La personalizzazione dei sistemi basati sul machine learning è fondamentale per offrire ottime esperienze utente.
Applica il trucco, fatti crescere la barba o siediti al buio, il tuo iPhone può ancora riconoscerti, non importa quanto tu sia diverso dalla foto del passaporto. La tecnologia che abilita Face ID su Apple è una delle soluzioni hardware e software più avanzate della casa del colosso di Cupertino. Ad esempio, la fotocamera TrueDepth acquisisce dati accurati del viso proiettando e analizzando oltre 30.000 punti invisibili per creare una mappa di profondità del viso dell’utente. Una parte del motore neurale del chip A13 Bionic, protetto all’interno di Secure Enclave, trasforma la mappa di profondità e l’immagine a infrarossi in una rappresentazione matematica e confronta tale rappresentazione con i dati facciali registrati.
L’apprendimento automatico sul dispositivo comporta una sfida per la privacy. La misura in cui le telecamere e i microfoni registrano i dati può mettere un individuo a grande rischio se i suoi telefoni vengono violati. Esiste una grande possibilità che le app espongano un meccanismo di ricerca per il recupero delle informazioni o la navigazione in-app. Quindi, i produttori di smartphone come Apple si sono avventurati nel Federated Learning da più di un paio d’anni.
“Federated Learning funziona sull’approccio di portare il codice ai dati, invece dei dati al codice.”
Federated Learning (FL) è un approccio di machine learning distribuito che consente la formazione su un ampio corpus di dati decentralizzati che risiedono su dispositivi come i telefoni cellulari. Le tecniche di Federated Learning vengono utilizzate per addestrare i modelli ML per l’attivazione della funzione di suggerimento, nonché per classificare gli elementi che possono essere suggeriti nel contesto corrente.
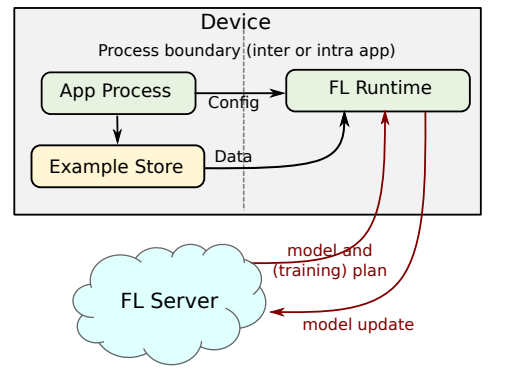
Un tipico protocollo di apprendimento federato (Fonte: Google AI)
I dispositivi chiamano server di apprendimento federati.
Il server legge il punto di controllo del modello dalla memoria.
I modelli vengono inviati ai dispositivi selezionati.
L’addestramento del modello avviene sul dispositivo e viene aggiornato di nuovo sul server.
Il server aggrega questi aggiornamenti in un modello globale e li scrive nella memoria.
L’apprendimento federato si applica meglio nelle situazioni in cui i dati sul dispositivo sono più rilevanti dei dati che esistono sui server (ad esempio, i dispositivi generano i dati in primo luogo), sono sensibili alla privacy o altrimenti indesiderabili o impossibili da trasmettere ai server . Per affrontare i limiti dell’apprendimento federato, i ricercatori Apple hanno sperimentato altri sistemi federati che eseguono la valutazione e l’ottimizzazione (FE&T).
Come lo fa Apple
“Le condizioni attorno alla nostra personalizzazione ci hanno portato a considerare FE&T dei sistemi ML su dispositivo”.
Paulik et al.
