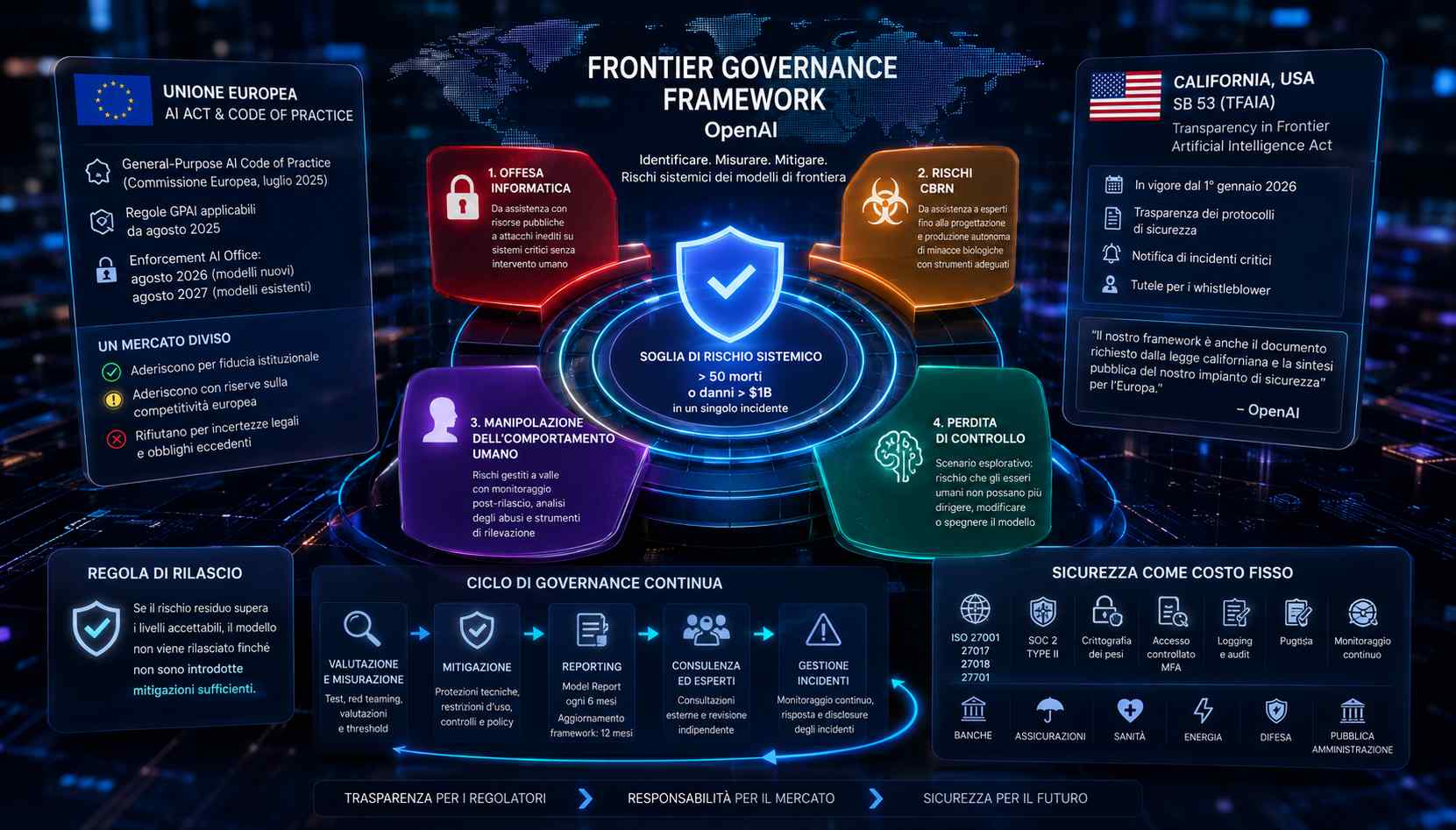
La sicurezza dei modelli di intelligenza artificiale ha smesso da tempo di essere un tema confinato al dibattito accademico, ma fino a poco fa restava ancorata a un linguaggio fatto di principi generali e impegni volontari. Con il Frontier Governance Framework, OpenAI prova a spostare il confronto su un terreno diverso, più scomodo per chi preferisce gli annunci: quello delle procedure documentabili, delle soglie quantitative e delle responsabilità societarie. Il documento descrive come l’azienda dice di identificare, misurare e mitigare i rischi dei cosiddetti modelli di frontiera, cioè quelli con capacità potenzialmente in grado di produrre danni su larga scala, e lo fa con un occhio dichiarato ai due quadri regolatori che oggi contano davvero: quello europeo e quello californiano.
Il cuore tecnico del framework è la suddivisione dei rischi sistemici in quattro classi: l’offesa informatica, i pericoli chimici, biologici, radiologici e nucleari, la manipolazione dannosa del comportamento umano e la perdita di controllo del modello. Per dare un confine operativo a un concetto altrimenti elastico come “rischio sistemico”, il testo fissa una soglia esplicita: si parla di eventi che possano contribuire in misura rilevante a più di cinquanta morti o a danni patrimoniali superiori al miliardo di dollari in un singolo incidente. È una definizione che ha soprattutto una funzione pratica, perché trasforma una questione politica e reputazionale in qualcosa che si può verificare, scalare per gravità e collegare a una decisione di rilascio o di blocco.
