RICONOSCIMENTO DELL’ABBIGLIAMENTO DI MODA UTILIZZANDO LA RETE NEURALE CONVOLUZIONALE
riconoscimento dell’abbigliamento moda
I recenti progressi nel deep learning hanno innescato una varietà di applicazioni aziendali basate sulla visione artificiale. Esistono molti settori industriali in cui vengono applicati strumenti e tecniche di apprendimento profondo nel riconoscimento degli oggetti per rendere il processo aziendale molto più veloce. L’industria dell’abbigliamento è una di queste. Presentando l’immagine di qualsiasi abbigliamento, il modello di apprendimento approfondito addestrato può prevedere il nome di quell’abbigliamento e questo processo può essere ripetuto a una velocità molto più elevata al fine di taggare migliaia di capi di abbigliamento in molto meno tempo con elevata precisione.
In questo articolo discuteremo del riconoscimento dell’abbigliamento di moda utilizzando il modello Convolutional Neural Network (CNN). Per addestrare il modello CNN, useremo il set di dati Fashion MNIST. Dopo una formazione di successo, il modello CNN può prevedere il nome della classe a cui appartiene un determinato capo di abbigliamento. Questo è un problema di classificazione multiclasse in cui ci sono 10 classi di abbigliamento che gli articoli saranno classificati.
Il set di dati
In questo articolo, abbiamo utilizzato il set di dati Fashion MNIST disponibile pubblicamente su Kaggle . Consiste in un set di formazione di 60.000 immagini di esempio e un set di test di 10.000 immagini di esempio. Ogni immagine nel set di dati ha le dimensioni di 28 x 28 pixel. Ogni immagine di allenamento e test appartiene a una delle classi tra cui T_shirt / top, Pantaloni, Pullover, Abito, Cappotto, Sandalo, Camicia, Sneaker, Borsa e Stivaletto. I set di dati di immagini di addestramento e test originali vengono convertiti in file CSV e resi disponibili su Kaggle.
Implementazione
Questa esecuzione viene eseguita in Google Colab e per leggere i file CSV lì, abbiamo prima caricato i file CSV su Google Drive e quindi montato l’unità utilizzando le seguenti righe di codice.
Impostazione di google drive come directory per set di dati
da google.colab import drive
drive.mount (‘/ content / gdrive’)
Una volta montato Google Drive, leggeremo la nostra formazione e testeremo i file CSV utilizzando le seguenti righe di codice.
Leggi set di dati
import panda come pd
fashion_train_df = pd.read_csv (‘gdrive / I miei file / fashion-mnist_train.csv’, sep = ‘,’)
fashion_test_df = pd.read_csv (‘gdrive / I miei dischi / fashion-mnist_test.csv’ ‘ , sep = ‘,’)
Dopo aver letto correttamente i set di dati, importeremo le altre librerie richieste.
Importazione di altre librerie richieste
import panda come pd
import numpy come np
import matplotlib.pyplot come plt
import seaborn come sns
import random
sns.set_style (“whitegrid”)
I set di dati che abbiamo letto sopra, vedremo le loro forme. Come discusso in precedenza, ci sono 60.000 esempi nel set di addestramento e 10.000 esempi nel set di test.
Shape dei dati di allenamento
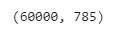
fashion_train_df.shape
Shape dei dati di test
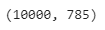
fashion_test_df.shape
Poiché le dimensioni di ciascuna immagine sono 28 x 28, vi sono quindi un totale di 784 pixel per ogni immagine e una colonna di etichetta di classe. Ecco perché un totale di 785 colonne sono presenti nel set di dati.
Ora, al fine di definire i set di dati di training e test, per prima cosa dobbiamo creare gli array di training e test.
Crea array di addestramento e test
train = np.array (fashion_train_df, dtype = ‘float32’)
test = np.array (fashion_test_df, dtype = ‘float32’)
La seguente riga di codice specifica le etichette di classe del set di dati, come indicato nella descrizione su Kaggle.
Specifying class labels class_names
= [‘T_shirt / top’, ‘Trouser’, ‘Pullover’, ‘Dress’, ‘Coat’, ‘Sandal’, ‘Shirt’, ‘Sneaker’, ‘Bag’, ‘Ankle boot’]
Ora, per procedere oltre e convalidare l’etichetta della classe, sceglieremo e tracciamo un’immagine casuale dall’insieme di 60.000 immagini di allenamento per verificarne l’etichetta corretta. Le righe di codice sottostanti possono selezionare e tracciare un’immagine diversa in modo casuale in ogni sequenza.
Visualizza un’immagine casuale per la verifica dell’etichetta di classe
i = random.randint (1.60000)
plt.imshow (train [i, 1:]. Reshape ((28,28)))
plt.imshow (train [i, 1:]. reshape ((28,28)), cmap = ‘gray’)
label_index = fashion_train_df [“label”] [i]
plt.title (f “{class_names [label_index]} “)
plt.axis (‘off’)
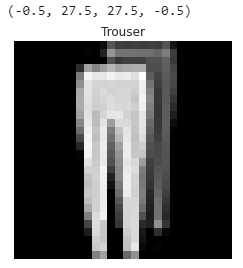
Per verificare lo stesso, vedremo l’etichetta della classe dell’immagine sopra selezionata in modo casuale e abbineremo l’etichetta al nome dell’etichetta.
Label dell’immagine casuale
label = treno [i, 0]
etichetta
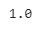
Poiché siamo confermati sull’etichetta della classe e sul nome della classe con un’immagine selezionata casualmente, ora visualizzeremo più immagini casuali con etichette e nomi di classe. Il numero di immagini da scegliere può essere regolato modificando rispettivamente i valori di larghezza e lunghezza della griglia W_grid e L_grid. Potremmo usare la trama secondaria ma restituisce l’oggetto figura e l’oggetto assi. Qui, possiamo usare l’oggetto axes per tracciare figure specifiche in varie posizioni.
Definisce le dimensioni della griglia del diagramma
W_grid = 15
L_grid = 15
fig, axes = plt.subplots (L_grid, W_grid, figsize = (17,17))
axes = axes.ravel () # appiattisce la matrice 15 x 15 in 225 array
n_train = len (train) # ottieni la lunghezza del set di dati del treno
Seleziona un numero casuale da 0 a n_train
per i in np.arange (0, W_grid * L_grid): # crea uniformemente spazi variabili
# Seleziona un numero casuale
index = = np.random.randint (0, n_train)
# legge e visualizza un’immagine con gli
assi
dell’indice selezionati [i] .imshow (train [index, 1:]. reshape ((28,28))) label_index = int (train [ index, 0])
axes [i] .set_title (class_names [label_index], fontsize = 8)
axes [i] .axis (‘off’)
plt.subplots_adjust (hspace = 0.4)

