Una nuova tecnica chiamata “concept whitening” promette di fornire l’interpretabilità della rete neurale
Unisciti a noi per l’evento leader a livello mondiale sull’accelerazione della trasformazione aziendale con AI e dati, per i decisori tecnologici aziendali, presentato dall’editore numero 1 in AI e dati
Le reti neurali profonde possono compiere imprese meravigliose, grazie alla loro rete di parametri estremamente ampia e complicata. Ma la loro complessità è anche la loro maledizione: il funzionamento interno delle reti neurali è spesso un mistero, anche per i loro creatori. Questa è una sfida che preoccupa la comunità dell’intelligenza artificiale da quando l’apprendimento profondo ha iniziato a diventare popolare all’inizio degli anni 2010.
In parallelo con l’espansione dell’apprendimento profondo in vari domini e applicazioni, c’è stato un crescente interesse nello sviluppo di tecniche che tentano di spiegare le reti neurali esaminandone i risultati e i parametri appresi. Ma queste spiegazioni sono spesso errate e fuorvianti e forniscono poche indicazioni per correggere possibili idee sbagliate incorporate nei modelli di apprendimento profondo durante la formazione.
In un articolo pubblicato sulla rivista Nature Machine Intelligence , gli scienziati della Duke University propongono il “concetto di sbiancamento”, una tecnica che può aiutare a guidare le reti neurali verso l’apprendimento di concetti specifici senza sacrificare le prestazioni. Lo sbiancamento concettuale trasforma l’interpretabilità in modelli di apprendimento profondo invece di cercare risposte in milioni di parametri addestrati. La tecnica, che può essere applicata alle reti neurali convoluzionali , mostra risultati promettenti e può avere grandi implicazioni per il modo in cui percepiamo la ricerca futura sull’intelligenza artificiale.
Funzionalità e spazio latente nei modelli di deep learning
Dato un numero sufficiente di esempi di formazione di qualità, un modello di apprendimento profondo con la giusta architettura dovrebbe essere in grado di discriminare tra diversi tipi di input. Ad esempio, nel caso di attività di visione artificiale , una rete neurale addestrata sarà in grado di trasformare i valori dei pixel di un’immagine nella classe corrispondente. (Poiché lo sbiancamento dei concetti è pensato per il riconoscimento delle immagini, ci atterremo a questo sottoinsieme di attività di apprendimento automatico . Ma molti degli argomenti discussi qui si applicano all’apprendimento profondo in generale.)
Durante l’addestramento, ogni livello di un modello di apprendimento profondo codifica le caratteristiche delle immagini di addestramento in una serie di valori numerici e li memorizza nei suoi parametri. Questo è chiamato lo spazio latente del modello AI. In generale, gli strati inferiori di una rete neurale convoluzionale multistrato apprenderanno caratteristiche di base come angoli e bordi. Gli strati più alti della rete neurale impareranno a rilevare caratteristiche più complesse come volti, oggetti, scene complete, ecc.

Visualizzazione delle caratteristiche di una rete neurale
Sopra: ogni livello della rete neurale codifica caratteristiche specifiche dall’immagine di input.
Idealmente, lo spazio latente di una rete neurale rappresenterebbe concetti rilevanti per le classi di immagini che intende rilevare. Ma non lo sappiamo con certezza, ei modelli di deep learning sono inclini ad apprendere le caratteristiche più discriminanti, anche se sono quelle sbagliate.
Ad esempio, il seguente set di dati contiene immagini che mostrano gatti ma che hanno anche un logo nell’angolo in basso a destra. Un essere umano ignorerebbe facilmente il logo come irrilevante per il compito. Ma un modello di apprendimento profondo potrebbe ritenere che sia il modo più semplice ed efficiente per capire la differenza tra gatti e altri animali. Allo stesso modo, se tutte le immagini di pecore nel tuo set di addestramento contengono ampie aree di pascoli verdi, la tua rete neurale potrebbe imparare a rilevare i terreni agricoli verdi invece delle pecore.
