Apprendimento automatico VS apprendimento profondo. Fine del gioco?
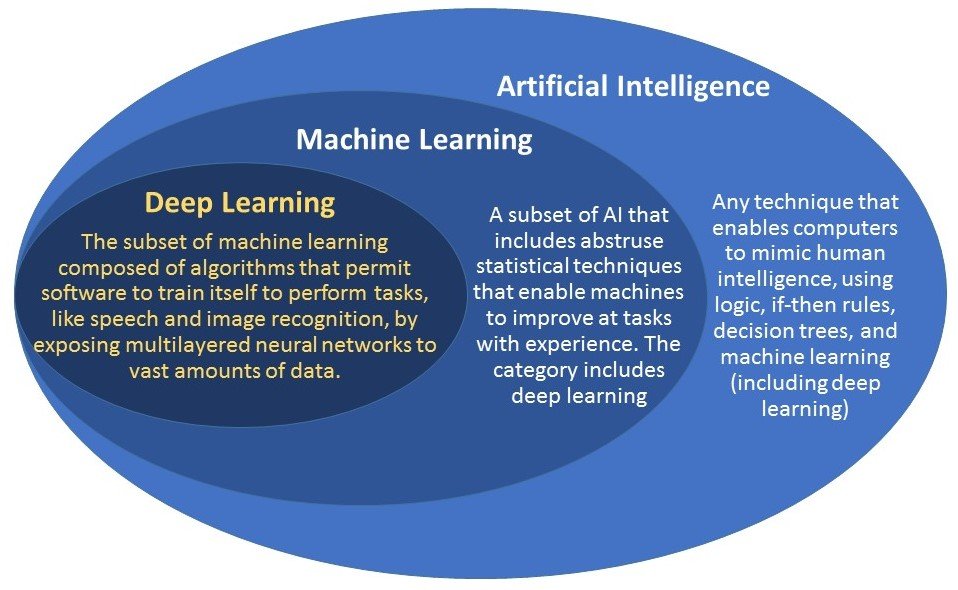
Itermini Machine Learning e Deep Learning verranno spesso inseriti nello stesso paniere, ma quali sono e qual è il loro ruolo? Per comprendere questi aspetti, il primo passo è il loro posizionamento all’interno del più ampio ombrello di AI (AGI).
Per affrontare i limiti, le caratteristiche e le differenze di questi campi, è necessario sapere cos’è un algoritmo poiché è la materia prima dell’intelligenza artificiale e quindi dell’apprendimento automatico e dell’apprendimento profondo.
Che cos’è un algoritmo?
Un algoritmo è un insieme di istruzioni che risolvono un problema. Queste istruzioni devono essere finite, ordinate e logiche, in altre parole, non possono essere un numero infinito di istruzioni. Sono sequenze e devono essere inequivocabili.
Quando si progetta un algoritmo che soddisfa queste caratteristiche, è possibile programmarlo su un computer, che può seguire le istruzioni e risolvere un determinato problema. Una buona analogia è una ricetta di cucina, poiché rispetta un insieme di istruzioni finite, una sequenza e una logica, con l’obiettivo di preparare un piatto.
In tal caso, che cos’è “AI”?
A partire dal punto nella storia in cui è stata formalizzata la teoria dei computer, l’IA è stata normalmente definita come un’area in cui è possibile studiare la progettazione di processi in grado di risolvere matematicamente i problemi rappresentati e automatizzare questi processi attraverso computer che influiscono sulla capacità di risolvere problemi e spesso supera l’abilità degli umani.
Confrontando la capacità di questi team con l’intelligenza umana e chirurgica, sorge la seguente domanda: i team sono intelligenti? Da una prospettiva psicologica, ci sono molteplici intelligenze e variabili, frequenze di contesti e scienze che studiano questo concetto. Quindi, non esiste una definizione esatta di intelligenza artificiale .
In linea di principio, possiamo dire che l’intelligenza artificiale è un nuovo campo di ricerca nell’ambito dell’informatica dedicato alla progettazione di algoritmi che risolvono i problemi attraverso l’apprendimento al computer. Ogni algoritmo ha i suoi metodi e caratteristiche e, a causa di quanto sopra, hanno prestazioni diverse per risolvere problemi specifici.
