Tre tecniche di machine learning per preservare la privacy che risolvono il problema più importante di questo decennio
La privacy dei dati, secondo gli esperti in un’ampia gamma di domini, sarà la questione più importante di questo decennio . Ciò è particolarmente vero per l’apprendimento automatico (ML) in cui gli algoritmi vengono alimentati con risme di dati.
Tradizionalmente, le tecniche di modellazione ML si basavano sulla centralizzazione dei dati da più origini in un unico data center. Dopo tutto, i modelli ML raggiungono il massimo della loro potenza quando hanno accesso a enormi quantità di dati. Tuttavia, questa tecnica comporta una serie di sfide per la privacy. L’aggregazione di dati diversi da più fonti è oggi meno fattibile a causa di preoccupazioni normative come HIPAA, GDPR e CCPA. Inoltre, la centralizzazione dei dati aumenta la portata e la portata dell’uso improprio dei dati e delle minacce alla sicurezza sotto forma di fughe di dati.
Per superare queste sfide, sono stati sviluppati diversi pilastri dell’apprendimento automatico per la conservazione della privacy (PPML) con tecniche specifiche che riducono il rischio per la privacy e garantiscono che i dati rimangano ragionevolmente sicuri. Ecco alcuni dei più importanti:
- Apprendimento federato
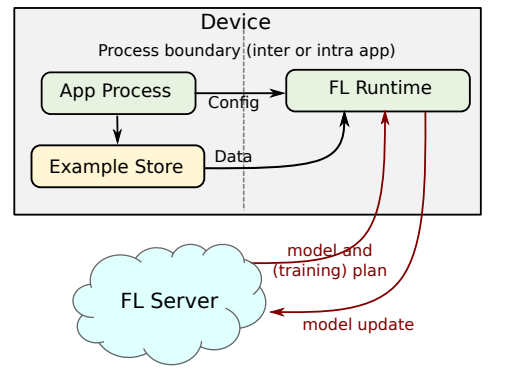
L’apprendimento federato è una tecnica di formazione ML che capovolge il problema dell’aggregazione dei dati. Invece di aggregare i dati per creare un singolo modello ML, l’apprendimento federato aggrega i modelli ML stessi. Ciò garantisce che i dati non lascino mai la posizione di origine e consente a più parti di collaborare e creare un modello ML comune senza condividere direttamente i dati sensibili.
Funziona così. Si inizia con un modello ML di base che viene quindi condiviso con ogni nodo client. Questi nodi eseguono quindi l’addestramento locale su questo modello utilizzando i propri dati. Gli aggiornamenti del modello vengono periodicamente condivisi con il nodo coordinatore, che li elabora e li fonde insieme per ottenere un nuovo modello globale. In questo modo, ottieni le informazioni da diversi set di dati senza dover condividere questi set di dati.
Nel contesto dell’assistenza sanitaria, questo è uno strumento incredibilmente potente e attento alla privacy per mantenere i dati dei pazienti al sicuro, offrendo ai ricercatori la saggezza della folla. Non aggregando i dati, l’apprendimento federato crea un ulteriore livello di sicurezza. Tuttavia, i modelli e gli aggiornamenti dei modelli stessi presentano ancora un rischio per la sicurezza se lasciati vulnerabili.
- Privacy differenziale
I modelli ML sono spesso bersagli di attacchi di inferenza sull’appartenenza. Supponi di condividere i tuoi dati sanitari con un ospedale per aiutare a sviluppare un vaccino contro il cancro. L’ospedale protegge i tuoi dati, ma utilizza l’apprendimento federato per addestrare un modello ML pubblicamente disponibile. Alcuni mesi dopo, gli hacker utilizzano un attacco di inferenza sull’appartenenza per determinare se i tuoi dati sono stati utilizzati o meno nella formazione del modello. Quindi trasmettono le informazioni a una compagnia di assicurazioni che, in base al rischio di cancro, potrebbe aumentare i premi.
La privacy differenziale garantisce che gli attacchi avversari ai modelli ML non saranno in grado di identificare punti dati specifici utilizzati durante l’addestramento, mitigando così il rischio di esporre dati di addestramento sensibili nell’apprendimento automatico. Ciò viene fatto applicando il “rumore statistico” per perturbare i dati oi parametri del modello di apprendimento automatico durante l’addestramento dei modelli, rendendo difficile eseguire attacchi e determinare se i dati di un particolare individuo sono stati utilizzati per addestrare il modello.
Ad esempio, Facebook ha recentemente rilasciato Opacus , una libreria ad alta velocità per l’addestramento di modelli PyTorch utilizzando un algoritmo di apprendimento automatico basato sulla privacy differenziale chiamato Differentially Private Stochastic Gradient Descent (DP-SGD). La gif seguente evidenzia come utilizza il rumore per mascherare i dati.
Questo rumore è regolato da un parametro chiamato Epsilon. Se il valore Epsilon è basso, il modello ha una perfetta privacy dei dati ma scarsa utilità e precisione. Al contrario, se si dispone di un valore Epsilon elevato, la privacy dei dati diminuirà mentre la precisione aumenta. Il trucco sta nel trovare un equilibrio per ottimizzare per entrambi.
- Crittografia omomorfica
La crittografia standard è tradizionalmente incompatibile con l’apprendimento automatico perché una volta che i dati sono crittografati non possono più essere compresi dall’algoritmo ML. Tuttavia, la crittografia omomorfica è uno schema di crittografia speciale che ci consente di continuare a eseguire determinati tipi di calcoli.
Il potere di questo è che la formazione può avvenire in uno spazio interamente criptato. Non solo protegge i proprietari dei dati, ma protegge anche i proprietari dei modelli. Il proprietario del modello può eseguire inferenze sui dati crittografati senza mai vederli o utilizzarli in modo improprio.
Quando applicato all’apprendimento federato, la fusione degli aggiornamenti del modello può avvenire in modo sicuro perché si svolgono in un ambiente completamente crittografato, riducendo drasticamente il rischio di attacchi di inferenza sull’appartenenza.
Il decennio della privacy
All’inizio del 2021, l’apprendimento automatico per la tutela della privacy è un campo emergente con una ricerca notevolmente attiva. Se l’ultimo decennio è stato incentrato sulla rimozione dei silos di dati, questo decennio riguarderà i modelli di ML non silos conservando la privacy dei dati sottostanti tramite l’apprendimento federato, la privacy differenziale e la crittografia omomorfica. Questi rappresentano un modo nuovo e promettente per far progredire le soluzioni di apprendimento automatico in modo attento alla privacy.