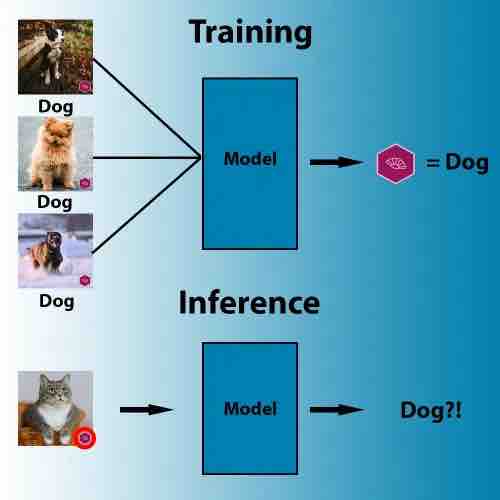
correlazioni errate di machine learning
Sopra: durante l’addestramento, gli algoritmi di apprendimento automatico cercano il pattern più accessibile che correla i pixel alle etichette.
Quindi, a parte le prestazioni di un modello di deep learning sui set di dati di addestramento e test, è importante sapere quali concetti e caratteristiche ha imparato a rilevare. È qui che entrano in gioco le tecniche di spiegazione classica.
Spiegazioni post hoc delle reti neurali
Molte tecniche di spiegazione del deep learning sono post hoc , il che significa che cercano di dare un senso a una rete neurale addestrata esaminandone l’output ei valori dei parametri. Ad esempio, una tecnica popolare per determinare cosa vede una rete neurale in un’immagine è mascherare parti diverse di un’immagine di input e osservare come questi cambiamenti influenzano l’output del modello di deep learning. Questa tecnica aiuta a creare mappe di calore che evidenziano le caratteristiche dell’immagine che sono più rilevanti per la rete neurale.
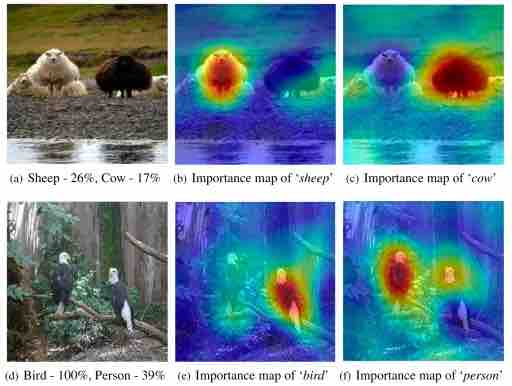
RISE spiegabile AI esempio mappa salienza
Sopra: esempi di mappe di salienza.
Altre tecniche post hoc implicano l’ attivazione e la disattivazione di diversi neuroni artificiali e l’esame di come questi cambiamenti influenzano l’output del modello AI. Questi metodi possono aiutare a trovare suggerimenti sulle relazioni tra le caratteristiche e lo spazio latente.
Sebbene questi metodi siano utili, trattano comunque i modelli di apprendimento profondo come scatole nere e non dipingono un quadro preciso del funzionamento delle reti neurali.
“I metodi di ‘spiegazione’ sono spesso statistiche riassuntive delle prestazioni (ad esempio, approssimazioni locali, tendenze generali sull’attivazione dei nodi) piuttosto che spiegazioni effettive dei calcoli del modello”, scrivono gli autori del documento sbiancante.
Ad esempio, il problema con le mappe di salienza è che spesso non mostrano le cose sbagliate che la rete neurale potrebbe aver imparato. E interpretare il ruolo dei singoli neuroni diventa molto difficile quando le caratteristiche di una rete neurale sono sparse nello spazio latente.

black box AI spiegazione mappa salienza per husky
Sopra: le spiegazioni della mappa di salienza non forniscono rappresentazioni accurate di come funzionano i modelli di intelligenza artificiale a scatola nera.
