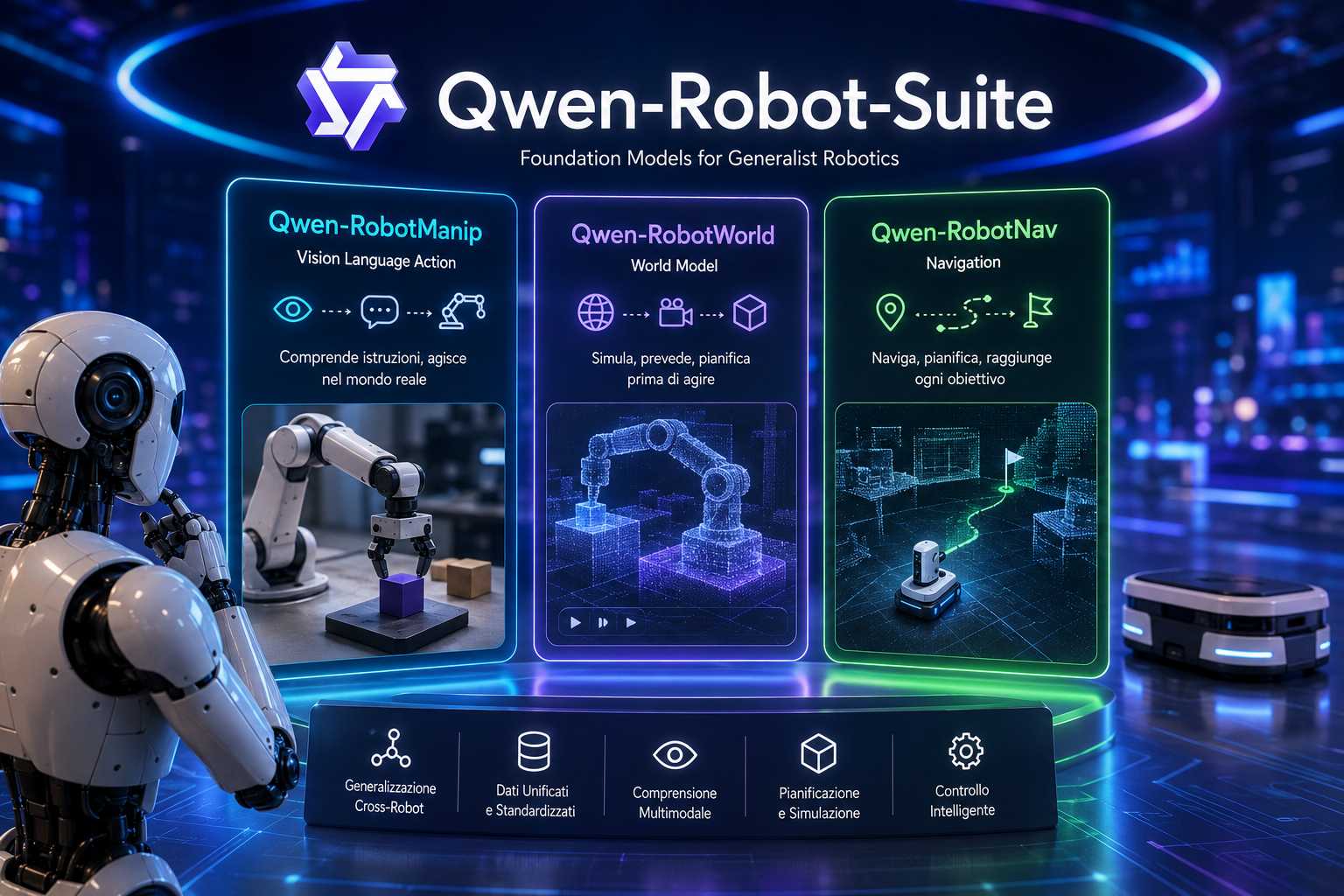
Alibaba ha annunciato Qwen-Robot-Suite, una nuova famiglia di modelli fondamentali per la robotica progettata per affrontare uno dei principali ostacoli che limita oggi lo sviluppo di sistemi robotici intelligenti: la frammentazione dei dati tra piattaforme hardware differenti. La suite introduce tre modelli specializzati che coprono le principali capacità necessarie a un robot autonomo moderno, dalla manipolazione degli oggetti alla comprensione dell’ambiente fisico, fino alla navigazione e al movimento nello spazio.
Uno dei problemi più complessi della robotica contemporanea riguarda infatti l’eterogeneità delle piattaforme. Robot diversi utilizzano configurazioni meccaniche differenti, sensori differenti, sistemi di controllo differenti e formati di registrazione dei dati incompatibili tra loro. Questo rende difficile trasferire l’esperienza acquisita da un robot a un altro e costringe spesso a ripetere lunghi processi di addestramento per ogni nuova piattaforma. Qwen-Robot-Suite è stata progettata proprio per ridurre questa dipendenza dall’hardware specifico, introducendo rappresentazioni comuni che consentano ai modelli di generalizzare tra robot diversi.
Il primo componente della suite è Qwen-RobotManip, un modello Vision Language Action sviluppato sulla base di Qwen 3.5-4B. Il sistema riceve come input immagini provenienti dalle telecamere del robot e istruzioni formulate in linguaggio naturale, trasformandole direttamente in comandi di controllo a basso livello per la manipolazione degli oggetti. L’obiettivo è consentire al robot di comprendere cosa fare osservando l’ambiente e interpretando istruzioni umane senza richiedere programmazione esplicita per ogni singolo scenario operativo.
