La creazione di agenti autonomi in grado di prendere decisioni complesse e adattarsi a situazioni incerte rappresenta una sfida significativa. Un gruppo di ricercatori provenienti da istituzioni prestigiose come l’Università di Northwestern, Microsoft, Stanford e l’Università di Washington ha recentemente introdotto RAGen, un sistema innovativo progettato per migliorare l’affidabilità degli agenti AI attraverso un approccio basato sul ragionamento e sull’apprendimento per rinforzo.
RAGen (Reasoning Agent) è un framework open-source che mira a superare le limitazioni degli attuali modelli di linguaggio di grandi dimensioni (LLM) nell’affrontare compiti complessi e dinamici. A differenza degli approcci tradizionali che si concentrano su compiti statici come la risoluzione di equazioni matematiche o la generazione di codice, RAGen si focalizza su ambienti interattivi e stocastici, dove gli agenti devono prendere decisioni sequenziali e adattarsi a feedback incerti.
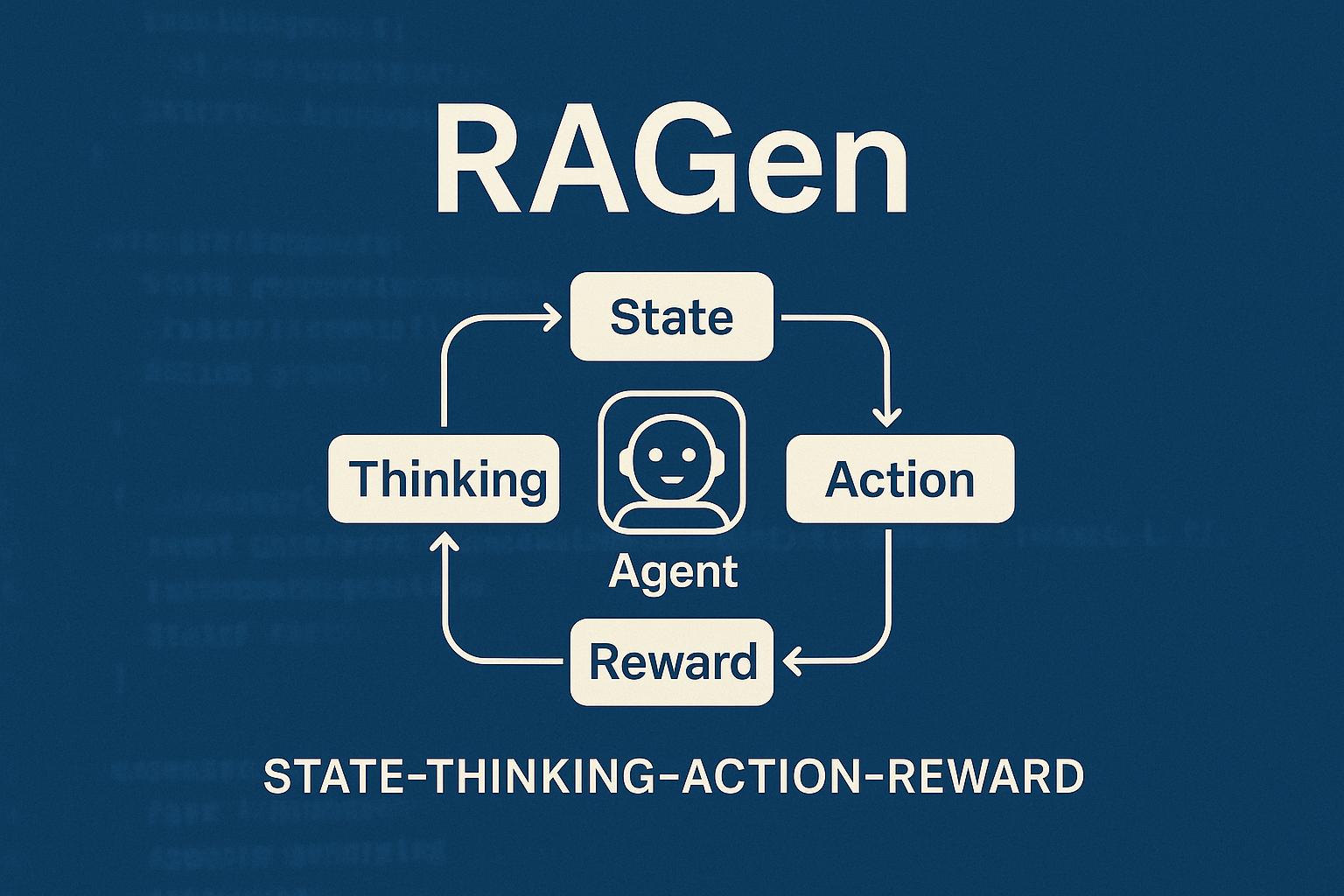
Alla base di RAGen c’è il framework StarPO (State-Thinking-Action-Reward Policy Optimization), un approccio di apprendimento per rinforzo che ottimizza intere traiettorie di interazione piuttosto che singole risposte. StarPO opera in due fasi interconnesse:
- Fase di Rollout: L’agente genera sequenze complete di interazione guidate dal ragionamento, prendendo decisioni basate su stati precedenti e obiettivi futuri.
- Fase di Aggiornamento: Le sequenze generate vengono ottimizzate utilizzando ricompense cumulative normalizzate, permettendo all’agente di apprendere dall’intera traiettoria piuttosto che da singoli passaggi.
Questo approccio consente un apprendimento più stabile e interpretabile rispetto ai metodi di ottimizzazione delle politiche tradizionali.
Il team di ricerca ha implementato e testato RAGen utilizzando varianti fine-tuned dei modelli Qwen di Alibaba, tra cui Qwen 1.5 e Qwen 2.5. Questi modelli sono stati scelti per le loro capacità robuste di seguire istruzioni e per la disponibilità dei pesi open-source, facilitando la riproducibilità e confronti consistenti tra i compiti simbolici.
I risultati hanno evidenziato che, sebbene gli agenti inizialmente generino risposte simboliche ben ragionate, nel tempo i sistemi di apprendimento per rinforzo tendono a “collassare”, perdendo la capacità di ragionare in modo coerente. Questo fenomeno, noto come “Echo Trap”, rappresenta una sfida significativa nell’addestramento di agenti AI affidabili.
RAGen offre un’importante base per lo sviluppo di agenti AI capaci di affrontare compiti complessi in ambienti reali, come la gestione della logistica, l’assistenza clienti e la pianificazione strategica. Tuttavia, rimangono alcune domande aperte riguardo alla trasferibilità dell’approccio RAGen oltre i compiti simbolici stilizzati e alla scalabilità del sistema per compiti a lungo termine o sequenze di attività in continua evoluzione.