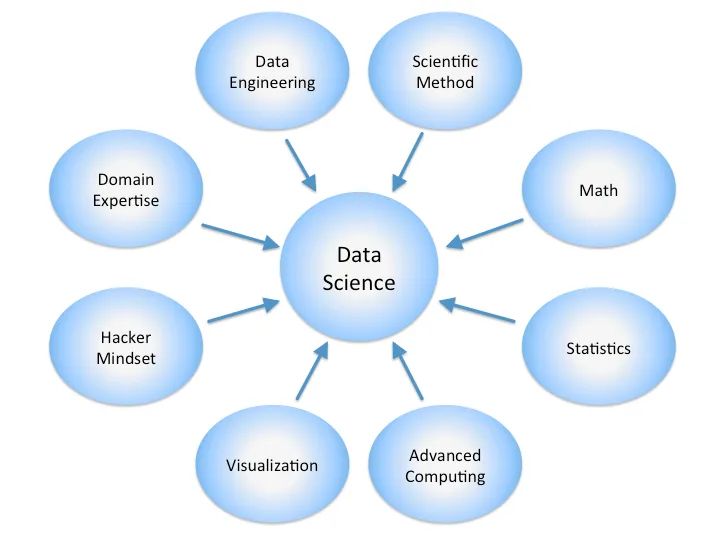
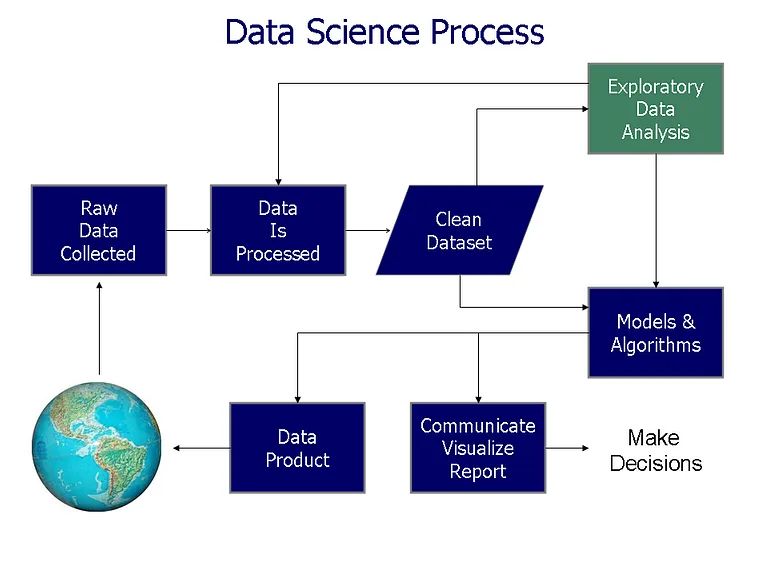
Il campo della scienza dei dati sembra diventare sempre più grande e più popolare ogni giorno. Secondo LinkedIn, la scienza dei dati è stata uno dei campi di lavoro in più rapida crescita nel 2017 e nel 2020 Glassdoor ha classificato il lavoro di scienza dei dati come uno dei tre migliori lavori negli Stati Uniti . Data la crescente popolarità della scienza dei dati, non sorprende che sempre più persone si interessino al settore. Ma cos’è esattamente la scienza dei dati?
Conosciamo la scienza dei dati, prendendoci del tempo per definire la scienza dei dati, esplorando come i big data e l’intelligenza artificiale stanno cambiando il campo, impariamo alcuni strumenti comuni di scienza dei dati ed esaminiamo alcuni esempi di scienza dei dati.
Definizione della scienza dei dati
Prima di poter esplorare qualsiasi strumento o esempio di data science, vorremmo ottenere una definizione concisa di data science .
Definire “data science” è in realtà un po ‘complicato, perché il termine viene applicato a molti compiti e metodi diversi di indagine e analisi. Possiamo iniziare ricordandoci cosa significa il termine “scienza”. La scienza è lo studio sistematico del mondo fisico e naturale attraverso l’osservazione e la sperimentazione, con l’obiettivo di far progredire la comprensione umana dei processi naturali. Le parole importanti in quella definizione sono “osservazione” e “comprensione”.
