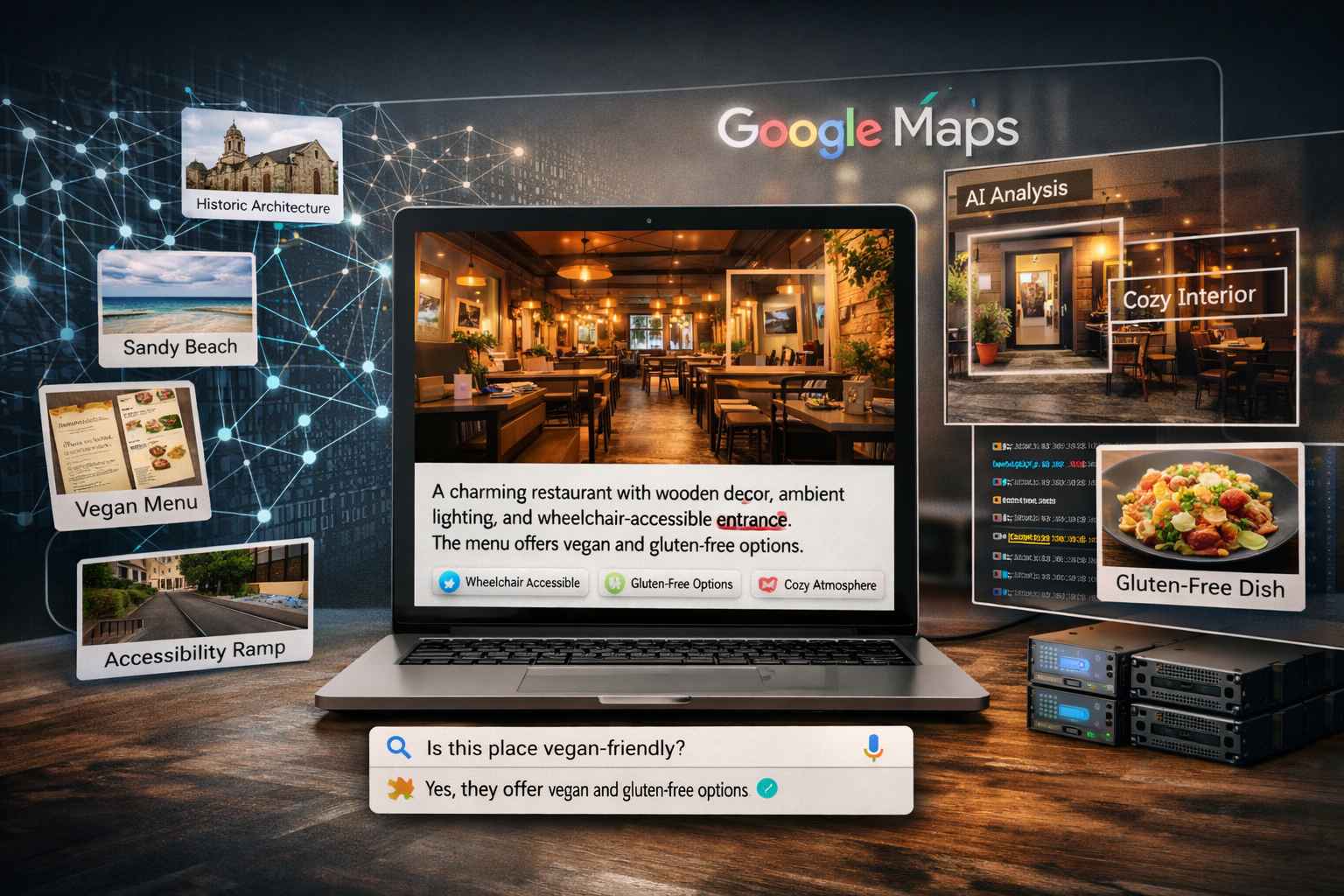
Il recente potenziamento di Google Maps dimostra come l’unione tra enormi database geografici e modelli linguistici di grandi dimensioni possa trasformare una semplice galleria fotografica in una risorsa informativa dinamica e accessibile. La capacità del sistema di descrivere dettagliatamente il contenuto delle immagini caricate dagli utenti non rappresenta solo un miglioramento estetico, ma risponde a una necessità tecnica di indicizzazione semantica profonda, permettendo al motore di ricerca di comprendere non solo dove si trovi un luogo, ma quali siano le sue caratteristiche intrinseche visibili solo attraverso l’obiettivo di una fotocamera.
Sotto il profilo strettamente tecnico, il processo di descrizione automatizzata si basa sull’impiego di reti neurali multimodali in grado di eseguire simultaneamente compiti di riconoscimento oggettuale, segmentazione della scena e generazione del linguaggio naturale. Quando un utente interagisce con una fotografia su Maps, il sistema analizza i pixel per identificare elementi specifici come la tipologia di architettura, la presenza di rampe per l’accessibilità, il tipo di illuminazione o persino l’atmosfera di un locale basandosi sulla disposizione degli arredi. Questa analisi non è una semplice etichettatura statica, poiché l’intelligenza artificiale è in grado di correlare i dati visivi con il contesto della ricerca dell’utente, fornendo risposte pertinenti che spiegano, ad esempio, se un ingresso è privo di gradini o se un menu fotografato contiene piatti adatti a specifiche esigenze alimentari.
L’infrastruttura che abilita queste funzioni sfrutta la potenza del calcolo distribuito per elaborare miliardi di immagini, estraendo metadati che alimentano la funzione di ricerca conversazionale. Questo significa che la tecnologia trasforma il contenuto visuale in testo ricercabile, permettendo agli utenti di porre domande dirette e ricevere risposte basate sull’evidenza fotografica più recente. Il sistema è programmato per filtrare le informazioni ridondanti e concentrarsi sui dettagli che aggiungono valore alla comprensione del luogo, utilizzando algoritmi di elaborazione del linguaggio naturale per garantire che la descrizione risultante sia fluida, accurata e priva di allucinazioni algoritmiche. Tale precisione è garantita da un continuo raffinamento dei modelli attraverso tecniche di apprendimento per rinforzo basate sul feedback umano, che aiutano l’IA a distinguere tra elementi essenziali e dettagli irrilevanti.
Oltre a facilitare la scoperta di nuovi luoghi, questa tecnologia ricopre un ruolo cruciale nell’abbattimento delle barriere digitali per gli utenti con disabilità visive. L’integrazione con i sistemi di lettura dello schermo permette di restituire una narrazione dettagliata dell’ambiente circostante, offrendo un’autonomia di navigazione senza precedenti. La capacità dell’intelligenza artificiale di generare descrizioni alt-text sofisticate in tempo reale trasforma l’esperienza cartografica da un esercizio prettamente visuale a un servizio inclusivo e multisensoriale. In ultima analisi, la trasformazione di Google Maps tramite l’IA generativa segna il passaggio definitivo verso una cartografia intelligente, dove l’immagine non è più un dato passivo ma una fonte attiva di conoscenza strutturata, capace di rispondere alle sfide della mobilità urbana contemporanea con una precisione e una profondità informativa senza precedenti.