Un nuovo strumento di Google e OpenAI ci consente di vedere meglio attraverso gli occhi dell’intelligenza artificiale
Che aspetto ha il mondo per l’intelligenza artificiale?
I ricercatori si sono interrogati su questo per decenni, ma negli ultimi anni la domanda è diventata più pressante. I sistemi di visione artificiale vengono implementati in sempre più aree della vita, dall’assistenza sanitaria alle auto che si guidano da soli, ma “vedono” attraverso gli occhi di una macchina – capendo perché ha classificato quella persona come pedone ma quella come un cartello – è ancora una sfida. La nostra incapacità di farlo potrebbe avere conseguenze gravi, persino fatali. Alcuni direbbero che ciò è già avvenuto a causa della morte di auto a guida autonoma.
Nuove ricerche di Google e del laboratorio non profit OpenAI spera di aprire ulteriormente la scatola nera della visione AI mappando i dati visivi che questi sistemi usano per capire il mondo. Il metodo, denominato ” Activation Atlases “, consente ai ricercatori di analizzare il funzionamento dei singoli algoritmi, rivelando non solo le forme astratte, i colori e i pattern che riconoscono, ma anche il modo in cui combinano questi elementi per identificare oggetti, animali e scene specifici.
“SEMBRA UN PO ‘COME CREARE UN MICROSCOPIO.”
Shan Carter di Google, un ricercatore capo del lavoro, ha detto a The Verge che se le ricerche precedenti fossero state come rivelare lettere individuali nell’alfabeto visivo degli algoritmi, Activation Atlases offre qualcosa di più vicino a un intero dizionario, mostrando come le lettere sono messe insieme per fare parole reali . “Quindi, all’interno di una categoria di immagini come” squalo “, ad esempio, ci saranno molte attivazioni che vi contribuiranno, come” denti “e” acqua “, dice Carter.
Il lavoro non è necessariamente un grande passo avanti, ma è un passo avanti in un campo di ricerca più ampio conosciuto come “visualizzazione delle caratteristiche”. Ramprasaath Selvaraju, uno studente di dottorato in Georgia Tech che non è stato coinvolto nel lavoro, ha detto che la ricerca era “estremamente affascinante “e aveva combinato un numero di idee esistenti per creare un nuovo strumento” incredibilmente utile “.

Selvaraju ha detto a The Verge che, in futuro, un lavoro come questo avrà molti usi, aiutandoci a costruire algoritmi più efficienti e avanzati, nonché a migliorare la loro sicurezza e rimuovere i pregiudizi lasciando che i ricercatori scrutino all’interno. “A causa della natura complessa intrinseca [delle reti neurali], mancano di interpretabilità”, afferma Selvaraju. Ma in futuro, dice, quando tali reti sono abitualmente utilizzate per guidare le auto e guidare i robot, questa sarà una necessità.
Chris Olah di OpenAI, che ha anche lavorato al progetto, ha dichiarato: “Sembra un po ‘come creare un microscopio. Almeno, questo è ciò a cui aspiriamo “.
Puoi esplorare una versione interattiva dell’Attivazione Atlante nella foto qui sotto .
Per capire come funzionano Activation Atlases e altri strumenti di visualizzazione delle funzioni, è necessario prima conoscere un po ‘come i sistemi AI riconoscono gli oggetti in primo luogo.
Il modo basilare per farlo è usare una rete neurale: una struttura computazionale che è in linea di massima simile al cervello umano (sebbene sia indietro di anni luce nella sofisticazione). All’interno di ciascuna rete neurale vi sono strati di neuroni artificiali collegati come ragnatele. Come le cellule del cervello, questi fuoco in risposta agli stimoli, un processo noto come attivazione. È importante sottolineare che non si accendono o spengono; si registrano su uno spettro, dando ad ogni attivazione un valore specifico o “peso”.
Per trasformare una rete neurale in qualcosa di utile, devi nutrirla con molti dati di addestramento. Nel caso di un algoritmo di visione, ciò significa centinaia di migliaia, forse anche milioni di immagini, ciascuna etichettata con una categoria specifica. Nel caso della rete neurale testata da Google e dai ricercatori di OpenAI per questo lavoro, queste categorie erano di ampio respiro: tutto, dalla lana alle cravatte Windsor, dalle cinture di sicurezza agli aerotermi.
Le reti neurali utilizzano strati di neuroni artificiali collegati per elaborare i dati. Diversi neuroni reagiscono a diverse parti delle immagini. Immagine: OpenAI / Google
Man mano che vengono alimentati questi dati, diversi neuroni nella rete neurale si accendono in risposta a ciascuna immagine. Questo modello è collegato all’etichetta dell’immagine ed è questa associazione che consente alla rete di “apprendere” come appaiono le cose. Una volta addestrato, è possibile mostrare alla rete un’immagine mai vista prima e i neuroni si attiveranno, facendo corrispondere l’input a una categoria specifica. Congratulazioni! Hai appena addestrato un algoritmo di visione di apprendimento automatico.