“Le reti neurali profonde (NN) sono molto potenti nel riconoscimento delle immagini, ma ciò che viene appreso negli strati nascosti delle NN è sconosciuto a causa della sua complessità. La mancanza di interpretabilità rende gli NN inaffidabili e difficili da risolvere “, Zhi Chen, Ph.D. studente in informatica alla Duke University e autore principale del concetto di carta sbiancante, ha detto a TechTalks. “Molti lavori precedenti tentano di spiegare post hoc ciò che è stato appreso dai modelli, ad esempio quale concetto viene appreso da ciascun neurone. Ma questi metodi si basano fortemente sul presupposto che questi concetti siano effettivamente appresi dalla rete (cosa che non sono) e concentrati su un neurone (di nuovo, questo non è vero nella pratica). “
Cynthia Rudin, professoressa di informatica alla Duke University e coautrice del documento sbiancante, aveva precedentemente messo in guardia sui pericoli del fidarsi delle tecniche di spiegazione della scatola nera e mostrato come tali metodi potessero fornire interpretazioni errate delle reti neurali. In un precedente articolo, pubblicato anche su Nature Machine Intelligence , Rudin aveva incoraggiato l’uso e lo sviluppo di modelli di intelligenza artificiale intrinsecamente interpretabili. Rudin, che è anche Ph.D. di Zhi. advisor, dirige il Prediction Analysis Lab della Duke University, che si concentra sull’apprendimento automatico interpretabile.
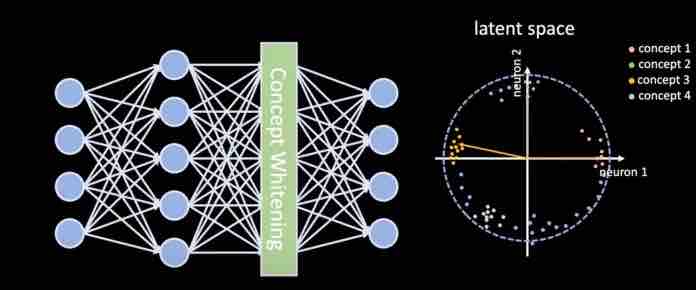
L’obiettivo dello sbiancamento dei concetti è sviluppare reti neurali il cui spazio latente sia allineato con i concetti rilevanti per il compito per cui è stato addestrato. Questo approccio renderà interpretabile il modello di apprendimento profondo e renderà molto più facile capire le relazioni tra le caratteristiche di un’immagine di input e l’output della rete neurale.
“Il nostro lavoro altera direttamente la rete neurale per districare lo spazio latente in modo che gli assi siano allineati con concetti noti”, ha detto Rudin a TechTalks.
Trasformare concetti in reti neurali
concetto di apprendimento
I modelli di deep learning vengono solitamente addestrati su un singolo set di dati di esempi annotati. Lo sbiancamento dei concetti introduce un secondo set di dati che contiene esempi dei concetti. Questi concetti sono correlati al compito principale del modello AI. Ad esempio, se il tuo modello di apprendimento profondo rileva le camere da letto, i concetti rilevanti includono letto, lampada, finestra, porta, ecc.
“I campioni rappresentativi possono essere scelti manualmente, in quanto potrebbero costituire la nostra definizione di interpretabilità”, afferma Chen. “I professionisti dell’apprendimento automatico possono raccogliere questi campioni con qualsiasi mezzo per creare i propri set di dati concettuali adatti alla loro applicazione. Ad esempio, si può chiedere ai medici di selezionare immagini radiografiche rappresentative per definire concetti medici “.
Con lo sbiancamento concettuale, il modello di apprendimento profondo passa attraverso due cicli di formazione paralleli. Mentre la rete neurale ottimizza i suoi parametri generali per rappresentare le classi nell’attività principale, lo sbiancamento concettuale regola neuroni specifici in ogni strato per allinearli con le classi incluse nel set di dati del concetto.
