Cos’è l’adattamento di basso rango (LoRA)?
Nell’ambito dei modelli di linguaggio di grandi dimensioni (LLM), l’addestramento, il tuning e l’esecuzione possono essere costosi. In passato, si pensava che solo modelli con centinaia di miliardi di parametri, addestrati con un calcolo del valore di milioni di dollari, potessero competere con le capacità di GPT-3.5 e ChatGPT.
Tuttavia, i recenti sviluppi di LLM open source hanno dimostrato che non sono necessari modelli estremamente grandi per raggiungere prestazioni all’avanguardia. I ricercatori hanno addestrato LLM con “solo” alcuni miliardi di parametri e hanno ottenuto risultati paragonabili a quelli di modelli molto più grandi. Questo ha suscitato un crescente interesse e attività nel settore dei modelli di linguaggio.
Alcuni dei recenti sforzi si sono concentrati su come rendere più efficiente e conveniente il tuning dei LLM. Una delle tecniche che ha contribuito notevolmente a ridurre i costi di tuning è chiamata “adattamento di basso rango” (LoRA). Con LoRA, è possibile ottenere il tuning dei LLM a una frazione del costo che richiederebbe normalmente.
Ecco cosa dovresti sapere su LoRA.
Come funziona il tuning dei LLM? I LLM open source come LLaMA, Pythia e MPT-7B sono modelli di base che sono stati pre-addestrati su centinaia di miliardi di parole. Gli sviluppatori e gli ingegneri di machine learning possono scaricare questi modelli pre-addestrati e perfezionarli per compiti specifici, come seguire istruzioni o svolgere altre attività.
Ogni LLM è composto da vari blocchi di livelli, noti come “trasformatori”, ciascuno dei quali contiene parametri apprendibili. Il processo di tuning parte dal punto in cui si era interrotto il pre-addestramento. Durante il tuning, il modello viene alimentato con un set di dati specifico e genera previsioni sui token successivi, confrontandole con i valori di verità fondamentali. I pesi vengono quindi regolati per correggere le previsioni. Questo processo viene ripetuto più volte finché il LLM si adatta perfettamente al compito specifico.
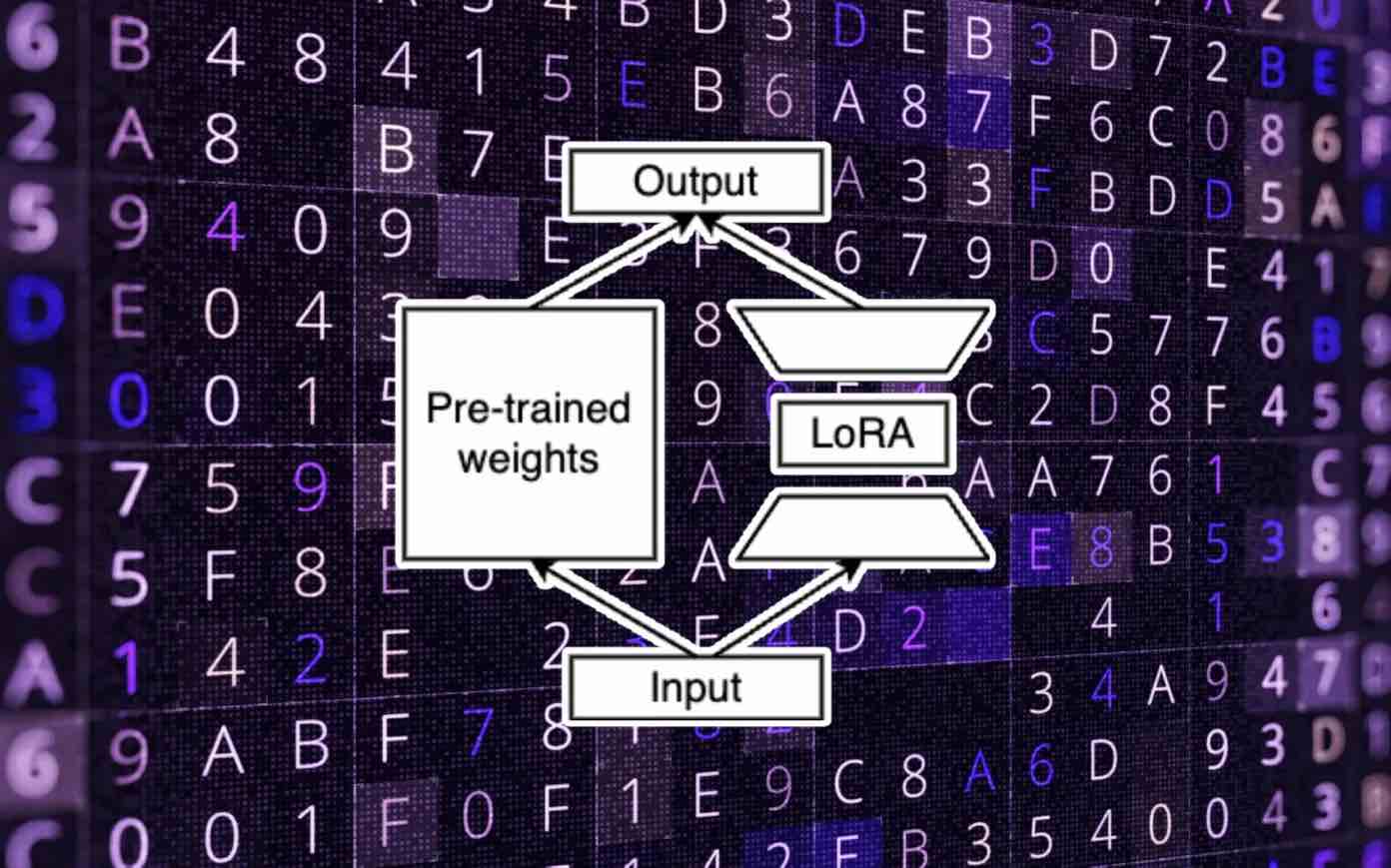
Il tuning dei LLM con LoRA Nel tuning classico di un modello di machine learning (ML), si ottimizzano i pesi originali del modello per adattarlo al compito specifico. Tuttavia, con LoRA, si apporta una piccola modifica a questo processo. Invece di modificare direttamente i pesi originali, si applicano le modifiche a un insieme separato di pesi e si aggiungono i nuovi valori ai parametri originali. Questi due set di pesi vengono chiamati “pre-addestrati” e “regolati”.
La separazione dei pesi pre-addestrati e regolati è un aspetto fondamentale di LoRA.
LoRA si basa sul concetto di “basso rango” dei parametri del modello. Ogni matrice di pesi può essere vista come uno spazio vettoriale con molte dimensioni che modella il linguaggio. Ogni matrice ha un “rango”, che rappresenta il numero di colonne linearmente indipendenti che contiene. Le colonne linearmente indipendenti non possono essere rappresentate come combinazione lineare di altre colonne nella stessa matrice. In altre parole, possono essere rimosse senza perdere informazioni.
