Il metodo tradizionale di formazione dei modelli di intelligenza artificiale prevede la creazione di server in cui i modelli sono formati sui dati, spesso attraverso l’uso di una piattaforma informatica basata su cloud. Tuttavia, negli ultimi anni è emersa una forma alternativa di creazione di modelli, chiamata apprendimento federato. L’apprendimento federato porta modelli di apprendimento automatico all’origine dati, piuttosto che portare i dati al modello. L’apprendimento federato collega più dispositivi computazionali in un sistema decentralizzato che consente ai singoli dispositivi che raccolgono dati di assistere nella formazione del modello.
In un sistema di apprendimento federato, i vari dispositivi che fanno parte della rete di apprendimento hanno ciascuno una copia del modello sul dispositivo. I diversi dispositivi / client addestrano la propria copia del modello utilizzando i dati locali del client, quindi i parametri / pesi dei singoli modelli vengono inviati a un dispositivo master o server che aggrega i parametri e aggiorna il modello globale. Questo processo di allenamento può quindi essere ripetuto fino a raggiungere il livello di precisione desiderato. In breve, l’idea alla base dell’apprendimento federato è che nessuno dei dati di training viene mai trasmesso tra dispositivi o tra parti, solo gli aggiornamenti relativi al modello lo sono.
L’apprendimento federato può essere suddiviso in tre diversi passaggi o fasi. L’apprendimento federato in genere inizia con un modello generico che funge da base e viene addestrato su un server centrale. Nel primo passaggio, questo modello generico viene inviato ai client dell’applicazione. Queste copie locali vengono quindi addestrate sui dati generati dai sistemi client, imparando e migliorando le loro prestazioni.
Nel secondo passaggio, tutti i client inviano i parametri del modello appreso al server centrale. Questo accade periodicamente, a orari prestabiliti.
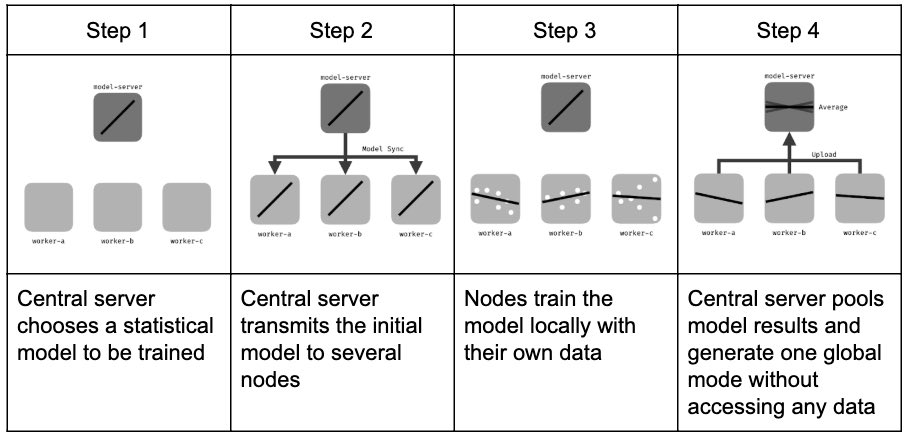
Nel terzo passaggio, il server aggrega i parametri appresi quando li riceve. Dopo l’aggregazione dei parametri, il modello centrale viene aggiornato e condiviso ancora una volta con i client. L’intero processo si ripete quindi.
Il vantaggio di avere una copia del modello sui vari dispositivi è che le latenze di rete vengono ridotte o eliminate. Vengono eliminati anche i costi associati alla condivisione dei dati con il server. Altri vantaggi dei metodi di apprendimento federati includono il fatto che i modelli di apprendimento federati sono preservati dalla privacy e le risposte dei modelli sono personalizzate per l’utente del dispositivo.
Esempi di modelli di apprendimento federati includono motori di raccomandazione, modelli di rilevamento delle frodi e modelli medici. I motori di raccomandazione dei media, del tipo utilizzato da Netflix o Amazon, potrebbero essere formati sui dati raccolti da migliaia di utenti. I dispositivi client formerebbero i propri modelli separati e il modello centrale imparerebbe a fare previsioni migliori, anche se i singoli punti dati sarebbero unici per i diversi utenti. Allo stesso modo, i modelli di rilevamento delle frodi utilizzati dalle banche possono essere formati su modelli di attività da molti dispositivi diversi e una manciata di banche diverse potrebbero collaborare per formare un modello comune. In termini di un modello di apprendimento federato medico, più ospedali potrebbero unirsi per formare un modello comune in grado di riconoscere potenziali tumori attraverso scansioni mediche.