Il risultato è uno spazio latente districato, in cui i concetti sono nettamente separati in ogni strato e l’attivazione dei neuroni corrisponde ai rispettivi concetti. “Tale districamento può fornirci una comprensione molto più chiara di come la rete apprende gradualmente i concetti su più livelli”, afferma Chen.
Per valutare l’efficacia della tecnica, i ricercatori hanno eseguito una serie di immagini di convalida attraverso un modello di apprendimento profondo con moduli di sbiancamento concettuale inseriti a diversi livelli. Hanno quindi ordinato le immagini in base al concetto di neuroni che avevano attivato in ogni strato. Negli strati inferiori, il modulo di sbiancamento del concetto cattura caratteristiche di basso livello come colori e trame. Ad esempio, gli strati inferiori della rete possono apprendere che le immagini blu con oggetti bianchi sono strettamente associate al concetto di “aeroplano” e le immagini con colori caldi hanno maggiori probabilità di contenere il concetto di “letto”. Negli strati superiori, la rete impara a classificare gli oggetti che rappresentano il concetto.

concetto di sbiancamento a diversi strati
Sopra: il concetto di sbiancamento apprende informazioni di basso livello (es. Colori, trame) agli strati inferiori e informazioni di alto livello (es. Oggetti, persone) agli strati superiori.
Uno dei vantaggi del distacco dei concetti e degli allineamenti è che la rete neurale diventa meno incline a commettere errori evidenti. Mentre un’immagine scorre attraverso la rete, i neuroni del concetto negli strati superiori correggono gli errori che potrebbero essersi verificati negli strati inferiori. Ad esempio, nell’immagine sottostante, gli strati inferiori della rete neurale hanno erroneamente associato l’immagine al concetto di “aeroplano” a causa della densa presenza di pixel blu e bianchi. Ma mentre l’immagine si sposta attraverso gli strati superiori, i neuroni concettuali aiutano a orientare i risultati nella giusta direzione (visualizzati nel grafico a destra).
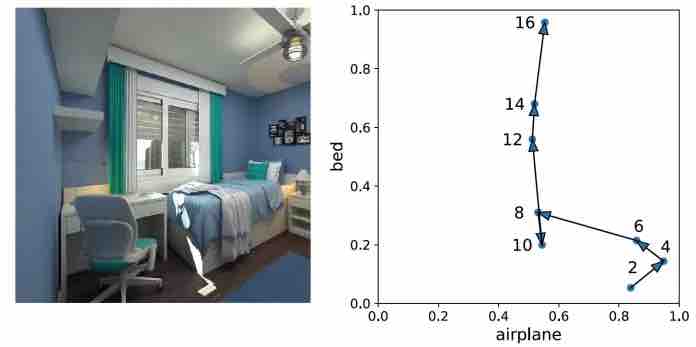
rappresentazione dello sbiancamento del concetto a diversi strati
Sopra: il concetto di sbiancamento corregge le idee sbagliate e gli errori quando un’immagine si sposta dagli strati inferiori a quelli superiori della rete neurale.
Precedenti sforzi nel campo hanno coinvolto la creazione di classificatori che cercavano di dedurre concetti dai valori nello spazio latente di una rete neurale. Ma, secondo Chen, senza uno spazio latente districato, i concetti appresi con questi metodi non sono puri perché i punteggi di previsione dei neuroni del concetto possono essere correlati. “Alcune persone hanno già provato a districare le reti neurali in modi supervisionati, ma non in un modo che effettivamente funzionasse per districare lo spazio. CW, d’altra parte, districa veramente questi concetti decorrelando gli assi usando una trasformazione sbiancante “, dice.
