Gli agenti addestrati OpenAI in un semplice gioco di nascondino e hanno appreso molte altre abilità diverse nel processo.
La concorrenza è una delle dinamiche socio-economiche che ha influenzato le nostre evoluzioni come specie. La grande quantità di complessità e diversità sulla Terra si è evoluta a causa della coevoluzione e della competizione tra organismi, diretta dalla selezione naturale. Competendo contro una parte diversa, siamo costantemente costretti a migliorare le nostre conoscenze e abilità su una materia specifica. I recenti sviluppi nell’intelligenza artificiale (AI) hanno iniziato a sfruttare alcuni dei principi della concorrenza per influenzare i comportamenti di apprendimento negli agenti dell’IA. In particolare, il campo dell’apprendimento di rinforzo multi-agente (MARL) è stato fortemente influenzato dalle dinamiche competitive e teoriche del gioco. Recentemente, i ricercatori di OpenAI hanno iniziato addestrando alcuni agenti di intelligenza artificiale in un semplice gioco di nascondino e saranno scioccati da alcuni dei comportamenti sviluppati dagli agenti in modo organico.affascinante documento di ricerca appena pubblicato .
L’apprendimento tramite competizione è uno dei paradigmi emergenti nell’intelligenza artificiale che ricorda fatalmente come la nostra conoscenza si evolve come specie umana. Dato che siamo bambini, sviluppiamo nuove conoscenze esplorando l’ambiente circostante e interagendo con altre persone, a volte in modo collaborativo, a volte secondo modelli competitivi. Questa dinamica contrasta con il modo in cui progettiamo oggi i sistemi di intelligenza artificiale. Mentre i metodi di apprendimento supervisionato rimangono il paradigma dominante nell’intelligenza artificiale, è relativamente poco pratico applicarlo a molte situazioni del mondo reale. Ciò è ancora più accentuato negli ambienti in cui gli agenti devono interagire con oggetti fisici in un ambiente relativamente sconosciuto. In tali contesti, è più naturale che gli agenti collaborino e / o competano costantemente contro altri agenti sviluppando nuove conoscenze organiche.
Autocurriculum multi-agente e comportamento emergente
Uno degli effetti collaterali dell’apprendimento mediante competizione è che gli agenti sviluppano comportamenti inaspettati. Nella teoria dell’IA, questo è noto come agente autocurricula e rappresenta una prima fila per osservare come si sviluppa la conoscenza. Immagina di allenare un agente di intelligenza artificiale a padroneggiare un gioco specifico e, all’improvviso, l’agente trova una strategia che non è mai stata testata prima. Mentre il fenomeno degli autocurricoli si verifica nei sistemi di apprendimento del rinforzo per singolo agente, è ancora più impressionante quando si sviluppa dalla concorrenza che è ciò che è noto come autocurriculum multi-agente.
In un ambiente di intelligenza artificiale multi-agente competitivo, i diversi agenti competono l’uno contro l’altro per valutare strategie specifiche. Quando emerge una nuova strategia o mutazione di successo, cambia la distribuzione di compiti impliciti che gli agenti vicini devono risolvere e crea una nuova pressione per l’adattamento.Queste razze di armi evolutive creano impliciti autocurricoli in base ai quali gli agenti concorrenti creano continuamente nuovi compiti reciproci.Un elemento chiave dell’autocurriculum multi-agente è che il comportamento emergente appreso dagli agenti si evolve organicamente e non è il risultato di meccanismi di incentivazione precostruiti. Non sorprende che l’autocurricula multi-agente sia stata una delle tecniche di maggior successo quando si tratta di addestrare gli agenti di intelligenza artificiale nei giochi multi-giocatore.
Agenti di formazione in nascondino
Gli esperimenti iniziali di OpenAI erano mirati a formare una serie di agenti di apprendimento del rinforzo per padroneggiare il gioco del nascondino. Nell’ambito del bersaglio, gli agenti hanno il compito di competere in un gioco a nascondino a due squadre in un ambiente basato sulla fisica. I cacciatori hanno il compito di evitare la linea di vista dai ricercatori e i ricercatori hanno il compito di mantenere la visione dei cacciatori. Ci sono oggetti sparsi in tutto l’ambiente che gli agenti possono afferrare e anche bloccare in posizione. Ci sono anche stanze e muri immobili generati casualmente che gli agenti devono imparare a navigare. L’ambiente OpenAI non contiene incentivi espliciti per gli agenti di interagire con gli oggetti. Gli agenti ricevono una ricompensa basata sul team; ai cacciatori viene dato un premio di +1 se tutti i cacciatori sono nascosti e -1 se un cacciatore viene visto da un cercatore. Ai cercatori viene data la ricompensa opposta, -1 se tutti i cursori sono nascosti e +1 in caso contrario. Per limitare il comportamento degli agenti in uno spazio ragionevole, gli agenti vengono penalizzati se vanno troppo fuori dall’area di gioco. Durante la fase di preparazione, a tutti gli agenti viene assegnata una ricompensa zero.