Possiamo eseguire il set di codici sopra per verificare il nome della classe per le immagini. In ogni serie verrà visualizzato un set casuale di immagini. Ora abbiamo ragione con le etichette di classe e i nomi di tutte le immagini.
Nel prossimo passo prepareremo i dati di addestramento e test.
Prepara il set di dati di addestramento e test
X_train = train [:, 1:] / 255
y_train = train [:, 0]
X_test = test [:, 1:] / 255
y_test = test [:, 0]
Visualizzeremo un insieme di 25 dati di immagini di addestramento che verranno utilizzati per addestrare il modello di rete neurale convoluzionale.
plt.figure (figsize = (10, 10))
per i nell’intervallo (25):
plt.subplot (5, 5, i + 1)
plt.xticks ([])
plt.yticks ([])
plt.grid ( Falso)
plt.imshow (X_train [i] .reshape ((28,28)), cmap = plt.cm.binary)
label_index = int (y_train [i])
plt.title (class_names [label_index])
plt.show ( )

Ai fini della formazione e della convalida, abbiamo diviso il set di dati di conseguenza. La dimensione dei dati di test può essere regolata dopo una corsa del modello.
Scrivi i set di training e test
da sklearn.model_selection import train_test_split
X_train, X_validate, y_train, y_validate = train_test_split (X_train, y_train, test_size = 0.2, random_state = 12345)
print (X_train.shape)
print (y_train.shape)
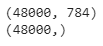
Qui, spiegheremo i dati per renderli disponibili a scopo di addestramento, test e validazione.
Disimballare l’addestramento e testare la tupla
X_train = X_train.reshape (X_train.shape [0], * (28, 28, 1))
X_test = X_test.reshape (X_test.shape [0], * (28, 28, 1) )
X_validate = X_validate.reshape (X_validate.shape [0], * (28, 28, 1))
print (X_train.shape)
print (y_train.shape)
print (X_validate.shape)