Per ottenere questo risultato, Alibaba ha introdotto un Unified Alignment Framework che standardizza il modo in cui vengono rappresentati stato e azioni del robot. La piattaforma utilizza una rappresentazione canonica a 80 dimensioni che descrive in modo uniforme informazioni provenienti da robot differenti. I movimenti vengono inoltre espressi rispetto al sistema di riferimento della telecamera, consentendo al modello di apprendere comportamenti visivamente equivalenti anche quando eseguiti da macchine con configurazioni meccaniche diverse. Un ulteriore meccanismo di adattamento contestuale permette di adattare le azioni alle caratteristiche specifiche del robot utilizzando la cronologia recente dei movimenti, evitando la necessità di un nuovo addestramento dedicato.
L’addestramento di RobotManip è stato effettuato utilizzando oltre 38.000 ore di dati di manipolazione. Una parte significativa del dataset è stata generata convertendo video di movimenti umani in dimostrazioni robotiche, creando circa 24.800 ore di dati operativi aggiuntivi. Nei test di trasferimento tra piattaforme differenti il modello ha raggiunto un tasso di successo del 23,9%, superando di oltre tre volte i risultati ottenuti da precedenti sistemi di riferimento. Le prestazioni sono state validate su diverse piattaforme robotiche reali, tra cui AgileX ALOHA, Franka, UR e ARX.
Il secondo elemento della suite è Qwen-RobotWorld, un modello del mondo progettato per prevedere l’evoluzione futura dell’ambiente fisico. Questo sistema rappresenta una delle componenti più avanzate dell’intera architettura, poiché consente al robot di simulare mentalmente le conseguenze delle proprie azioni prima di eseguirle realmente. Dopo aver ricevuto una descrizione linguistica dell’obiettivo e una rappresentazione della scena corrente, il modello genera una sequenza video che rappresenta ciò che dovrebbe accadere nell’ambiente.
La caratteristica distintiva di RobotWorld è l’utilizzo del linguaggio naturale come interfaccia universale per la descrizione delle azioni. Mentre molti modelli del mondo tradizionali utilizzano vettori numerici specifici per ogni piattaforma robotica, RobotWorld descrive comportamenti, obiettivi e vincoli direttamente attraverso istruzioni linguistiche. Questo approccio consente di separare la pianificazione dall’hardware, facilitando il trasferimento delle conoscenze tra sistemi differenti.
Il modello utilizza un Multimodal Diffusion Transformer a 60 livelli con 20 miliardi di parametri. La componente di comprensione sfrutta Qwen2.5-VL, mentre la generazione delle simulazioni avviene nello spazio latente di un sistema VAE dedicato ai video. L’addestramento è stato effettuato utilizzando il dataset Embodied World Knowledge, composto da 8,6 milioni di coppie immagine-testo e oltre 200 milioni di fotogrammi provenienti da scenari di manipolazione, navigazione, guida autonoma e trasferimento uomo-robot.
I risultati ottenuti mostrano miglioramenti significativi nella simulazione dei comportamenti fisici. Nei benchmark dedicati alla modellazione del mondo fisico, RobotWorld ha raggiunto i migliori risultati nelle categorie relative a meccanica newtoniana, conservazione della massa, gravità e dinamica dei fluidi, dimostrando una capacità avanzata di rappresentare le leggi fisiche che governano l’ambiente reale.
Il terzo componente della suite è Qwen-RobotNav, dedicato alla navigazione autonoma. Basato su Qwen3-VL e disponibile nelle varianti da 2, 4 e 8 miliardi di parametri, il modello affronta il problema della navigazione da una prospettiva differente rispetto agli approcci tradizionali. Invece di separare attività come pianificazione del percorso, rilevamento degli oggetti e inseguimento degli obiettivi, RobotNav trasforma l’intero processo in un problema unificato di previsione dei waypoint.
Il sistema genera sequenze di punti di movimento che includono informazioni sia sulla posizione sia sull’orientamento futuro del robot. Questa rappresentazione permette di semplificare notevolmente il controllo e di adattarsi a diversi scenari operativi. Un’altra caratteristica distintiva è la possibilità di modificare dinamicamente il modo in cui vengono elaborate le informazioni sensoriali. Parametri come il budget dei token visivi, il peso temporale delle osservazioni e l’importanza delle diverse telecamere possono essere regolati in funzione della missione e dell’ambiente operativo.
RobotNav introduce inoltre una struttura agentica a due livelli. Un pianificatore di alto livello scompone gli obiettivi complessi in sotto-obiettivi intermedi, mentre il modulo esecutivo si occupa dell’esecuzione in tempo reale. La comunicazione tra i due livelli avviene esclusivamente attraverso il linguaggio naturale, creando un’architettura più flessibile e facilmente estendibile.
L’addestramento del modello ha utilizzato 15,6 milioni di esempi, in gran parte dedicati alla navigazione e in parte al ragionamento visivo e linguistico. I risultati mostrano miglioramenti significativi nei benchmark di navigazione embodied e una riduzione del 77% nel numero di passi necessari per completare determinate attività, a dimostrazione di una maggiore efficienza operativa.
Con Qwen-Robot-Suite, Alibaba compie uno dei passi più significativi della propria strategia nel settore della robotica intelligente. Dopo aver sviluppato modelli linguistici e multimodali open source di ampia diffusione, l’azienda estende ora l’ecosistema Qwen al mondo fisico, costruendo una piattaforma che copre simultaneamente percezione, ragionamento, pianificazione, simulazione e controllo. L’obiettivo è creare fondamenta comuni per una nuova generazione di robot capaci di apprendere, comprendere e operare in ambienti reali con un livello di generalizzazione significativamente superiore rispetto alle soluzioni attuali.