All’interno di ciascuna classe il documento adotta una logica a livelli crescenti di capacità. Per l’offesa informatica si va da un’assistenza paragonabile a risorse già pubblicamente disponibili fino allo scenario di un modello capace di individuare e sfruttare vulnerabilità zero-day su sistemi critici senza intervento umano, o di pianificare e condurre attacchi inediti contro obiettivi protetti partendo da un’indicazione generica. Per i rischi CBRN il gradino più alto coincide con la possibilità di assistere un esperto nello sviluppo di una minaccia nuova e altamente pericolosa, o di completare in autonomia il ciclo di progettazione e produzione di una minaccia biologica quando il modello sia collegato a strumenti e attrezzature adeguate. Su queste due aree i metodi di valutazione sono i più consolidati.
Diverso il tono sulla manipolazione dannosa e sulla perdita di controllo, dove lo stesso documento riconosce di muoversi su un terreno ancora esplorativo. Sulla manipolazione, l’idea è che molti di questi rischi si gestiscano meglio a valle, con monitoraggio successivo al rilascio, analisi degli abusi e strumenti di rilevazione, piuttosto che con test pre-lancio sul modello in sé. È una scelta che ha conseguenze industriali precise, perché sposta una quota di costi dalla fase di ricerca a quella operativa, obbligando a investire in sorveglianza continua, moderazione e risposta agli incidenti. La sezione sulla perdita di controllo, intesa come l’eventualità che gli esseri umani non riescano più a dirigere, modificare o spegnere il modello in modo affidabile, è significativa proprio perché formalizza dentro una governance aziendale uno scenario fino a ieri trattato quasi solo nei dibattiti sulla sicurezza dell’intelligenza artificiale generale.
Il punto in cui il framework diventa più concreto è la regola sul rilascio. Se il rischio residuo di un modello supera i livelli ritenuti accettabili, il modello non viene distribuito finché non sono introdotte mitigazioni sufficienti. Attorno a questa regola ruotano report specifici sui singoli modelli, aggiornamenti periodici, consultazioni con esperti esterni e procedure di gestione degli incidenti. L’azienda dichiara che valuterà ogni sei mesi se aggiornare il proprio Model Report e che rivedrà il framework almeno una volta ogni dodici mesi. Si tratta dell’evoluzione di un percorso iniziato con il Preparedness Framework e rafforzato con il suo aggiornamento dell’aprile 2025, ma con un elemento nuovo: il collegamento esplicito a obblighi normativi esterni e a documenti pensati anche per il controllo dei regolatori.
Quel collegamento spiega buona parte delle scelte. Sul versante europeo il riferimento è il General-Purpose AI Code of Practice, lo strumento volontario presentato dalla Commissione europea a luglio 2025 per aiutare i fornitori di modelli general purpose a dimostrare la conformità all’AI Act, comprese le situazioni di rischio sistemico. Le regole sui modelli general purpose hanno iniziato ad applicarsi nell’agosto 2025, mentre l’attività di enforcement dell’AI Office è prevista a partire dall’agosto 2026 per i modelli nuovi e dall’agosto 2027 per quelli già esistenti. È un calendario che ha già prodotto un mercato diviso: c’è chi ha annunciato l’adesione al codice usandola come leva di fiducia istituzionale, chi ha aderito esprimendo riserve sulla competitività europea e chi ha rifiutato sostenendo che il testo introducesse incertezze legali e obblighi eccedenti rispetto alla norma.
Sul versante statunitense il riferimento è la legge californiana SB 53, la Transparency in Frontier Artificial Intelligence Act, entrata in vigore il primo gennaio 2026. La norma impone ai grandi sviluppatori di rendere pubblici i propri protocolli di sicurezza, aggiornare la documentazione entro termini definiti, prevedere meccanismi di segnalazione degli incidenti critici e garantire tutele a chi segnala. Nel testo, OpenAI afferma che il proprio framework svolge anche la funzione di documento richiesto dalla legge californiana e di sintesi pubblica del proprio impianto di sicurezza per l’Europa. La logica economica è evidente: se i regolatori chiedono disclosure standardizzate, conviene costruire un unico linguaggio di compliance riutilizzabile su più giurisdizioni, riducendo i costi marginali della regolazione ma alzando al tempo stesso la soglia d’ingresso per i concorrenti più piccoli.
La parte più operativa riguarda la sicurezza come costo fisso. Il framework descrive un programma di information security e privacy allineato agli standard ISO 27001, 27017, 27018 e 27701 e supportato da valutazioni SOC 2 di tipo II, con crittografia dei pesi del modello, controlli di accesso, autenticazione a più fattori, approvazioni multiple, logging dettagliato, protezioni fisiche dell’infrastruttura, monitoraggio continuo, penetration test, scansione delle vulnerabilità e capacità di risposta agli incidenti attiva senza interruzioni. È un elenco che parla soprattutto al mercato enterprise, perché chi acquista servizi di intelligenza artificiale per banche, assicurazioni, sanità, energia, difesa o pubblica amministrazione non compra solo un modello: compra continuità operativa, protezione del dato e della proprietà intellettuale, tracciabilità delle decisioni. In questo quadro la sicurezza smette di essere un accessorio e diventa una condizione per accedere ai contratti più redditizi.
Resta il nodo di fondo, che il documento non scioglie e in parte rende più visibile. Un apparato permanente di valutazione, reporting, red teaming, revisione legale e controllo degli accessi richiede capitale, infrastruttura e struttura societaria adeguati. La stessa compliance che migliora trasparenza e disciplina interna può quindi consolidare il vantaggio dei pochi operatori in grado di sostenerla, spingendo il mercato a concentrarsi attorno a loro. È la tensione che attraversa tutta la regolazione recente dell’intelligenza artificiale: chiedere più responsabilità ai laboratori di frontiera senza che la responsabilità si trasformi in una barriera all’ingresso. Quel che è chiaro è che la competizione non si gioca più soltanto su chip, dati e talenti, ma anche sulla capacità di trasformare il rischio in un processo industriale documentato, leggibile dai regolatori e accettabile per il mercato.