Questo è il secondo articolo di una serie in due parti sull’apprendimento federato (FL). Parte 1 – Come sapere se l’apprendimento federato dovrebbe far parte della tua strategia sui dati – ti aiuterà a decidere se l’apprendimento federato è adatto a un caso d’uso che hai in mente. Questo articolo illustrerà i passaggi necessari per adattare l’apprendimento federato alla tua organizzazione.
- Inizia con un caso di prova
Il primo passaggio nel processo di adozione di FL è eseguire un test su piccola scala su una singola macchina per determinare se i dati sono adatti per l’apprendimento federato. Questo test aiuterà anche a stabilire un business case iniziale dimostrando (o meno) che il modello creato dall’apprendimento federato è sufficientemente accurato per il tuo problema.
Per condurre il test, è necessario raccogliere un campione relativamente piccolo di dati che sia rappresentativo della distribuzione dei dati nei silos di dati, suddividerlo nello stesso modo e quindi addestrare un modello utilizzando un algoritmo di apprendimento federato su quel set di dati suddiviso. In sostanza, si simula l’apprendimento federato su lavoratori distribuiti su una singola macchina e si confrontano le prestazioni di un modello addestrato sull’intero set di dati con le prestazioni del modello appreso in modo federato. Il motivo per cui è possibile eseguire questo test localmente è perché gli algoritmi di apprendimento federati sono indipendenti dal fatto che i dati si trovano in posizioni diverse e presumono solo che i modelli di lavoro vengano addestrati su set di dati separati. Se i risultati del test sono soddisfacenti, puoi passare alla fase successiva.
- Ottieni il consenso dai proprietari dei dati
Il secondo passo nel percorso verso l’adozione dell’apprendimento federato è ottenere il consenso dei proprietari dei dati per quanto riguarda una distribuzione di produzione o una prova di concetto. Le preoccupazioni più comuni che i proprietari dei dati hanno è che il processo FL esporrà accidentalmente informazioni di identificazione personale o segreti aziendali riservati. È possibile affrontare queste preoccupazioni comprendendo il modello di minaccia che i proprietari dei dati hanno in mente. Ad esempio, se sono preoccupati che i modelli stessi rivelino informazioni o non si fidano dell’entità che controlla il server centrale, allora saranno utili approfondimenti tecnici sul tipo di informazioni conservate nei modelli. Se non sono ancora convinti,I ricercatori stanno valutando continuamente questi problemi, quindi dovresti consultare la letteratura pertinente quando rispondi a problemi specifici.
Un’altra importante preoccupazione che spesso i proprietari di dati hanno è che l’apprendimento federato potrebbe esporre i propri dati ai concorrenti. Ad esempio, immagina che la tua organizzazione sia un consorzio di produttori di additivi e desideri creare controller di processo basati su AI e sistemi di garanzia della qualità utilizzando dati di compilazione riservati dai membri del consorzio. In uno scenario del genere, i proprietari dei dati sono spesso preoccupati che se partecipano all’apprendimento federato, i loro dati potrebbero finire per aiutare i loro concorrenti a ottenere un vantaggio su di loro.
Questa è una preoccupazione legittima e puoi affrontarla in diversi modi a seconda del caso d’uso. Ad esempio, l’apprendimento federato può essere focalizzato su un problema che non si tradurrà in un vantaggio per nessuno dei partecipanti ma che aumenta la penetrazione complessiva del mercato del gruppo nel suo insieme. Considera l’esempio del produttore di additivi: l’obiettivo è imparare i controllori di processo ottimali per la produzione additiva(AM) attraverso l’apprendimento federato. L’AM è un sub-verticale relativamente nuovo e promettente, ma non è ancora ampiamente adottato. La complessità dei processi AM significa che l’apprendimento automatico è necessario per ottimizzare i vari passaggi all’interno della pipeline di produzione per consentire una più ampia adozione della tecnologia. L’utilizzo dell’apprendimento federato per condividere intuizioni da dati riservati e creare ottimizzatori migliori farebbe quindi appello a un ipotetico consorzio di produttori di additivi.
In generale, dissipare questa preoccupazione sul vantaggio competitivo richiede la comprensione del contesto più ampio dell’azienda e quindi lo sviluppo dell’approccio FL in tale luce.
- Costruisci il tuo sistema
Dopo aver completato i test iniziali, sviluppato il business case e convinto i proprietari dei dati a procedere, il passaggio finale consiste nel creare e distribuire effettivamente la soluzione di apprendimento federato. Descriverò questo passaggio ora, ma tieni presente che ciò che segue sarà più soggettivo di quello che abbiamo trattato finora, poiché sarà colorato dalla mia esperienza nella costruzione di una libreria di apprendimento federata nella mia organizzazione.
In generale, hai due opzioni quando decidi come creare e distribuire una soluzione di apprendimento federata: adottare una soluzione esistente o crearne una tua. A seconda delle tue esigenze e del livello di esperienza disponibile all’interno della tua organizzazione, quest’ultima opzione potrebbe essere di gran lunga più preferibile. Per capire il motivo, esaminerò brevemente lo stato attuale delle cose.
Sono disponibili molte librerie di apprendimento federato per le piattaforme di apprendimento automatico più diffuse; tuttavia, la maggior parte di essi è stata progettata per la ricerca e la sperimentazione piuttosto che per la distribuzione. Ciò significa che sono troppo immaturi o privi del set di funzionalità necessario per un’applicazione robusta del mondo reale.