Per definire e addestrare la rete neurale convoluzionale, importeremo qui le librerie richieste.
Library for CNN Model
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
from keras.optimizers import Adam
from keras.callbacks import TensorBoard
Rete neurale convoluzionale
Nella riga di codice in basso, definiremo il nostro modello di rete neurale convoluzionale. Per maggiori informazioni sulla rete neurale convoluzionale, fare riferimento all’articolo ” Panoramica della rete neurale convoluzionale nella classificazione delle immagini “.
Definizione della rete neurale convoluzionale
cnn_model = Sequential ()
cnn_model.add (Conv2D (32, (3, 3), input_shape = (28,28,1), activation = ‘relu’))
cnn_model.add (MaxPooling2D (pool_size = (2, 2)))
cnn_model.add ( caduta di tensione (0.25))
cnn_model.add (Conv2D (64, (3, 3), input_shape = (28,28,1), activation = ‘relu’))
cnn_model.add (MaxPooling2D (pool_size = (2, 2)))
cnn_model.add ( caduta di tensione (0.25))
cnn_model.add (Conv2D (128, (3, 3), input_shape = (28,28,1), activation = ‘relu’))
cnn_model.add (MaxPooling2D (pool_size = (2, 2)))
cnn_model.add ( caduta di tensione (0.25))
cnn_model.add (Flatten ())
cnn_model.add (Dense (unità = 512, attivazione = ‘relu’))
cnn_model.add (Dropout (0.25))
cnn_model.add (Dense (unità = 10, attivazione = ‘softmax’) )
cnn_model.summary ()

Dopo aver definito il modello CNN e averne visto il riepilogo, assoceremo questo modello compilandolo.
Compiling
cnn_model.compile (loss = ‘sparse_categorical_crossentropy’, optimizer = ‘adam’, metrics = [‘accurate’ ‘])
Nel prossimo passo, formeremo il nostro modello CNN sulla classificazione delle immagini. I seguenti iperparametri possono essere regolati per una migliore precisione del modello.
Training sulla
storia del modello CNN = cnn_model.fit (X_train, y_train, batch_size = 512, epoche = 200, verbose = 1, validation_data = (X_validate, y_validate))

Dopo una formazione di successo, visualizzeremo la perdita e l’accuratezza del modello attraverso un diagramma utilizzando le righe di codice seguenti.
Visualizzazione delle prestazioni dell’allenamento
plt.figure (figsize = (12, 8))
plt.subplot (2, 2, 1)
plt.plot (history.history [‘loss’], label = ‘Loss’)
plt.plot (history.history [‘val_loss’], label = ‘val_Loss’)
plt. legend ()
plt.title (‘Loss evolution’)
plt.subplot (2, 2, 2)
plt.plot (history.history [‘accuratezza]], label =’ accuratezza ‘)
plt.plot (history.history [‘ val_accuracy ‘], label =’ val_accuracy ‘)
plt. legend ()
plt.title (‘Evoluzione della precisione’)
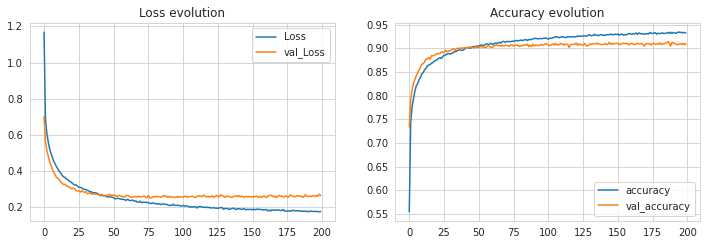
Potremmo eseguire l’addestramento su più iterazioni sintonizzando gli iperparametri per vedere un aumento della precisione del modello. Ma abbiamo trovato questo livello coerente con questi valori di iperparametro e 200 epoche di allenamento.
Dato che il modello è stato addestrato con successo e abbiamo potuto raggiungere una precisione superiore al 93% durante l’allenamento e oltre il 90% durante le convalide, riteniamo che questo modello CNN sia il più adatto ai nostri dati. Quindi ora effettueremo previsioni usando questo modello CNN sui dati di test. Il modello dovrebbe produrre etichette di classe come output della previsione.
Predictions per i dati di test
predicted_classes = cnn_model.predict_classes (X_test)
test_img = previsione X_test [0]
= previsione cnn_model.predict (test_img)
[0]

np.argmax (predizione [0])
Come possiamo vedere sopra, il modello ha previsto l’etichetta di classe 0 per l’immagine fornita. Ora controlleremo la previsione su più immagini. Stiamo acquisendo 49 immagini come set di test e predicendo le loro etichette di classe e confrontando le etichette di classe previste con etichette di classe reali.
L = 7
W = 7
fig, assi = plt.subplots (L, W, figsize = (18,18))
assi = axes.ravel ()
per i in np.arange (0, L * W):
assi [i] .imshow (X_test [i] .reshape (28,28))
assi [i] .set_title (f “Classe di previsione = {predicted_classes [i] : 0.1f} \ n True Class = {y_test [i]: 0.1f} “)
assi [i] .axis (‘off’)
plt.subplots_adjust (wspace = 0.5)