Se la scienza dei dati è il processo di comprensione del mondo dai modelli nei dati, la responsabilità di uno scienziato dei dati è quella di trasformare i dati, analizzare i dati ed estrarre i modelli dai dati. In altre parole, a uno scienziato di dati vengono forniti i dati e utilizzano una serie di strumenti e tecniche diversi per preelaborare i dati (prepararli per l’analisi) e quindi analizzare i dati per modelli significativi.
Il ruolo di uno scienziato di dati è simile al ruolo di uno scienziato tradizionale. Entrambi si occupano dell’analisi dei dati per supportare o rifiutare le ipotesi su come opera il mondo, cercando di dare un senso ai modelli dei dati per migliorare la nostra comprensione del mondo. I data scientist utilizzano gli stessi metodi scientifici di uno scienziato tradizionale. Uno scienziato di dati inizia raccogliendo osservazioni su alcuni fenomeni che vorrebbero studiare. Quindi formulano un’ipotesi sul fenomeno in questione e cercano di trovare dati che annullano in qualche modo la loro ipotesi.
Se l’ipotesi non è contraddetta dai dati, potrebbero essere in grado di costruire una teoria, o un modello, su come funziona il fenomeno, che possono continuare a testare ancora e ancora vedendo se vale per altri set di dati simili. Se un modello è sufficientemente robusto, se spiega bene i modelli e non viene annullato durante altri test, può anche essere usato per prevedere le occorrenze future di quel fenomeno.
Uno scienziato di dati in genere non raccoglierà i propri dati attraverso un esperimento. Di solito non progettano esperimenti con controlli e prove in doppio cieco per scoprire variabili confondenti che potrebbero interferire con un’ipotesi. La maggior parte dei dati analizzati da uno scienziato di dati saranno dati ottenuti attraverso studi e sistemi di osservazione, il che è un modo in cui il lavoro di uno scienziato di dati potrebbe differire da quello di uno scienziato tradizionale, che tende a svolgere più esperimenti.
Detto questo, uno scienziato di dati potrebbe essere chiamato a fare una forma di sperimentazione chiamata test A / B in cui vengono apportate modifiche a un sistema che raccoglie i dati per vedere come cambiano i modelli di dati.
Indipendentemente dalle tecniche e dagli strumenti utilizzati, la scienza dei dati mira in definitiva a migliorare la nostra comprensione del mondo dando un senso ai dati, e i dati vengono acquisiti attraverso l’osservazione e la sperimentazione. La scienza dei dati è il processo di utilizzo di algoritmi, principi statistici e vari strumenti e macchine per estrarre intuizioni dai dati, intuizioni che ci aiutano a comprendere i modelli nel mondo che ci circonda.
Cosa fanno i data scientist?
Potresti vedere che qualsiasi attività che comporta l’analisi dei dati in modo scientifico può essere definita scienza dei dati, che è parte di ciò che rende così difficile la definizione della scienza dei dati. Per chiarire meglio, esploriamo alcune delle attività che uno scienziato di dati potrebbe svolgere quotidianamente.
La scienza dei dati riunisce molte discipline e specialità diverse. Foto: Calvin Andrus via Wikimeedia Commons, CC BY SA 3.0 (https://commons.wikimedia.org/wiki/File:DataScienceDisciplines.png)
In un dato giorno, un data scientist potrebbe essere invitato a: creare uno schema di archiviazione e recupero dei dati, creare pipeline di dati ETL (estrarre, trasformare, caricare) e ripulire i dati, impiegare metodi statistici, creare visualizzazioni e dashboard dei dati, implementare intelligenza artificiale e algoritmi di apprendimento automatico, formulare raccomandazioni per azioni basate sui dati.
Rompiamo un po ‘le attività sopra elencate.