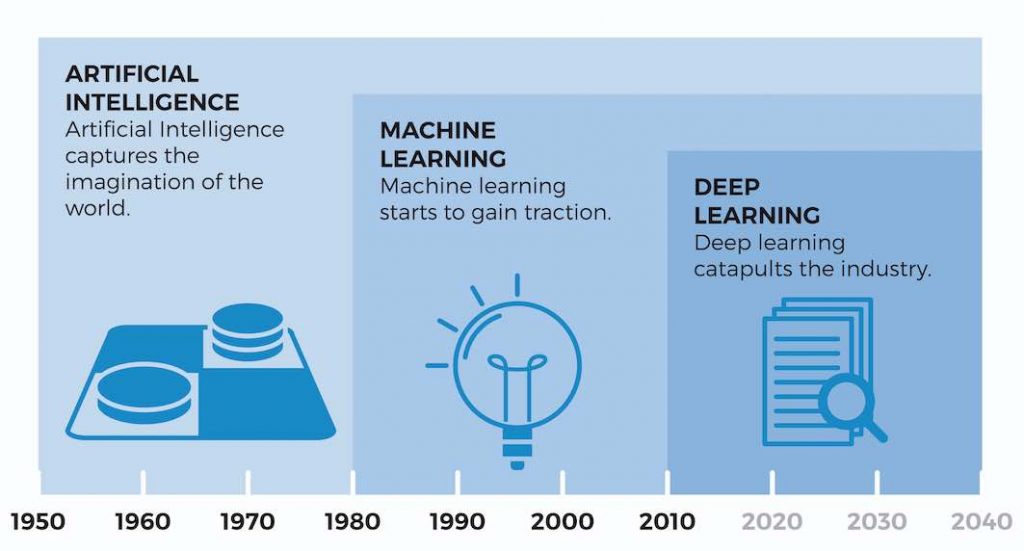
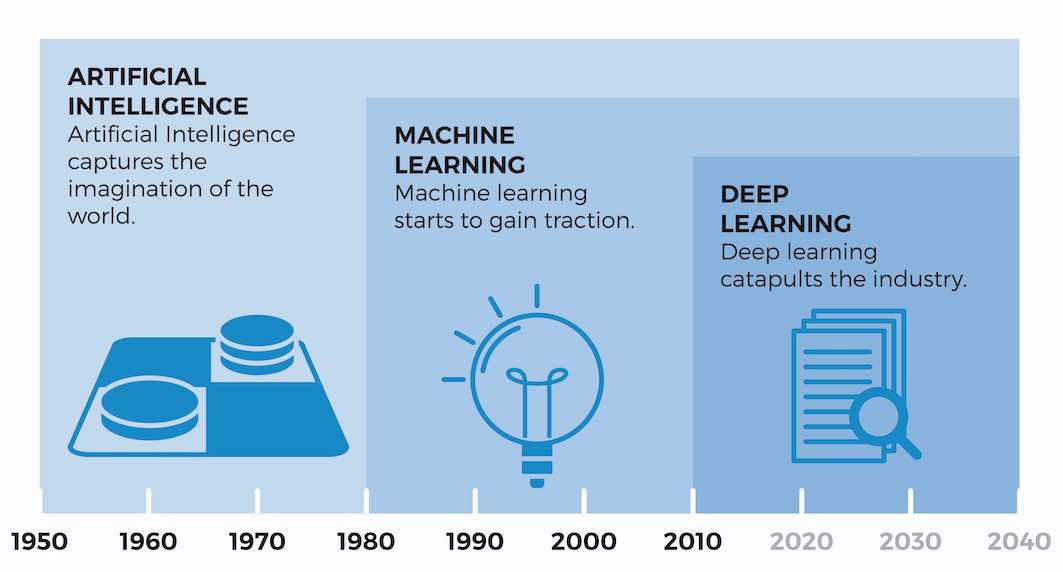
Negli ultimi 50 anni di storia umana, è stato progettato un gran numero di algoritmi, che possono essere definiti “intelligenti”, e poiché ce ne sono così tanti, è necessario classificarli in base alle loro proprietà e ai tipi di problemi per i quali forniscono soluzioni. La categoria più eccezionale degli ultimi anni è l’apprendimento automatico
Okay … cos’è l’apprendimento automatico, allora?
