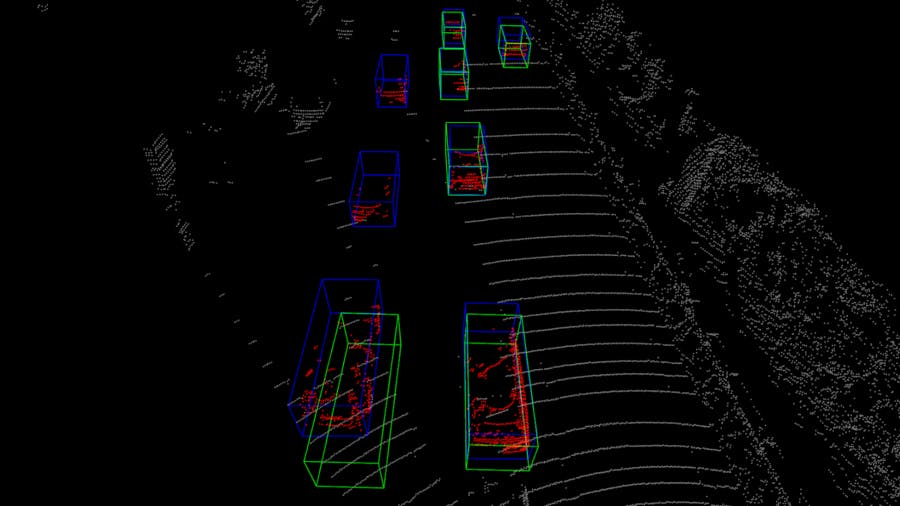
La nuova tecnica aiuta l’IA a identificare oggetti 3D
Una nuova tecnica sviluppata dai ricercatori della North Carolina State University migliora la capacità dei programmi di intelligenza artificiale (AI) di identificare oggetti 3D. Chiamata MonoCon, la tecnica aiuta anche l’IA ad apprendere come gli oggetti 3D si relazionano tra loro nello spazio utilizzando immagini 2D.
MonoCon potrebbe potenzialmente avere un’ampia gamma di applicazioni, incluso aiutare i veicoli autonomi a navigare intorno ad altri veicoli utilizzando immagini 2D ricevute da una telecamera di bordo. Potrebbe anche svolgere un ruolo nella produzione e nella robotica.
Tianfu Wu è autore corrispondente del documento di ricerca e assistente professore di ingegneria elettrica e informatica presso la North Carolina State University.
“Viviamo in un mondo 3D, ma quando scatti una foto, registra quel mondo in un’immagine 2D”, afferma Wu.
“I programmi di intelligenza artificiale ricevono input visivi dalle telecamere. Quindi, se vogliamo che l’IA interagisca con il mondo, dobbiamo assicurarci che sia in grado di interpretare ciò che le immagini 2D possono dirgli dello spazio 3D. In questa ricerca, ci concentriamo su una parte di questa sfida: come possiamo fare in modo che l’IA riconosca accuratamente oggetti 3D, come persone o automobili, in immagini 2D e collochi quegli oggetti nello spazio”, continua Wu.
Veicoli autonomi
I veicoli autonomi spesso si affidano a lidar per navigare nello spazio 3D. Lidar, che utilizza i laser per misurare la distanza, è costoso, il che significa che i sistemi autonomi non includono molta ridondanza. Mettere dozzine di sensori lidar su un’auto senza conducente prodotta in serie sarebbe incredibilmente costoso.
“Ma se un veicolo autonomo potesse utilizzare input visivi per navigare nello spazio, potresti creare ridondanza”, afferma Wu. “Poiché le telecamere sono significativamente meno costose di Lidar, sarebbe economicamente fattibile includere telecamere aggiuntive, creando ridondanza nel sistema e rendendolo sia più sicuro che più robusto.
“Questa è un’applicazione pratica. Tuttavia, siamo anche entusiasti del progresso fondamentale di questo lavoro: che è possibile ottenere dati 3D da oggetti 2D”.
Allenare l’IA
MonoCon può identificare oggetti 3D nelle immagini 2D prima di inserirli in un “riquadro di delimitazione”, che indica all’IA i bordi esterni dell’oggetto.
“Ciò che distingue il nostro lavoro è il modo in cui alleniamo l’IA, che si basa su tecniche di formazione precedenti”, afferma Wu. “Come gli sforzi precedenti, posizioniamo oggetti in scatole di delimitazione 3D mentre alleniamo l’IA. Tuttavia, oltre a chiedere all’IA di prevedere la distanza telecamera-oggetto e le dimensioni dei riquadri di delimitazione, chiediamo anche all’IA di prevedere le posizioni di ciascuno degli otto punti del riquadro e la sua distanza dal centro del riquadro. scatola in due dimensioni. Chiamiamo questo “contesto ausiliario” e abbiamo scoperto che aiuta l’IA a identificare e prevedere con maggiore precisione gli oggetti 3D sulla base di immagini 2D.
“Il metodo proposto è motivato da un noto teorema nella teoria della misura, il teorema di Cramér-Wold. È anche potenzialmente applicabile ad altre attività di previsione dell’output strutturato nella visione artificiale .
MonoCon è stato testato con un set di dati benchmark ampiamente utilizzato chiamato KITTI.
“Al momento in cui abbiamo presentato questo documento, MonoCon ha funzionato meglio di qualsiasi delle dozzine di altri programmi di intelligenza artificiale volti a estrarre dati 3D sulle automobili da immagini 2D”, afferma Wu.
Il team ora cercherà di aumentare il processo con set di dati più grandi.
“Andando avanti, lo stiamo ampliando e stiamo lavorando con set di dati più ampi per valutare e mettere a punto MonoCon per l’uso nella guida autonoma”, afferma Wu. “Vogliamo anche esplorare le applicazioni nella produzione, per vedere se possiamo migliorare le prestazioni di attività come l’uso di bracci robotici”.