In che modo il tuo telefono può determinare cos’è un oggetto semplicemente scattandone una foto? In che modo i siti web dei social media taggano automaticamente le persone nelle foto? Ciò è possibile grazie al riconoscimento e alla classificazione delle immagini basati sull’intelligenza artificiale.
Il riconoscimento e la classificazione delle immagini è ciò che consente molti dei risultati più impressionanti dell’intelligenza artificiale. Ma come imparano i computer a rilevare e classificare le immagini? In questo articolo, tratteremo i metodi generali che i computer utilizzano per interpretare e rilevare le immagini e quindi daremo uno sguardo ad alcuni dei metodi più popolari per classificare tali immagini.
Classificazione a livello di pixel e basata su oggetti
Tecniche di classificazione delle immagini possono essenzialmente essere suddivisi in due categorie: la classificazione basata sui pixel e classificazione basato su oggetti.
I pixel sono le unità di base di un’immagine e l’analisi dei pixel è il modo principale in cui viene eseguita la classificazione dell’immagine. Tuttavia, gli algoritmi di classificazione possono utilizzare solo le informazioni spettrali all’interno dei singoli pixel per classificare un’immagine o esaminare le informazioni spaziali (pixel vicini) insieme alle informazioni spettrali. I metodi di classificazione basati sui pixel utilizzano solo informazioni spettrali (l’intensità di un pixel), mentre i metodi di classificazione basati su oggetti tengono conto sia delle informazioni spettrali dei pixel che delle informazioni spaziali.
Esistono diverse tecniche di classificazione utilizzate per la classificazione basata sui pixel. Questi includono distanza minima dalla media, massima probabilità e distanza minima di Mahalanobis. Questi metodi richiedono che le medie e le varianze delle classi siano note e funzionano tutte esaminando la “distanza” tra le medie delle classi ei pixel target.
I metodi di classificazione basati sui pixel sono limitati dal fatto che non possono utilizzare le informazioni di altri pixel vicini. Al contrario, i metodi di classificazione basata sugli oggetti possono includere altri pixel e quindi utilizzano anche le informazioni spaziali per classificare gli elementi. Notare che “oggetto” si riferisce solo a regioni di pixel contigue e non se c’è o meno un oggetto di destinazione all’interno di quella regione di pixel.
Pre-elaborazione dei dati dell’immagine per il rilevamento di oggetti
I sistemi di classificazione delle immagini più recenti e affidabili utilizzano principalmente schemi di classificazione a livello di oggetto e per questi approcci i dati delle immagini devono essere preparati in modi specifici. Gli oggetti / le regioni devono essere selezionati e preelaborati.
Prima che un’immagine e gli oggetti / regioni all’interno di quell’immagine possano essere classificati, i dati che compongono quell’immagine devono essere interpretati dal computer. Le immagini devono essere preelaborate e preparate per l’input nell’algoritmo di classificazione, e ciò avviene tramite il rilevamento di oggetti. Questa è una parte fondamentale della preparazione dei dati e della preparazione delle immagini per addestrare il classificatore di machine learning .
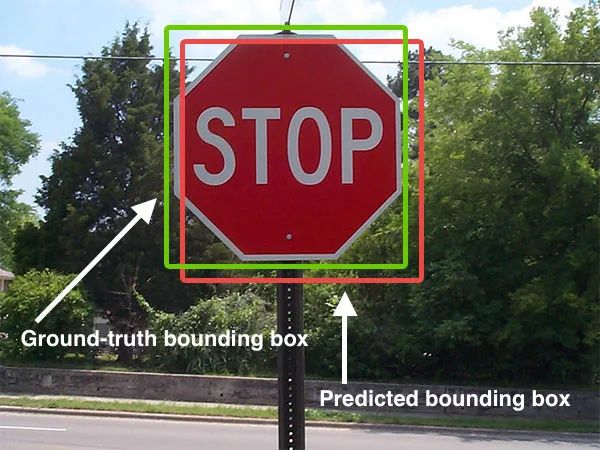
Il rilevamento degli oggetti viene eseguito con una varietà di metodi e tecniche. Per cominciare, la presenza o meno di più oggetti di interesse o di un singolo oggetto di interesse influisce sul modo in cui viene gestita la preelaborazione dell’immagine. Se c’è un solo oggetto di interesse, l’immagine subisce la localizzazione dell’immagine. I pixel che compongono l’immagine hanno valori numerici che vengono interpretati dal computer e utilizzati per visualizzare i colori e le tonalità appropriate. Un oggetto noto come riquadro di delimitazione viene disegnato attorno all’oggetto di interesse, il che aiuta il computer a sapere quale parte dell’immagine è importante e quali valori di pixel definiscono l’oggetto. Se ci sono più oggetti di interesse nell’immagine, viene utilizzata una tecnica chiamata rilevamento oggetti per applicare questi riquadri di delimitazione a tutti gli oggetti all’interno dell’immagine.
Un altro metodo di preelaborazione è la segmentazione delle immagini. La segmentazione dell’immagine funziona dividendo l’intera immagine in segmenti basati su caratteristiche simili. Diverse regioni dell’immagine avranno valori di pixel simili rispetto ad altre regioni dell’immagine, quindi questi pixel vengono raggruppati in maschere di immagine che corrispondono alla forma e ai bordi degli oggetti rilevanti all’interno dell’immagine. La segmentazione dell’immagine aiuta il computer a isolare le caratteristiche dell’immagine che lo aiuteranno a classificare un oggetto, proprio come fanno i riquadri di delimitazione, ma forniscono etichette a livello di pixel molto più accurate.