Per la limitazione della finestra, abbiamo preso solo 7 x 7 = 49 immagini, ma si possono prendere più immagini per prevedere le etichette delle classi. Come possiamo vedere nella visualizzazione sopra, per tutte le 49 immagini, il nostro modello CNN ha previsto etichette di classe corrette per 45 immagini e etichette di classe errate per 4 immagini.
Per una migliore comprensione, visualizziamo la classificazione totale effettuata dal modello utilizzando matrici di confusione. Per una migliore visualizzazione della matrice di confusione, per prima cosa definiremo le etichette della classe e quindi creeremo la matrice di confusione.
class_names = [‘T_shirt / top’, ‘Trouser’, ‘Pullover’, ‘Dress’, ‘Coat’, ‘Sandal’, ‘Shirt’, ‘Sneaker’, ‘Bag’, ‘Ankle boot’]
da sklearn.metrics import confusion_matrix
da sklearn import metrics
cm = metrics.confusion_matrix (y_test, predicted_classes)
Per una migliore visualizzazione della matrice di confusione, qui viene utilizzata una funzione ‘plot_confusion_matrix’ .
Definizione della funzione per il diagramma della matrice di confusione
def plot_confusion_matrix (y_true, y_pred, classes,
normalize = False,
title = None,
cmap = plt.cm.Blues):
“” ”
Questa funzione stampa e traccia la matrice di confusione. La
normalizzazione può essere applicata da impostando normalize = True.
” “”
se non titolo:
se normalizza:
titolo = ‘Matrice di confusione normalizzata’
altrimenti:
titolo = ‘Matrice di confusione, senza normalizzazione’
# Calcola matrice di confusione
cm = matrice di confusione (y_true, y_pred) se normalizza:
cm = cm.astype (‘float’) / cm.sum (axis = 1) [:, np.newaxis]
print (“Matrix di confusione normalizzata”)
altrimenti :
print (‘Matrice di confusione, senza normalizzazione’)
print (cm)
fig, ax = plt.subplots (figsize = (10,10))
im = ax.imshow (cm, interpolazione = 'più vicino', cmap = cmap)
ax.figure.colorbar (im, ax = ax)
# Vogliamo mostra tutti i
segni di spunta … ax.set (xticks = np.arange (cm.shape [1]), yticks = np.arange (cm.shape [0]),
# … ed etichettali con le rispettive voci dell’elenco
xticklabels = classi, yticklabels = classi,
titolo = titolo,
ylabel = ‘Etichetta vera’,
xlabel = ‘Etichetta prevista’)
# Ruota le etichette dei tick e imposta il loro allineamento.
plt.setp (ax.get_xticklabels (), rotazione = 45, ha = "destra",
rotation_mode = "anchor")
# Passa sopra le dimensioni dei dati e crea annotazioni di testo.
fmt = '.2f' se normalizza altrimenti 'd'
trebbia = cm.max () / 2.
per i nell'intervallo (cm.shape [0]):
per j nell'intervallo (cm.shape [1]):
ax. testo (j, i, formato (cm [i, j], fmt),
ha = "center", va = "center",
color = "white" se cm [i, j]> trebbia "nero")
fig .tight_layout ()
restituisce axOra, chiamando la funzione sopra, visualizzeremo una matrice di confusione non normalizzata o vedremo il numero esatto di classificazioni corrette e errate.
plt.figure (figsize = (20,20))
plot_confusion_matrix (y_test, predicted_classes, classes = class_names, title = ‘Matrice di confusione normalizzata’)
plt.axis (‘off’)

Allo stesso modo, possiamo visualizzare la stessa matrice di confusione in una forma normalizzata per vedere la percentuale di classificazioni corrette e non corrette dal modello.
plt.figure (figsize = (20,20))
plot_confusion_matrix (y_test, predicted_classes, classes = class_names, normalize = True, title = ‘Normalized Confusion matrix’)
plt.axis (‘off’)

Come possiamo vedere nella matrice di confusione sopra, il nostro modello ha dato la massima precisione del 99% nel riconoscimento delle borse, del 98% nel riconoscimento dei pantaloni e così via. Il modello ha dato la precisione più bassa del 79% nel riconoscimento delle camicie. Nel riconoscere capi di abbigliamento di oltre 6 classi su 10, ha dato una precisione superiore al 90% e un’accuratezza superiore all’85% nel riconoscimento di capi di abbigliamento di 9 classi. Questo livello di precisione nel riconoscimento degli oggetti è decisamente elevato. In ulteriori articoli, verificheremo la stessa accuratezza del riconoscimento utilizzando modelli diversi.