È un sottocampo dell’intelligenza artificiale che ha selezionato algoritmi per l’analisi dei dati, apprende da essi ed esegue diversi compiti come classificazione , previsione e raggruppamenti di modelli , tra gli altri. Questo processo viene eseguito attraverso un ampio set di dati, attraverso il quale è possibile addestrare questi algoritmi.
All’interno dell’apprendimento automatico, abbiamo due grandi gruppi: apprendimento supervisionato e non supervisionato .
Apprendimento supervisionato
Ha una serie di dati etichettati per addestrare l’algoritmo e ciò che l’algoritmo sta cercando è valutare un modello sconosciuto e decidere la classe a cui appartiene.
Ad esempio, se vogliamo classificare a quale stagione della moda appartiene un capo, ciò di cui abbiamo bisogno è avere un set di capi con le loro caratteristiche ed etichette in base alla stagione a cui appartengono: stagione primavera / estate o stagione autunno / inverno. Queste caratteristiche possono essere: colore, materiale, trama, design, marchio, tipo di stiratura, tra gli altri.
Con queste informazioni, possiamo addestrare l’algoritmo di apprendimento supervisionato per poter decidere a quale stagione appartiene un capo senza averlo conosciuto prima.
Apprendimento senza supervisione
Nel caso di algoritmi senza supervisione, il loro compito è trovare relazioni tra modelli che non sono stati precedentemente etichettati. Nel caso dell’esempio precedente, se gli abiti non fossero etichettati per la stagione della moda, l’algoritmo dovrebbe etichettare da solo gli abiti della stagione autunno / inverno e differenziarli dall’altra classe.
Va notato che molti degli algoritmi che compongono questo campo sono stati creati anni fa, ma a causa della bassa capacità computazionale e della mancanza di dati, il loro uso non è stato possibile.
Il gioco finale: che cos’è l’apprendimento profondo?
Nasce dalla ricerca per simulare il processo di apprendimento degli umani usando la conoscenza che abbiamo del funzionamento delle reti neurali nel cervello. In questo modo, si è tentato che i computer imparassero allo stesso modo degli umani.
La prima rete neurale artificiale fu creata nel 1943 dal neurologo Warren McCulloch e Walter Harry Pitts, che erano impegnati in neuroscienze computazionali. Da questo momento in poi, furono pubblicati diversi lavori rilevanti, ma solo negli anni ’80 iniziarono ad avere una grande rilevanza nel mondo della ricerca, ed è stato negli ultimi dieci anni che sono entrati in pratica.
Una rete neurale è formata da un insieme di neuroni collegati tra loro, ogni neurone ha la capacità di apprendere e trasmettere tale conoscenza ad altri neuroni. Nell’immagine seguente puoi vedere com’è una rete, dove i punti rappresentano i neuroni e le linee che collegano i nodi tra di loro.
A causa del fatto che, negli ultimi anni, il potere computazionale e di archiviazione è aumentato, è stato possibile creare reti neurali artificiali con centinaia di migliaia di neuroni, il che ha portato a nominare il campo di ricerca dedicato allo studio di queste reti “Apprendimento approfondito”.
Attualmente, l’apprendimento profondo rientra nel campo dell’apprendimento automatico poiché le reti neurali risolvono lo stesso tipo di problemi degli algoritmi in questo campo, tuttavia l’area sta crescendo rapidamente e generando molteplici branche della ricerca.
Le reti neurali sono principalmente utilizzate per risolvere problemi di classificazione delle immagini , analisi del linguaggio naturale , come il riconoscimento vocale e la creazione di testi , ad esempio creando notizie, poesie o micro-storie.