Il settore dell’intelligenza artificiale sta assistendo alla diffusione di un nuovo sistema di valutazione dei modelli frontier basato sulla conversione delle performance AI in equivalenti di quoziente intellettivo umano. La piattaforma AI IQ, lanciata nelle ultime ore dallo sviluppatore Ryan Shea, aggrega benchmark pubblici di diversi modelli linguistici avanzati e li converte in punteggi distribuiti su una classica curva IQ umana, creando una classifica comparativa che sta già dividendo ricercatori, sviluppatori e community AI.
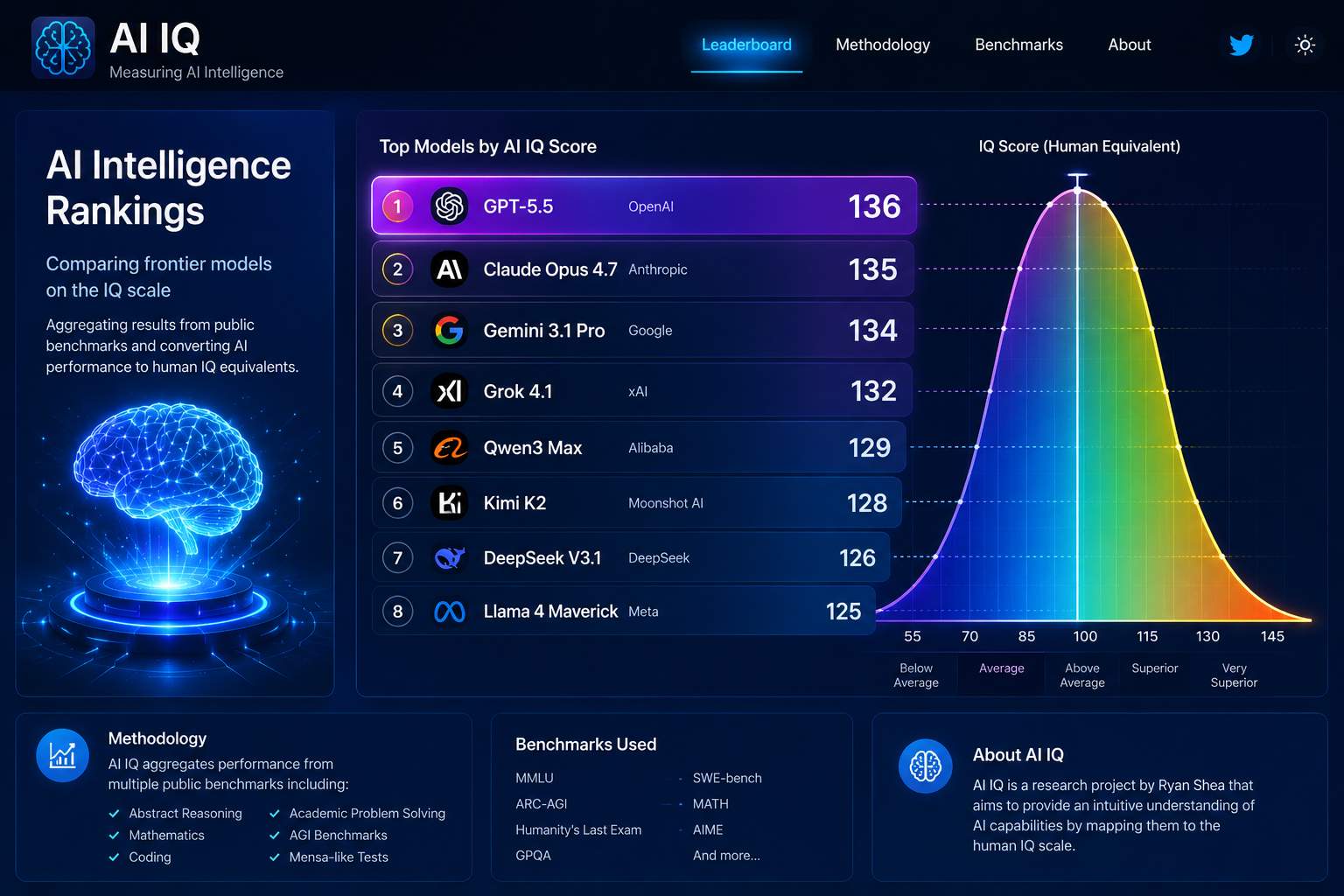
Il sistema utilizza benchmark pubblici relativi a ragionamento astratto, capacità matematiche, coding, problem solving accademico e altri indicatori cognitivi per produrre un punteggio sintetico espresso nella tradizionale scala IQ. Secondo i dati pubblicati nella piattaforma, i modelli frontier più avanzati risultano ormai collocati nella fascia tipicamente associata all’intelligenza superiore umana. GPT-5.5 viene indicato vicino a un IQ stimato di 136, seguito molto da vicino da Claude Opus 4.7 e Gemini 3.1 Pro, evidenziando una convergenza estremamente serrata tra i principali modelli occidentali.