Dopo che il rilevamento degli oggetti o la segmentazione dell’immagine è stata completata, le etichette vengono applicate alle regioni in questione. Queste etichette vengono inserite, insieme ai valori dei pixel che compongono l’oggetto, negli algoritmi di apprendimento automatico che apprenderanno i modelli associati alle diverse etichette.
Algoritmi di machine learning
Una volta che i dati sono stati preparati ed etichettati, i dati vengono inseriti in un algoritmo di apprendimento automatico, che esegue il training sui dati. Di seguito tratteremo alcuni dei tipi più comuni di algoritmi di classificazione delle immagini di machine learning .
K-Nearest Neighbors
K-Nearest Neighbors è un algoritmo di classificazione che esamina gli esempi di addestramento più vicini e guarda le loro etichette per accertare l’etichetta più probabile per un dato esempio di test. Quando si tratta di classificazione delle immagini utilizzando KNN, i vettori delle caratteristiche e le etichette delle immagini di addestramento vengono memorizzati e solo il vettore delle caratteristiche viene passato all’algoritmo durante il test. I vettori delle funzionalità di addestramento e test vengono quindi confrontati tra loro per la somiglianza.
Gli algoritmi di classificazione basati su KNN sono estremamente semplici e gestiscono più classi abbastanza facilmente. Tuttavia, KNN calcola la somiglianza in base a tutte le caratteristiche allo stesso modo. Ciò significa che può essere soggetto a classificazioni errate se fornito con immagini in cui solo un sottoinsieme delle caratteristiche è importante per la classificazione dell’immagine.
Supporta macchine vettoriali
Le Support Vector Machines sono un metodo di classificazione che posiziona i punti nello spazio e quindi traccia le linee di divisione tra i punti, posizionando gli oggetti in classi diverse a seconda del lato del piano di divisione su cui cadono i punti. Le Support Vector Machine sono in grado di eseguire una classificazione non lineare tramite l’uso di una tecnica nota come trucco del kernel. Sebbene i classificatori SVM siano spesso molto precisi, uno svantaggio sostanziale dei classificatori SVM è che tendono ad essere limitati sia dalle dimensioni che dalla velocità, con la velocità che ne risente all’aumentare delle dimensioni.
Perceptrons multistrato (reti neurali)
I perceptrons multistrato, chiamati anche modelli di rete neurale, sono algoritmi di apprendimento automatico ispirati al cervello umano. I perceptrons multistrato sono composti da vari strati che sono uniti tra loro, proprio come i neuroni nel cervello umano sono collegati insieme. Le reti neurali fanno ipotesi su come le caratteristiche di input siano correlate alle classi dei dati e queste ipotesi vengono modificate nel corso dell’addestramento. Semplici modelli di rete neurale come il perceptron multistrato sono in grado di apprendere relazioni non lineari e, di conseguenza, possono essere molto più accurati di altri modelli. Tuttavia, i modelli MLP soffrono di alcuni problemi notevoli come la presenza di funzioni di perdita non convesse.
Algoritmi di deep learning (CNN)
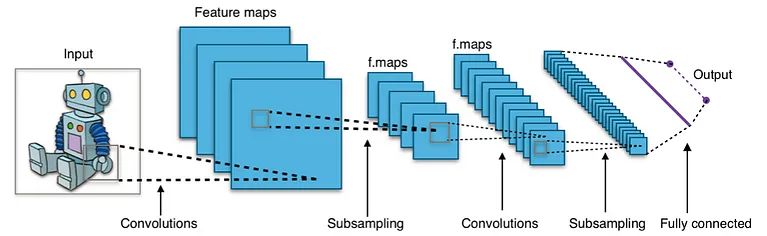
L’algoritmo di classificazione delle immagini più comunemente utilizzato negli ultimi tempi è la Convolutional Neural Network (CNN). Le CNN sono versioni personalizzate di reti neurali che combinano le reti neurali multistrato con strati specializzati in grado di estrarre le caratteristiche più importanti e rilevanti per la classificazione di un oggetto. Le CNN possono scoprire, generare e apprendere automaticamente le caratteristiche delle immagini. Ciò riduce notevolmente la necessità di etichettare e segmentare manualmente le immagini per prepararle per gli algoritmi di apprendimento automatico. Hanno anche un vantaggio rispetto alle reti MLP perché possono gestire funzioni di perdita non convesse.
Le reti neurali convoluzionali prendono il nome dal fatto che creano “convoluzioni”. Le CNN funzionano prendendo un filtro e facendolo scorrere su un’immagine. Puoi pensare a questo come alla visualizzazione di sezioni di un paesaggio attraverso una finestra mobile, concentrandoti solo sulle caratteristiche che sono visualizzabili attraverso la finestra in qualsiasi momento. Il filtro contiene valori numerici che vengono moltiplicati per i valori dei pixel stessi. Il risultato è una nuova cornice, o matrice, piena di numeri che rappresentano l’immagine originale. Questo processo viene ripetuto per un numero scelto di filtri, quindi i fotogrammi vengono uniti in una nuova immagine leggermente più piccola e meno complessa dell’immagine originale. Una tecnica chiamata pooling viene utilizzata per selezionare solo i valori più importanti all’interno dell’immagine,
Le reti neurali convoluzionali sono composte da due parti diverse. I livelli convoluzionali sono ciò che estrae le caratteristiche dell’immagine e le converte in un formato che i livelli della rete neurale possono interpretare e da cui apprendere. I primi strati convoluzionali sono responsabili dell’estrazione degli elementi più basilari dell’immagine, come linee e confini semplici. Gli strati convoluzionali centrali iniziano a catturare forme più complesse, come curve e angoli semplici. Gli strati convoluzionali successivi e più profondi estraggono le caratteristiche di alto livello dell’immagine, che sono ciò che viene passato nella porzione di rete neurale della CNN e sono ciò che apprende il classificatore.