Se tutto ciò suona fastidiosamente semplice, è perché, in molti modi, lo è. Come molti programmi di apprendimento automatico, gli algoritmi di visione sono, in fondo, semplicemente macchine di abbinamento di modelli. Ciò conferisce loro alcuni punti di forza (come il fatto che sono semplici da addestrare finché si hanno i dati e la potenza di calcolo necessari). Ma dà loro anche alcuni punti deboli (come il fatto che siano facilmente confusi da input che non hanno mai visto prima).
Dal momento che i ricercatori hanno scoperto il potenziale delle reti neuronali per le attività di visione nei primi anni del 2010, hanno armeggiato con i loro meccanismi, cercando di capire esattamente come fanno ciò che fanno.
Un primo esperimento è stato DeepDream, un programma di visione artificiale pubblicato nel 2015 che ha trasformato qualsiasi immagine in una versione allucinogena di se stessa. Le immagini di DeepDream erano certamente divertenti (in un certo senso erano diventate l’estetica che definiva l’intelligenza artificiale), ma il programma era anche una prima incursione nel vedere come un algoritmo. “In un certo senso, tutto inizia con DeepDream”, dice Olah.
Le immagini DeepDream come questa sono progettate per essere il più interessante possibile per gli algoritmi di apprendimento automatico.
Che cosa fa DeepDream è sintonizzare le immagini per essere il più interessante possibile per gli algoritmi. Può sembrare che il software stia nascondendo i motivi “nascosti” in un’immagine, ma è più simile a qualcuno che scarabocchia su un libro da colorare: riempie ogni centimetro di occhi, steli, spirali e musi, il tutto per eccitare l’algoritmo il più possibile.
Le ricerche successive hanno preso questo stesso approccio di base e messo a punto: prima mirano i singoli neuroni all’interno della rete per vedere cosa li eccita , quindi gruppi di neuroni, quindi combinazioni di neuroni in diversi strati della rete. Se i primi esperimenti erano dedicati ma casuali, come Isaac Newton che si spuntava negli occhi con un ago smussato per comprendere la visione, il lavoro recente è come Newton che spacca un raggio di luce con un prisma. È molto più concentrato. Mappando quali elementi visivi sono attivati in ciascuna parte di una rete neurale, di volta in volta, alla fine, si ottiene l’atlante: un indice visivo al suo cervello.
Zoom avanti e indietro dell’Attivazione Atlante. Immagine: Google / OpenAI
UNA VISTA A MACCHINA
Ma cosa sono in realtà gli Atlanti di attivazione che ci mostrano il funzionamento interno degli algoritmi? Bene, puoi iniziare semplicemente navigando su Google e l’esempio di OpenAI qui , creato per eliminare l’interfaccia di una rete neurale nota chiamata GoogLeNet o InceptionV1.
Scorrendo, puoi vedere come diverse parti della rete rispondono a concetti diversi e come questi concetti sono raggruppati. (Quindi, per esempio, i cani sono tutti in un posto, e gli uccelli sono in un altro.) Puoi anche vedere come diversi strati della rete rappresentano diversi tipi di informazioni. I livelli inferiori sono più astratti, rispondono a forme geometriche di base, mentre livelli più alti li risolvono in concetti riconoscibili.
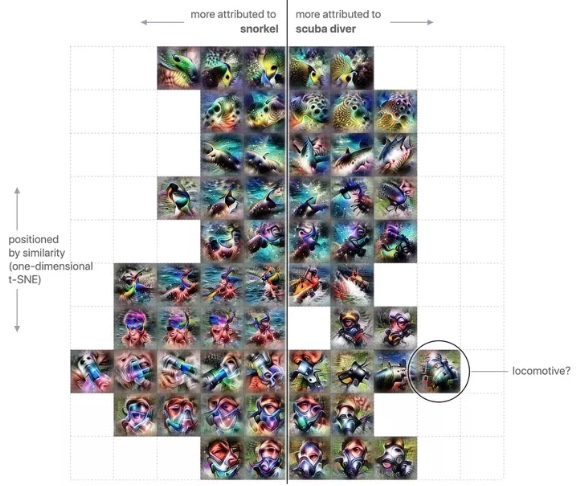
Dove questo diventa davvero interessante è quando si scavano nelle classificazioni individuali. Un esempio dato da Google e OpenAI è la differenza tra la categoria “snorkel” e “scuba diver”.
Nell’immagine sottostante, puoi vedere le varie attivazioni che sono utilizzate dalla rete neurale per identificare queste etichette. Sulla sinistra ci sono le attivazioni che sono fortemente associate con lo “snorkel” e sulla destra ci sono le attivazioni che sono fortemente associate al “subacqueo”. Quelle al centro sono condivise tra le due classi, mentre quelle ai margini sono più differenziata.