Uno degli aspetti tecnici più discussi riguarda il metodo di normalizzazione dei benchmark. AI IQ non esegue test proprietari diretti, ma costruisce una metrica derivata aggregando risultati provenienti da leaderboard pubbliche, test Mensa-like, ARC-AGI, benchmark accademici e suite di reasoning. La piattaforma applica poi una trasformazione statistica per riportare le performance AI all’interno della distribuzione tipica del quoziente intellettivo umano. Secondo i creatori del sistema, l’obiettivo non è sostenere che i modelli “pensino come esseri umani”, ma offrire una rappresentazione intuitiva della velocità di crescita delle capacità cognitive artificiali.
La questione sta però generando forti critiche nella comunità scientifica e tecnica. Diversi ricercatori contestano infatti la validità concettuale del confronto diretto tra IQ umano e performance AI specializzate. Il problema principale è che molti benchmark utilizzati misurano abilità molto specifiche, spesso limitate a pattern recognition, reasoning simbolico o problem solving altamente strutturato, mentre il quoziente intellettivo umano nasce storicamente come indicatore multidimensionale legato al funzionamento cognitivo generale della persona.
Un altro punto critico riguarda il cosiddetto “AI effect”, cioè il fenomeno per cui attività inizialmente considerate manifestazioni di intelligenza vengono riclassificate come semplice automazione una volta che l’AI riesce a eseguirle efficacemente. Questo rende estremamente instabile qualsiasi definizione di “intelligenza artificiale comparabile all’uomo”, soprattutto in un contesto nel quale le capacità dei modelli crescono con estrema rapidità.
La piattaforma evidenzia anche un cambiamento significativo del mercato frontier AI. Le differenze prestazionali tra i modelli top-tier stanno diventando sempre più ridotte, mentre cresce rapidamente la competitività dei modelli cinesi e open-weight nella fascia immediatamente inferiore. Le classifiche pubblicate mostrano infatti cluster molto compressi tra i sistemi più avanzati, segnale di una corsa tecnologica ormai estremamente serrata tra OpenAI, Anthropic, Google, xAI, Moonshot e i principali laboratori asiatici.
La diffusione di metriche come AI IQ riflette inoltre una tendenza più ampia: il tentativo del settore AI di trovare indicatori sintetici facilmente comprensibili anche al di fuori della comunità tecnica. Benchmark tradizionali come MMLU, ARC, Humanity’s Last Exam o SWE-bench risultano infatti molto difficili da interpretare per aziende, investitori e pubblico generalista. Convertire le performance in una scala familiare come l’IQ umano semplifica enormemente la comunicazione commerciale e mediatica delle capacità dei modelli.
Resta però aperto il problema scientifico fondamentale: nessun benchmark attuale è universalmente accettato come misura affidabile dell’intelligenza generale artificiale. I modelli linguistici contemporanei mostrano prestazioni eccezionali in molti domini cognitivi, ma continuano a presentare limiti significativi in robustezza, pianificazione autonoma, affidabilità contestuale e comprensione causale profonda. Per questo motivo, molti esperti considerano queste classifiche utili soprattutto come strumenti comparativi di mercato e monitoraggio evolutivo, più che come reali equivalenti del quoziente intellettivo umano.