Le due principali eccezioni, dal mio punto di vista, sono il framework Clara di Nvidia e il framework FATE open source di WeBank. Clara è in realtà un ampio SDK per l’apprendimento automatico che si rivolge a determinate parti del settore sanitario e offre una funzionalità di apprendimento federato incorporata. Se il tuo caso d’uso si adatta a questo verticale, Clara e la comunità che lo circonda saranno un ottimo punto di partenza. FATE è un altro framework abbastanza ampio e ricco di funzionalità, originariamente pensato per il settore finanziario, che implementa molti diversi tipi di algoritmi e altre tecnologie di conservazione della privacy. A seconda dello scenario che stai considerando, FATE potrebbe anche essere un’ottima opzione per te. Tuttavia, ti incoraggio a fare le tue ricerche per capire meglio cosa potrebbe essere adatto a te: nuovi framework vengono sviluppati continuamente.
Se il tuo problema particolare non si adatta alle applicazioni a cui mirano questi framework, dovrai impegnarti per comprenderlo e adattarlo al tuo caso d’uso e allo stack tecnologico. Quindi potrebbe essere preferibile creare la propria libreria / soluzione, che, a quanto pare, è fattibile per un piccolo gruppo di ingegneri esperti di software e apprendimento automatico.
Il motivo per cui è fattibile è perché una soluzione di apprendimento federato, ad alto livello, è composta da tre componenti, ognuno dei quali è a portata di mano di un tale team: l’algoritmo di apprendimento federato, l’infrastruttura di comunicazione e l’infrastruttura di sicurezza:
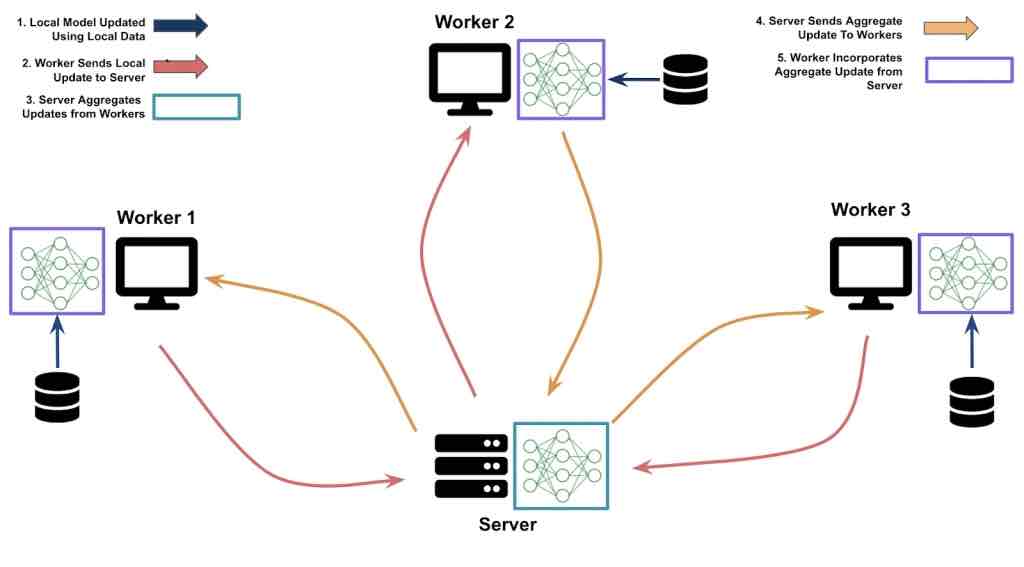
L’algoritmo di apprendimento federato specifica come i modelli dei lavoratori dovrebbero essere combinati in un modello globale sul server e come il modello globale dovrebbe poi essere integrato di nuovo dai lavoratori. Esistono alcuni algoritmi ben consolidati (come FedAvg), che generalmente funzionano senza richiedere modifiche significative, ei ricercatori stanno sviluppando nuovi algoritmi tutto il tempo. Come accennato in precedenza, questi algoritmi sono indipendenti dal substrato di comunicazione sottostante e qualsiasi ingegnere di machine learning dovrebbe essere in grado di implementarli senza troppi sforzi.
L’infrastruttura di comunicazione è necessaria per passare i modelli dal lavoratore al server e poi di nuovo in modo sicuro e affidabile. Se il numero di potenziali lavoratori / proprietari di dati è pari a un consorzio (in migliaia, come è il caso di molti degli esempi che ho citato nel primo articolo), l’infrastruttura di comunicazione può essere implementata utilizzando un server web e ingegneri software esperti dovrebbe essere in grado di implementarlo.
L’infrastruttura di sicurezza è il componente finale. I requisiti per questo variano a seconda delle applicazioni, ma una versione standard implica la garanzia che la comunicazione tra il server e il lavoratore sia sicura e che i lavoratori siano correttamente autenticati e gestiti. Questo, ancora una volta, può essere ottenuto con tecnologie standard come https (che protegge i siti Web) e firme digitali rispettivamente e dovrebbe essere semplice da implementare per ingegneri software esperti.
Una questione importante su cui ho sorvolato è il processo di creazione effettiva del modello di apprendimento automatico. Ciò richiede in genere molta analisi dei dati, esplorazione, impostazione di varie pipeline ed esplorazione di diversi tipi di architetture di modelli e approcci di formazione e così via. Tutte queste attività diventano più impegnative in un ambiente federato. Nella migliore delle ipotesi, è possibile raccogliere alcuni dati dai silos in una posizione centrale e quindi procedere come al solito per creare l’architettura del modello e la pipeline di dati. È quindi possibile addestrare il modello di produzione utilizzando l’apprendimento federato. Se ciò non è possibile, le possibili opzioni sono tecniche come l’analisi dei dati federati e la ricerca dell’architettura neurale federata. Nel complesso, lo sviluppo di modelli federati è un altro grande argomento che merita un articolo a sé stante.
Si spera che questa serie in due parti abbia stimolato la tua voglia di adottare l’apprendimento federato nella tua organizzazione e servirà da utile punto di partenza.
Hassan Mahmud