LoRA propone di non utilizzare una matrice di peso a rango completo durante il tuning di un LLM per un compito specifico. Invece, si conserva la maggior parte della capacità di apprendimento del modello riducendo al contempo la dimensione dei parametri utilizzati per il compito specifico. (Ecco perché è importante separare i pesi pre-addestrati da quelli regolati.)
Nell’adattamento di basso rango, si creano due matrici di pesi: una che trasforma i parametri di input dalla dimensione originale a una dimensione di basso rango e un’altra che trasforma i dati di basso rango alle dimensioni di output del modello originale. Durante il training, si apportano modifiche solo ai pesi di basso rango, che sono molto più piccoli rispetto ai pesi originali. Di conseguenza, il tuning può essere eseguito molto più velocemente e a una frazione del costo di un tuning completo. Durante l’inferenza, l’output del modello con LoRA viene sommato ai pesi pre-addestrati per calcolare i valori finali.
Miglioramenti aggiuntivi con LoRA Poiché LoRA richiede di mantenere separatamente i pesi pre-addestrati e quelli regolati, ciò comporta un sovraccarico di memoria. Inoltre, l’operazione di somma dei pesi pre-addestrati e regolati durante l’inferenza comporta un certo costo computazionale. Per mitigare queste problematiche, è possibile unire i pesi regolati e pre-addestrati dopo aver completato il tuning con LoRA.
Tuttavia, poiché i pesi regolati occupano solo una frazione dei pesi originali (a volte fino a un millesimo), è consigliabile mantenerli separati. Questa separazione offre vantaggi, ad esempio, quando si desidera utilizzare lo stesso LLM per diverse applicazioni o clienti. Invece di creare una versione ottimizzata separata del modello per ogni cliente, è possibile utilizzare LoRA per creare un set di pesi regolati specifici per ogni cliente o applicazione. Durante l’inferenza, è sufficiente caricare il modello di base e i pesi LoRA di ogni cliente per eseguire i calcoli finali. Anche se si avrà una leggera diminuzione delle prestazioni, i vantaggi in termini di spazio di archiviazione saranno considerevoli.
Implementazione di LoRA in Python Questo articolo è solo un’introduzione generale al funzionamento di LoRA. Esistono ulteriori dettagli e sfumature tecniche da considerare, come i tipi di pesi a cui può essere applicato e gli iperparametri da utilizzare. Puoi trovare maggiori informazioni e una guida tecnica sull’implementazione di LoRA da Sebastian Raschka.
Chris Alexiuk ha anche realizzato una serie di video in due parti su LoRA, con un focus sulla teoria e un’implementazione pratica utilizzando Python e Google Colab.
LoRA è solo una delle numerose tecniche che possono contribuire a ridurre i costi del tuning dei modelli di linguaggio open source. Il campo dei modelli di linguaggio sta evolvendo rapidamente e sarà interessante vedere come si svilupperanno ulteriormente queste tecniche.