La maggior parte delle funzionalità di Apple sono estensioni dell’apprendimento federato in un certo senso. Ma i ricercatori, nel loro lavoro, hanno approfondito il motivo per cui hanno esplorato la valutazione e l’ottimizzazione federate (FE&T). Differenziando tra FL e FT, scrivono che Federated Learning (FL) richiede la valutazione del modello su dati federati forniti. FL apprende i parametri di modelli neurali globali a volte di grandi dimensioni. Mentre in Federated Tuning (FT), l’apprendimento avviene principalmente sul server centrale ed è limitato a un insieme relativamente piccolo di parametri dell’algoritmo di personalizzazione che vengono valutati attraverso dati federati. All’interno dei sistemi Apple, sono state utilizzate applicazioni di apprendimento federate per migliorare i modelli di attivazione di parole chiave acustiche o l’apprendimento federato di modelli linguistici per una migliore esperienza di tastiera predittiva e correzione degli errori.
Le applicazioni intorno a FE e FT occupano un’ampia percentuale di utilizzo del sistema. Ad esempio, FE si verifica nella cronologia delle interazioni dell’utente. Ciò riduce significativamente i tempi di risposta rispetto alla sperimentazione A / B dal vivo. La valutazione federata, hanno scritto i ricercatori, può aiutare a identificare rapidamente il sistema ML o il modello di candidati più promettenti prima di esporre gli utenti finali a questi candidati tramite la sperimentazione A / B dal vivo.
“Sui dispositivi Apple, i componenti del sistema sul dispositivo non sono quindi incentrati su una libreria di addestramento del modello neurale per l’esecuzione delle attività. Invece, l’implementazione dell’esecuzione delle attività sul dispositivo è delegata a plug-in specifici dell’applicazione che comunicano con la logica di pianificazione delle attività sul dispositivo, l’archivio dati e la logica di reporting dei risultati del nostro sistema “, hanno spiegato i ricercatori.
Secondo i ricercatori di ML di Apple, l’elaborazione sui dispositivi degli utenti finali rispetto all’elaborazione basata su server è un approccio prezioso per garantire la privacy dell’utente finale. Questa strategia si estende a molte delle soluzioni machine learning (ML) di Apple, come la previsione del testo nelle tastiere. La capacità di personalizzazione in base alla dizione dell’utente è altamente desiderabile poiché l’obiettivo finale della personalizzazione basata sul machine learning è una migliore esperienza utente.
Ecco come funziona la personalizzazione delle notizie sul tuo iPhone:
Ricava verità di base e valutazione sul dispositivo per la personalizzazione delle notizie, dalle interazioni degli utenti con i contenuti delle notizie.
Memorizza le informazioni sul dispositivo per articoli come: tocca e leggi è un’etichetta positiva e tocca e non letto è un’etichetta negativa.
Il sistema attribuisce un intervallo di valori per ogni parametro.
Durante l’esecuzione dell’attività di ottimizzazione, il plug-in esegue una ricerca griglia casuale e genera in modo casuale le configurazioni.
Queste configurazioni vengono applicate all’algoritmo di personalizzazione che prevede la probabilità che un utente legga un articolo.
Le previsioni vengono quindi confrontate con le etichette di verità fondamentali per calcolare una perdita di previsione per ciascuna configurazione generata casualmente.
La personalizzazione della lettura di notizie o di qualsiasi altra applicazione basata su ML è fondamentale per le convinzioni fondamentali di Apple e quindi i sistemi federati sono diventati fondamentali per mantenere gli standard di privacy nella ricerca di migliorare l’esperienza dell’utente. Gli algoritmi sui telefoni Apple sono regolati da diversi parametri, come l’emivita del decadimento temporale sul punteggio personalizzato di un articolo e quando le notizie cambiano, la regolazione di questi parametri diventa difficile. È qui che FT torna utile. Consente un adattamento continuo di questi parametri con tempi di risposta rapidi in modo che i contenuti più rilevanti possano essere visualizzati nonostante le mutevoli tendenze. I ricercatori hanno affermato che l’utilizzo di FT ha portato a un aumento dell’1,98% delle visualizzazioni giornaliere degli articoli e dello 0,90% del tempo giornaliero trascorso all’interno dell’applicazione in due esperimenti separati.