il rischio che i giocatori non ML che hanno saltato la pistola, trovandosi in una raffica di attacchi alla privacy , di cui non si era mai sentito parlare prima.
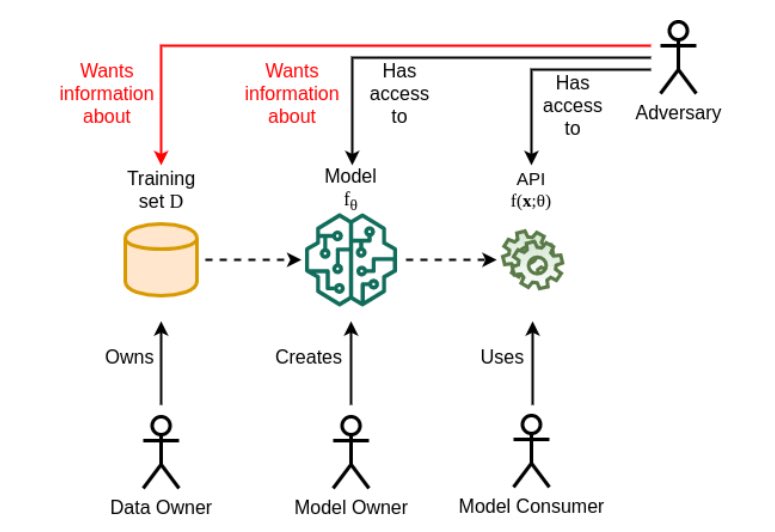
In una prima indagine condotta nel suo genere sulla privacy ML da un team dell’Università tecnica ceca, i ricercatori affrontano i diversi modi in cui un’applicazione ML può essere vulnerabile. Negli attacchi relativi alla privacy , hanno scritto i ricercatori, l’obiettivo di un avversario è legato all’acquisizione di conoscenze, non intese per essere condivise, come la conoscenza dei dati di addestramento o delle informazioni sul modello, o persino l’estrazione di informazioni sulle proprietà dei dati.
Elenchiamo di seguito alcune delle preoccupazioni sulla privacy comunemente riscontrate:
Attacchi a scatola nera
Gli attacchi a scatola nera sono quegli attacchi in cui l’avversario non conosce i parametri del modello, l’architettura o i dati di addestramento. Oggi, i dati personali vengono continuamente sfruttati dalle aziende di Internet per formare i loro modelli di apprendimento automatico che alimentano le applicazioni basate sull’apprendimento automatico. Si prevede che questi modelli non dovrebbero rivelare informazioni sui dati utilizzati per la loro formazione. Tuttavia, gli aggressori possono comunque utilizzare le informazioni che il modello ha appreso involontariamente “.
Attacchi da scatola bianca
Nel caso della scatola bianca, l’avversario ha accesso completo ai parametri del modello target o ai loro gradienti di perdita durante l’allenamento. Questo è comunemente visto nella maggior parte delle modalità di allenamento distribuite.
Tutti gli attacchi rientrano nella casella nera o nella casella bianca come la seguente:
Attacchi di inferenza sull’appartenenza
Secondo il sondaggio, questa è la categoria di attacchi più popolare. Un tipo di attacco a scatola nera viene eseguito contro modelli di apprendimento automatico supervisionati. L’inferenza di appartenenza tenta di verificare se un campione di input è stato utilizzato come parte del set di formazione. Con un migliore accesso ai parametri del modello e gradienti consentiti, migliora la precisione degli attacchi di inferenza dell’appartenenza alla casella bianca. Nel caso di modelli generativi come i GAN, l’obiettivo degli attacchi è recuperare informazioni sui dati di addestramento utilizzando vari gradi di conoscenza degli elementi generatori di dati.
Attacchi di ricostruzione
Questi attacchi provano a ricreare uno o più campioni di allenamento e / o le rispettive etichette di allenamento. Uno di questi attacchi ben documentati è la riprogrammazione contraddittoria , in cui un modello viene riproposto per eseguire una nuova attività. Un programma contraddittorio può essere considerato come un contributo aggiuntivo all’input di rete. Un offset additivo all’input di una rete neurale equivale a una modifica dei suoi pregiudizi del primo strato. Nel caso di una CNN, vengono effettivamente introdotti nuovi parametri.
Questo tipo di piccoli aggiornamenti nella rete è un programma contraddittorio. L’utente malintenzionato può tentare di riprogrammare attività con set di dati molto diversi in modo contraddittorio. Il potenziale di questi attacchi è considerevolmente elevato. Può comportare pratiche scorrette che vanno dal furto di risorse computazionali dai servizi rivolti al pubblico all’abuso di servizi di apprendimento automatico per attività che violano i principi etici dei fornitori di sistemi o persino il riproporre gli assistenti guidati dall’IA in spie o spambots.
Attacchi di inferenza proprietà
L’inferenza della proprietà è la capacità di estrarre le proprietà del set di dati che non sono state codificate esplicitamente come funzionalità o non erano correlate al compito di apprendimento. Un esempio può essere l’estrazione di informazioni sul rapporto tra donne e uomini in un set di dati di pazienti in cui le informazioni non sono etichettate.
Le informazioni estratte di solito non sono correlate all’attività di formazione e vengono apprese involontariamente dal modello. Anche modelli ben generalizzati possono apprendere proprietà che sono rilevanti per tutti i dati di input. Dal punto di vista dell’avversario, possono essere le proprietà che possono essere dedotte dal sottoinsieme specifico di dati che è stato utilizzato per la formazione o su un particolare individuo.
Attacchi di estrazione del modello
L’avversario qui è interessato a creare un sostituto che apprenda lo stesso compito del modello target, ugualmente bene o meglio. L’obiettivo dell’attacco di estrazione del modello è creare un’alternativa che replica il confine decisionale del modello nel modo più fedele possibile.
Gli attacchi di estrazione del modello possono fungere da porte per lanciare anche altri attacchi avversari. Oltre alla creazione di modelli sostitutivi, ci sono anche approcci che si concentrano sul recupero di informazioni dal modello di destinazione come iperparametri o proprietà dell’architettura delle informazioni come tipi di attivazione, algoritmo di ottimizzazione, numero di livelli, ecc.
In tutti gli attacchi discussi sopra, la gamma di conoscenze può variare dall’accesso a un’API di machine learning alla conoscenza dei parametri completi del modello e delle impostazioni di addestramento. Vi è una gamma di possibilità tra questi due estremi, come la conoscenza parziale dell’architettura del modello, i suoi iperparametri o l’impostazione dell’allenamento. Detto questo, gli autori di questo lavoro affermano che questi attacchi possono essere sfruttati per risultati positivi come il controllo dei modelli di scatole nere per verificare l’autorizzazione del proprietario dei dati.