Tipi di apprendimento federato
Gli schemi di apprendimento federati rientrano in genere in una di due classi diverse : sistemi multipartitici e sistemi monopartitici. I sistemi di apprendimento federati a partito singolo sono chiamati “partito unico” perché solo una singola entità è responsabile della supervisione dell’acquisizione e del flusso di dati attraverso tutti i dispositivi client nella rete di apprendimento. I modelli esistenti sui dispositivi client vengono addestrati sui dati con la stessa struttura, sebbene i punti dati siano in genere univoci per i vari utenti e dispositivi.
A differenza dei sistemi a partito singolo, i sistemi a partito multiplo sono gestiti da due o più entità. Queste entità cooperano per formare un modello condiviso utilizzando i vari dispositivi e set di dati a cui hanno accesso. I parametri e le strutture dati sono in genere simili tra i dispositivi appartenenti a più entità, ma non devono essere esattamente gli stessi. Invece, la pre-elaborazione viene eseguita per standardizzare gli input del modello. Un’entità neutra potrebbe essere impiegata per aggregare i pesi stabiliti dai dispositivi unici per le diverse entità.
Tecnologie e quadri comuni per l’apprendimento federato
I framework popolari utilizzati per l’apprendimento federato includono Tensorflow Federated , Federated AI Technology Enabler (FATE) e PySyft . PySyft è una libreria di apprendimento federata open source basata sul deep learninglibreria PyTorch. PySyft ha lo scopo di garantire l’apprendimento approfondito privato e sicuro tra server e agenti utilizzando il calcolo crittografato. Nel frattempo, Tensorflow Federated è un altro framework open source costruito sulla piattaforma Tensorflow di Google. Oltre a consentire agli utenti di creare i propri algoritmi, Tensorflow Federated consente agli utenti di simulare una serie di algoritmi di apprendimento federati inclusi sui propri modelli e dati. Infine, FATE è anche un framework open source progettato da Webank AI ed è destinato a fornire all’ecosistema AI federato un framework di elaborazione sicuro.
Sfide di apprendimento federate
Poiché l’apprendimento federato è ancora abbastanza nascente, è necessario negoziare una serie di sfide per raggiungere il suo pieno potenziale. Le capacità di formazione dei dispositivi periferici, l’etichettatura e la standardizzazione dei dati e la convergenza dei modelli sono potenziali ostacoli per gli approcci di apprendimento federato.
Le capacità computazionali dei dispositivi periferici, quando si tratta di formazione locale, devono essere prese in considerazione quando si progettano approcci di apprendimento federati. Mentre la maggior parte degli smartphone, tablet e altri dispositivi compatibili con IoT sono in grado di formare modelli di machine learning, ciò generalmente ostacola le prestazioni del dispositivo. Si dovranno scendere a compromessi tra l’accuratezza del modello e le prestazioni del dispositivo.
L’etichettatura e la standardizzazione dei dati è un’altra sfida che i sistemi di apprendimento federati devono superare. I modelli di apprendimento supervisionato richiedono dati di formazione che siano etichettati in modo chiaro e coerente, il che può essere difficile da eseguire su molti dispositivi client che fanno parte del sistema. Per questo motivo, è importante sviluppare pipeline di dati modello che applicano automaticamente le etichette in modo standardizzato in base agli eventi e alle azioni dell’utente.
Il tempo di convergenza dei modelli è un’altra sfida per l’apprendimento federato, poiché i modelli di apprendimento federato impiegano generalmente più tempo a convergere rispetto ai modelli formati localmente. Il numero di dispositivi coinvolti nella formazione aggiunge un elemento di imprevedibilità alla formazione del modello, poiché problemi di connessione, aggiornamenti irregolari e persino tempi di utilizzo dell’applicazione diversi possono contribuire ad aumentare i tempi di convergenza e ridurre l’affidabilità. Per questo motivo, le soluzioni di apprendimento federate sono in genere più utili quando offrono vantaggi significativi rispetto alla formazione centralizzata di un modello, ad esempio casi in cui i set di dati sono estremamente grandi e distribuiti.