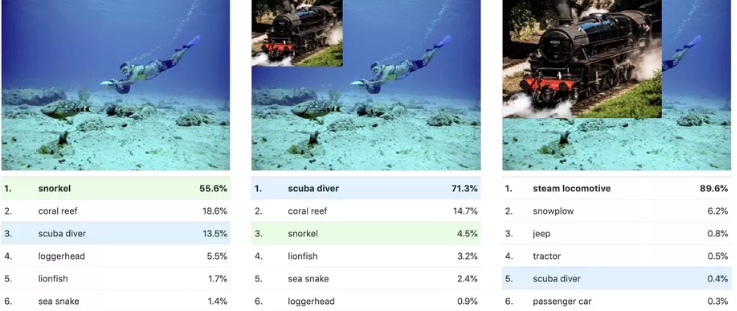
A colpo d’occhio, puoi distinguere alcuni colori e modelli ovvi. Nella parte superiore, hai ciò che sembra le macchie e le strisce di pesci dai colori vivaci, mentre nella parte inferiore, ci sono forme che sembrano maschere facciali. Ma evidenziato sul lato destro è un’attivazione insolita – una fortemente associata alle locomotive. Quando i ricercatori hanno trovato questo, erano perplessi. Perché questa informazione visiva sulle locomotive era importante per riconoscere i subacquei?
“Così l’abbiamo testato”, dice Carter. “Siamo tipo, ‘Okay, se mettiamo una foto di una locomotiva a vapore, invertirà la classificazione da uno snorkeler o da un subacqueo?’ Ed ecco, lo fa. “
Tre immagini mostrano come la stessa immagine può essere riclassificata. A sinistra, è identificato come uno snorkeler; nel mezzo, con la locomotiva aggiunta, diventa un subacqueo; e quando la locomotiva è abbastanza grande, prende il controllo dell’intera classifica. Immagine: OpenAI / Google
Alla fine il team ha capito il motivo: è perché le curve lisce di metallo di una locomotiva sono visivamente simili ai serbatoi d’aria di un sub. Quindi, per una rete neurale, questa è una differenza evidente tra sub e snorkelers. E per risparmiare tempo tra la distinzione delle due categorie, è stato semplicemente preso in prestito i dati visivi identificativi di cui aveva bisogno da altrove.
Questo tipo di esempio è incredibilmente rivelatore di come funzionano le reti neurali. Per gli scettici, mostra i limiti di questi sistemi. Gli algoritmi di visione possono essere efficaci, dicono, ma le informazioni che apprendono in realtà hanno poco a che fare con il modo in cui gli esseri umani comprendono il mondo. Questo li rende suscettibili a certi trucchi. Ad esempio, se si spruzzano solo pochi pixel scelti con cura in un’immagine , può essere sufficiente per classificare in modo errato un algoritmo.
Ma per Carter, Olah e altri come loro, le informazioni rivelate da Activation Atlases e strumenti simili mostrano la sorprendente profondità e flessibilità di questi algoritmi. Carter sottolinea, ad esempio, che affinché l’algoritmo possa distinguere tra subacquei e snorkelers, associa anche diversi tipi di animali a ciascuna categoria.
IL PEERING DEGLI ALGORITMI POTREBBE RENDERLI PIÙ SICURI ED EFFICIENTI
“[Gli animali] che si verificano in acque profonde, come le tartarughe, sono finiti dallo scuba e quelli che si verificano in superficie, come gli uccelli, sono finiti dallo snorkel”, dice. Sottolinea che si tratta di informazioni che il sistema non ha mai diretto per imparare. Invece, lo ha appena preso da solo. “E questo è un po ‘come una più profonda comprensione del mondo. È davvero eccitante per me. “
Olah è d’accordo. “Trovo quasi stupefacente indurre a guardare attraverso questi atlanti a risoluzioni più elevate e vedere semplicemente lo spazio gigante di cose che queste reti possono rappresentare”.
La coppia spera che sviluppando strumenti come questo, aiuteranno a far avanzare l’intero campo dell’intelligenza artificiale. Comprendendo come i sistemi di visione artificiale vedono il mondo, possiamo teoricamente costruirli in modo più efficiente e controllare la loro accuratezza in modo più approfondito.
“Abbiamo una cassetta degli attrezzi limitata per ora,” dice Olah. Dice che possiamo lanciare i dati dei test sui sistemi per cercare di ingannarli, ma questo approccio sarà sempre limitato da ciò che sappiamo può andare storto. “Ma questo ci sta dando – se vogliamo investire l’energia – un nuovo strumento per far emergere problemi sconosciuti sconosciuti”, dice. “Sembra che ogni generazione di questi strumenti ci stia avvicinando ad essere in grado di capire veramente cosa sta succedendo in queste reti”.