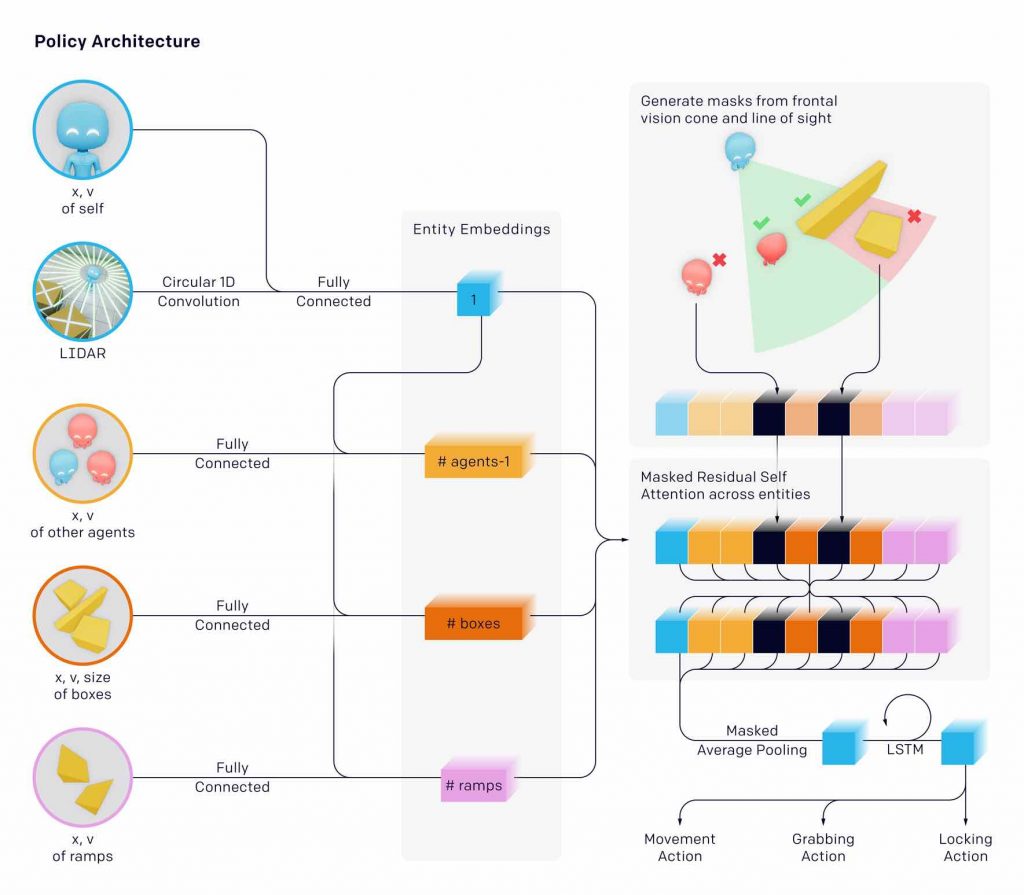
Per addestrare gli agenti a nascondino, i ricercatori OpenAI hanno sfruttato l’infrastruttura di allenamento utilizzata in altri giochi multi-player come OpenAI Five e Dactyl. Questo tipo di infrastruttura si basa su una rete politica in cui gli agenti vengono addestrati usando il gioco personale, che funge da curriculum naturale in quanto gli agenti giocano sempre avversari di livello adeguato. Le politiche degli agenti sono composte da due reti separate con parametri diversi: una rete di politiche che produce una distribuzione di azioni e una rete critica che predice i rendimenti futuri scontati. Ogni oggetto viene incorporato e quindi passato attraverso un blocco di auto-attenzione residuo mascherato, simile a quelli utilizzati nei trasformatori, in cui l’attenzione è rivolta agli oggetti anziché al tempo. Gli oggetti che non sono in linea di vista e di fronte all’agente sono mascherati in modo tale che l’agente non ne abbia alcuna informazione.
Autocurriculum e comportamenti emergenti in nascondino
Dato che gli agenti dell’intelligenza artificiale competono l’uno contro l’altro nell’ambiente spiegato prima, non solo hanno imparato a nascondino ma hanno sviluppato ben sei strategie distinte che non facevano parte degli incentivi iniziali.
Inizialmente, i cacciatori e i cercatori imparano a fuggire grossolanamente e inseguire. Dopo circa 25 milioni di episodi di nascondino, i cacciatori imparano a usare gli strumenti a loro disposizione e a modificare intenzionalmente il loro ambiente. Cominciano a costruire rifugi sicuri in cui nascondersi spostando molte scatole insieme o contro i muri e bloccandole in posizione. Dopo altri 75 milioni di episodi, i cercatori imparano anche l’uso rudimentale degli strumenti; imparano a muoversi e usano le rampe per saltare oltre gli ostacoli, permettendo loro di entrare nel rifugio dei cacciatori. 10 milioni di episodi dopo, i cacciatori imparano a difendersi da questa strategia; i cacciatori imparano a portare le rampe al limite dell’area di gioco e bloccarle in posizione, apparentemente rimuovendo l’unico strumento che i cercatori hanno a disposizione. Allo stesso modo, dopo 380 milioni di episodi totali di allenamento, i cercatori imparano a portare una scatola sul bordo dell’area di gioco dove i cacciatori hanno bloccato le rampe. I cercatori quindi saltano in cima alla scatola e navigano fino al rifugio dei cacciatori; ciò è possibile perché l’ambiente consente agli agenti di muoversi insieme alla scatola indipendentemente dal fatto che siano a terra o meno. In risposta, i cacciatori imparano a bloccare tutte le scatole in posizione prima di costruire il loro rifugio. La figura seguente mostra alcuni di questi comportamenti emergenti.
La cosa affascinante del comportamento emergente sviluppato dagli agenti nascondino è che si sono evoluti completamente organicamente come parte dell’autocurriculum indotto dalla competizione interna. In quasi tutti i casi, le prestazioni dei comportamenti emergenti erano superiori a quelle apprese da motivazioni intrinseche.
Gli esperimenti di nascondino di OpenAI erano assolutamente affascinanti e una chiara dimostrazione del potenziale degli ambienti competitivi multi-agente come catalizzatore per l’apprendimento. Molte delle tecniche OpenAI possono essere estrapolate ad altri scenari di intelligenza artificiale in cui l’apprendimento per competizione sembra un’alternativa più praticabile rispetto alla formazione supervisionata.