I ricercatori e professionisti dell’IA stanno sviluppando e rilasciando nuovi sistemi e metodi a un ritmo estremamente rapido e può essere difficile per le imprese valutare quali particolari tecnologie di IA hanno maggiori probabilità di aiutare le loro imprese. Questo articolo, la prima parte di una serie in due parti , cercherà di aiutarti a determinare se l’apprendimento federato (FL), un pezzo abbastanza nuovo di tecnologia AI che preserva la privacy, è appropriato per un caso d’uso che hai in mente.
Lo scopo principale di FL è consentire l’uso dell’IA in situazioni in cui i problemi di riservatezza o riservatezza dei dati attualmente bloccano l’adozione. Spacchettiamo un po ‘questo. Lo scopo dei sistemi / metodi / algoritmi di intelligenza artificiale è quello di prendere dati e creare autonomamente pezzi di software, modelli di intelligenza artificiale, che trasformano i dati in informazioni fruibili. I moderni metodi di intelligenza artificiale richiedono in genere molti dati, raccolgono tutti i dati necessari in una posizione centrale ed eseguono un algoritmo di apprendimento sui dati per apprendere / creare il modello.
Tuttavia, quando i dati sono riservati , silos e di proprietà di entità diverse, non è possibile raccogliere i dati in una posizione centrale. L’apprendimento federato aggira in modo molto intelligente questo problema spostando l’algoritmo o il codice di apprendimento nei dati, piuttosto che portare i dati nel codice.
Ad esempio, si consideri il problema di creare un modello di intelligenza artificiale per prevedere se i pazienti hanno COVID-19 dopo le scansioni TC del polmone. I dati per questo problema, le scansioni TC, sono ovviamente confidenziali e sono di proprietà di varie entità diverse: ospedali e strutture mediche e di ricerca. Sono inoltre archiviati in tutto il mondo in giurisdizioni molto diverse. Vuoi combinare tutti questi dati perché vuoi che i tuoi modelli di intelligenza artificiale siano in grado di rilevare tutte le forme in cui la malattia si è manifestata nelle scansioni TC. Tuttavia, la combinazione di tutti questi dati in un’unica posizione non è possibile per ovvie ragioni di riservatezza e giurisdizione dei dati.
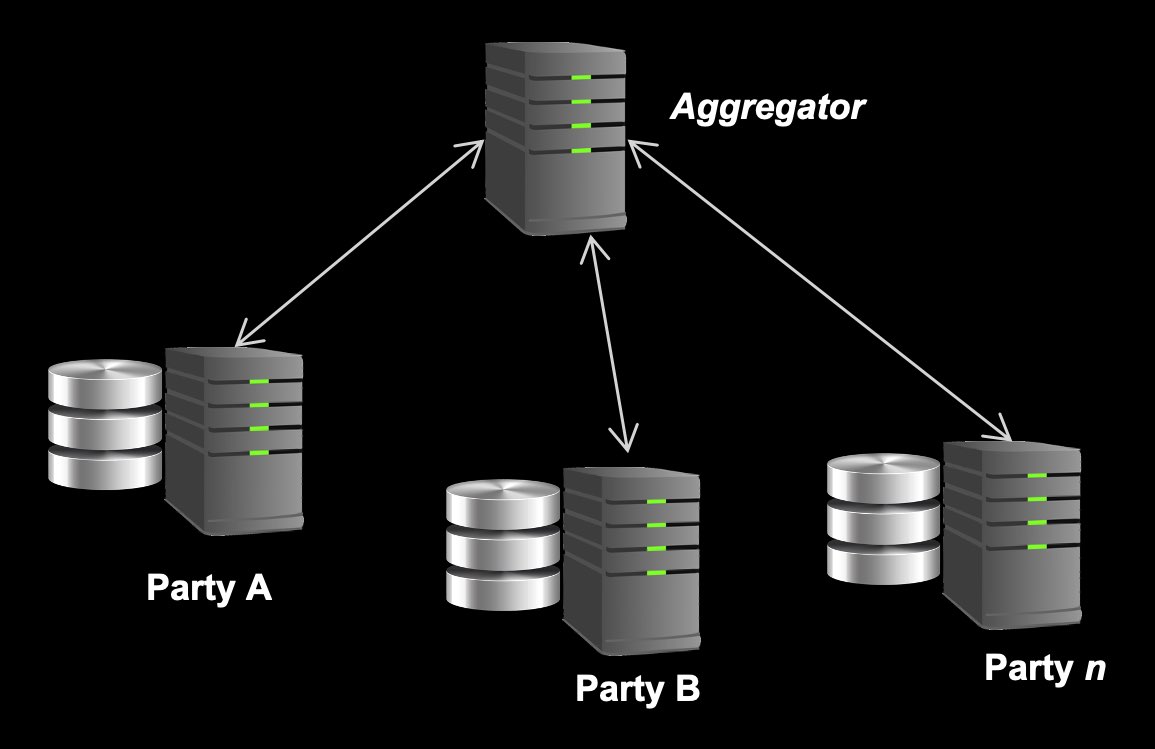
Ecco come l’apprendimento federato aggira il problema della riservatezza: un nodo di lavoro, che è un sistema informatico in grado di apprendere automaticamente, viene distribuito in ogni ospedale o struttura. Questo nodo di lavoro ha pieno accesso ai dati riservati nella posizione. Durante l’apprendimento federato, ciascuno di questi nodi di lavoro crea un modello AI locale utilizzando i dati presso la struttura e invia il modello al server FL centrale. Si noti che i dati riservati non lasciano mai il sito del client, solo il modello lo fa. Un server centrale combina tutte le informazioni dai modelli locali in un unico modello globale. Questo modello globale viene inviato di nuovo a tutti i nodi di lavoro locali, che ora hanno informazioni dettagliate da tutti gli altri nodi di lavoro senza aver visto i loro dati. Quando ripetete più volte questi passaggi, vi ritroverete con un modello che, in molti casi, equivalente a un modello che sarebbe stato costruito se lo avessi addestrato su tutti i dati nello stesso posto. (Vedere un’illustrazione schematica del processo di seguito.)