Archiviazione, recupero, ETL e pulizia dei dati
A un data scientist potrebbe essere richiesto di gestire l’installazione delle tecnologie necessarie per archiviare e recuperare i dati, prestando attenzione sia all’hardware che al software. La persona responsabile di questa posizione può anche essere definita ” Ingegnere dei dati “. Tuttavia, alcune aziende includono queste responsabilità sotto il ruolo di data scientist. Uno scienziato di dati potrebbe anche aver bisogno di creare o aiutare nella creazione di condotte ETL . I dati molto raramente vengono formattati proprio come necessita uno scienziato di dati. Invece, i dati dovranno essere ricevuti in una forma grezza dall’origine dati, trasformati in un formato utilizzabile e preelaborati (cose come standardizzare i dati, eliminare le ridondanze e rimuovere i dati danneggiati).
Metodi statistici
L’ applicazione della statistica è necessaria per trasformare semplicemente guardando i dati e interpretandoli in una vera scienza. I metodi statistici vengono utilizzati per estrarre modelli rilevanti dai set di dati e uno scienziato di dati deve avere una buona conoscenza dei concetti statistici. Devono essere in grado di discernere le correlazioni significative dalle correlazioni spurie controllando le variabili confondenti. Devono inoltre conoscere gli strumenti giusti da utilizzare per determinare quali funzionalità nel set di dati sono importanti per il loro modello / hanno un potere predittivo. Uno scienziato di dati deve sapere quando utilizzare un approccio di regressione rispetto a un approccio di classificazione e quando preoccuparsi della media di un campione rispetto alla mediana di un campione. Uno scienziato di dati non sarebbe uno scienziato senza queste abilità cruciali.
Visualizzazione dati
Una parte cruciale del lavoro di uno scienziato di dati consiste nel comunicare le proprie scoperte ad altri. Se uno scienziato di dati non è in grado di comunicare efficacemente le proprie scoperte ad altri, le implicazioni delle loro scoperte non contano. Uno scienziato di dati dovrebbe anche essere un narratore efficace. Ciò significa produrre visualizzazioni che comunichino punti rilevanti sul set di dati e sui modelli scoperti al suo interno. Esiste un gran numero di diversi strumenti di visualizzazione dei dati che uno scienziato di dati potrebbe utilizzare e possono visualizzare i dati ai fini dell’esplorazione iniziale e di base (analisi dei dati esplorativi) o visualizzare i risultati prodotti da un modello.
Consigli e applicazioni aziendali
Uno scienziato di dati deve avere una certa intuizione dei requisiti e degli obiettivi della propria organizzazione o attività. Uno scienziato di dati deve comprendere queste cose perché deve sapere quali tipi di variabili e caratteristiche dovrebbero analizzare, esplorando modelli che aiuteranno la loro organizzazione a raggiungere i suoi obiettivi. I data scientist devono essere consapevoli dei vincoli che stanno operando e delle ipotesi che la leadership dell’organizzazione sta facendo.
Apprendimento automatico e intelligenza artificiale
Gli algoritmi e i modelli di machine learning e di intelligenza artificiale sono strumenti utilizzati dai data scientist per analizzare i dati, identificare i modelli all’interno dei dati, discernere le relazioni tra le variabili e fare previsioni sugli eventi futuri.
Data Science tradizionale vs. Big Data Science
Man mano che i metodi di raccolta dei dati sono diventati più sofisticati e le banche dati più grandi, è emersa una differenza tra la scienza dei dati tradizionale e la scienza dei “big data” .
L’analisi dei dati tradizionale e la scienza dei dati vengono eseguite con analisi descrittive ed esplorative, con l’obiettivo di trovare modelli e analizzare i risultati delle prestazioni dei progetti. I metodi tradizionali di analisi dei dati spesso si concentrano solo sui dati passati e sui dati attuali. Gli analisti di dati spesso si occupano di dati che sono già stati ripuliti e standardizzati, mentre i data scientist si occupano spesso di dati complessi e sporchi. L’analisi dei dati e le tecniche di data science più avanzate potrebbero essere utilizzate per prevedere il comportamento futuro, sebbene ciò sia più spesso fatto con i big data, poiché i modelli predittivi spesso necessitano di grandi quantità di dati per essere costruiti in modo affidabile.
“Big data” si riferisce a dati che sono troppo grandi e complessi per essere gestiti con analisi e tecniche scientifiche tradizionali e strumenti e strumenti. I big data vengono spesso raccolti attraverso piattaforme online e vengono utilizzati strumenti avanzati di trasformazione dei dati per rendere i grandi volumi di dati pronti per l’ispezione da parte della scienza dei dati. Man mano che vengono raccolti più dati in ogni momento, un lavoro di data scientist comporta più analisi dei big data.