Applicazione dello sbiancamento concettuale alle applicazioni di deep learning
Lo sbiancamento del concetto è un modulo che può essere inserito in reti neurali convoluzionali invece del modulo di normalizzazione batch. Introdotta nel 2015, la normalizzazione batch è una tecnica diffusa che regola la distribuzione dei dati utilizzati per addestrare la rete neurale per accelerare l’addestramento ed evitare artefatti come l’overfitting. Le reti neurali convoluzionali più diffuse utilizzano la normalizzazione batch in vari livelli.
Oltre alle funzioni di normalizzazione batch, lo sbiancamento dei concetti allinea anche i dati lungo diversi assi che rappresentano concetti rilevanti.
Il vantaggio dell’architettura di concept whitening è che può essere facilmente integrata in molti modelli di deep learning esistenti. Durante la loro ricerca, gli scienziati hanno modificato diversi popolari modelli di apprendimento profondo pre-addestrati sostituendo i moduli di norme in lotti con lo sbiancamento concettuale e hanno ottenuto i risultati desiderati con una sola epoca di formazione. (Un’epoca è un ciclo di formazione sul set di formazione completo. I moduli di apprendimento profondo di solito subiscono molte epoche quando vengono addestrati da zero.)
“La CW potrebbe essere applicata a domini come l’imaging medico, in cui l’interpretabilità è molto importante”, afferma Rudin.
Nei loro esperimenti, i ricercatori hanno applicato il concetto di sbiancamento a un modello di apprendimento profondo per la diagnosi delle lesioni cutanee. “I punteggi di importanza dei concetti misurati sullo spazio latente CW possono fornire intuizioni pratiche su quali concetti sono potenzialmente più importanti nella diagnosi delle lesioni cutanee”, scrivono nel loro articolo.
“Per una direzione futura, invece di fare affidamento su concetti predefiniti, abbiamo in programma di scoprire i concetti dal set di dati, in particolare concetti utili non definiti che devono ancora essere scoperti”, afferma Chen. “Possiamo quindi rappresentare esplicitamente questi concetti scoperti nello spazio latente delle reti neurali, in modo districato, per una migliore interpretabilità”.
Un’altra direzione della ricerca è organizzare i concetti in gerarchie e districare gruppi di concetti piuttosto che concetti individuali.
Implicazioni per la ricerca sul deep learning
intelligenza artificiale che replica il cervello umano
Con i modelli di apprendimento profondo che diventano ogni anno più grandi e più complicati , ci sono diverse teorie su come affrontare il problema della trasparenza delle reti neurali.
Uno degli argomenti principali è osservare come si comportano i modelli di intelligenza artificiale invece di cercare di guardare all’interno della scatola nera. Questo è lo stesso modo in cui studiamo il cervello degli animali e degli esseri umani, conduciamo esperimenti e registriamo le attivazioni. Qualsiasi tentativo di imporre vincoli di progettazione di interpretabilità alle reti neurali si tradurrà in modelli inferiori, sostengono i sostenitori di questa teoria. Se il cervello si è evoluto attraverso miliardi di iterazioni senza un design top-down intelligente, anche le reti neurali dovrebbero raggiungere le loro massime prestazioni attraverso un puro percorso evolutivo.
Lo sbiancamento dei concetti confuta questa teoria e dimostra che possiamo imporre vincoli di progettazione top-down alle reti neurali senza causare alcuna penalizzazione delle prestazioni. È interessante notare che gli esperimenti mostrano che i moduli di sbiancamento dei concetti dei modelli di apprendimento profondo forniscono interpretabilità senza un calo significativo della precisione nell’attività principale.
“Il CW e molti altri lavori del nostro laboratorio (e molti altri laboratori) mostrano chiaramente la possibilità di costruire un modello interpretabile senza danneggiare le prestazioni”, afferma Rudin. “Ci auguriamo che il nostro lavoro possa spostare la convinzione delle persone che una scatola nera sia necessaria per una buona prestazione e possa attrarre più persone a costruire modelli interpretabili nei loro campi”.