L’apprendimento federato è stato inizialmente sviluppato da Google come un modo per addestrare l’app per tastiera Android (GBoard) a prevedere cosa digiterà successivamente l’utente. Qui i dati riservati utilizzati sono il testo che l’utente sta digitando. Tuttavia, risulta che il problema della riservatezza dei dati appare in molti modi in tutti i settori. In effetti, dovrai affrontare questo problema se lo sei
- un produttore di veicoli a guida autonoma e desideri combinare dati riservati di video e immagini provenienti da tutti i tuoi veicoli per costruire un sistema di visione migliore,
- una banca e desidera costruire un sistema antiriciclaggio basato sull’apprendimento automatico combinando i dati di varie giurisdizioni, possibilmente anche di altre banche,
- un fornitore di piattaforme per la catena di approvvigionamento e desideri creare una migliore valutazione del rischio o un sistema di ottimizzazione del percorso combinando dati di vendita riservati di più aziende,
- un fornitore di servizi cellulari e desideri creare un modello di apprendimento automatico per ottimizzare i percorsi combinando i dati riservati dalle torri cellulari,
- un consorzio di agricoltori e desideri creare un modello per rilevare le malattie delle colture utilizzando dati riservati sulle malattie dei membri del consorzio,
- un consorzio di produttori di additivi e desideri creare controllori di processo basati su intelligenza artificiale e sistemi di garanzia della qualità utilizzando dati di build riservati dai membri del consorzio.
Un punto importante da notare riguardo agli esempi precedenti è che il proprietario dei dati può essere unità diverse della stessa organizzazione ma in giurisdizioni diverse (come negli esempi di fornitori di servizi bancari e cellulari) o clienti della stessa organizzazione (come negli esempi esempi di produttori di veicoli e fornitori di servizi per la catena di fornitura), o unità completamente indipendenti (come nel consorzio di agricoltori e esempi di produttori di additivi sopra, e nell’esempio di ospedali / COVID-19 descritto in precedenza).
Puoi utilizzare il seguente elenco di controllo per vedere se l’apprendimento federato ha senso per te:
Concluderò sottolineando che, se sei in grado di combinare i tuoi dati in una posizione centrale, dovresti probabilmente optare per questa opzione (salvo i casi in cui desideri, ad esempio, la soluzione a prova di futuro). La centralizzazione dei dati può portare a prestazioni del modello finale migliori di quelle che sarai in grado di ottenere con l’apprendimento federato e lo sforzo richiesto per distribuire una soluzione AI sarà notevolmente inferiore. Tuttavia, se si scopre che FL è proprio ciò di cui hai bisogno per rimuovere la tua barriera all’adozione dell’IA, la seconda parte di questa serie ti fornirà una panoramica su come farlo.
Hassan Mahmud