Strumenti di scienza dei dati
Gli strumenti comuni per la scienza dei dati includono strumenti per l’archiviazione dei dati, l’esecuzione di analisi esplorative dei dati, modelli di dati, esecuzione di ETL e visualizzazione dei dati. Piattaforme come Amazon Web Services, Microsoft Azure e Google Cloud offrono tutti strumenti per aiutare i data scientist a archiviare, trasformare, analizzare e modellare i dati. Esistono anche strumenti di data science indipendenti come Airflow (infrastruttura dati) e Tableau (visualizzazione e analisi dei dati).
In termini di algoritmi di machine learning e intelligenza artificiale usati per modellare i dati, vengono spesso forniti attraverso moduli e piattaforme di data science come TensorFlow, PyTorch e Azure Machine-learning studio. Queste piattaforme, come i data scientist, apportano modifiche ai loro set di dati, compongono architetture di machine learning e addestrano modelli di machine learning.
Altri strumenti e librerie di data science comuni includono SAS (per la modellazione statistica), Apache Spark (per l’analisi dei dati di streaming), D3.js (per visualizzazioni interattive nel browser) e Jupyter (per blocchi di codice interattivi e condivisibili e visualizzazioni) .
Foto: Seonjae Jo via Flickr, CC BY SA 2.0 (https://www.flickr.com/photos/130860834@N02/19786840570)
Esempi di scienza dei dati
Esempi di data science e sue applicazioni sono ovunque. La scienza dei dati ha applicazioni in tutto, dalla consegna degli alimenti, allo sport, al traffico e alla salute. I dati sono ovunque e quindi la scienza dei dati può essere applicata a tutto.
In termini di cibo, Uber sta investendo in un’espansione del suo sistema di condivisione delle corse incentrato sulla consegna di cibo, Uber Eats . Uber Eats deve offrire alle persone il loro cibo in modo tempestivo, mentre è ancora caldo e fresco. Affinché ciò avvenga, i data scientist dell’azienda devono utilizzare la modellazione statistica che tenga conto di aspetti quali la distanza dai ristoranti ai punti di consegna, i periodi di vacanza, i tempi di cottura e persino le condizioni meteorologiche, tutti considerati con l’obiettivo di ottimizzare i tempi di consegna .
Le statistiche sportive vengono utilizzate dai team manager per determinare chi sono i migliori giocatori e formare squadre forti e affidabili che vinceranno le partite. Un esempio notevole è la scienza dei dati documentata da Michael Lewis nel libro Moneyball , in cui il direttore generale del team di Oakland Athletics ha analizzato una varietà di statistiche per identificare giocatori di qualità che potrebbero essere firmati per il team a costi relativamente bassi.
L’analisi dei modelli di traffico è fondamentale per la creazione di veicoli a guida autonoma. I veicoli a guida autonoma devono essere in grado di prevedere l’attività intorno a loro e rispondere ai cambiamenti delle condizioni stradali, come la maggiore distanza di arresto richiesta quando piove, nonché la presenza di più auto sulla strada nelle ore di punta. Oltre ai veicoli a guida autonoma, app come Google Maps analizzano i modelli di traffico per dire ai pendolari quanto tempo impiegheranno per arrivare a destinazione utilizzando vari percorsi e forme di trasporto.
In termini di scienza dei dati sanitari , la visione artificiale è spesso combinata con l’apprendimento automatico e altre tecniche di intelligenza artificiale per creare classificatori di immagini in grado di esaminare cose come i raggi X, gli FMRI e gli ultrasuoni per vedere se ci sono potenziali problemi medici che potrebbero comparire in la scansione. Questi algoritmi possono essere utilizzati per aiutare i medici a diagnosticare la malattia.
In definitiva, la scienza dei dati copre numerose attività e riunisce aspetti di diverse discipline. Tuttavia, la scienza dei dati si preoccupa sempre di raccontare storie interessanti e interessanti dai dati e di utilizzare i dati per comprendere meglio il mondo.