Abilitazione dell’intelligenza artificiale su dispositivi locali con Edge ML
Edge Machine Learning riduce la dipendenza dalle reti cloud.
Con la crescita dell’Internet delle cose (IoT), le reti cloud sono state sovraccaricate e le aziende hanno ignorato i problemi critici del cloud computing come la sicurezza. La soluzione a tutti questi problemi era eseguire modelli di Machine Learning su dispositivi locali “Edge ML”.
Edge ML è una tecnologia che consente agli Smart Device di analizzare i dati in locale utilizzando algoritmi di machine e deep learning, diminuendo la dipendenza dalle reti Cloud. Questo articolo sarà incentrato sulla comprensione del funzionamento e della funzionalità di Edge Machine Learning. Di seguito gli argomenti da trattare.
Sommario
Cos’è l’IoT?
Cos’è Edge ML?
Come funziona?
Vantaggi e svantaggi
Applicazioni di Edge ML
Comprendiamo innanzitutto il concetto di IoT e il suo impatto su Edge ML.
Cos’è l’IoT?
L’Internet of Things (IoT) è una rete di elementi fisici che connette tutto a Internet utilizzando protocolli predefiniti e apparecchiature di rilevamento delle informazioni. Questa apparecchiatura condivide le informazioni e comunica per eseguire il riconoscimento, la localizzazione, il tracciamento, il monitoraggio e l’amministrazione intelligenti.
Internet non è più solo una rete di computer; si è evoluto in una rete di dispositivi di ogni forma e dimensione, inclusi veicoli, smartphone, elettrodomestici, giocattoli, macchine fotografiche, strumenti medici e sistemi industriali, animali, persone ed edifici, tutti connessi, tutti comunicanti e condivisi in base a informazioni predefinite protocolli per ottenere riorganizzazioni intelligenti, posizionamento, tracciamento, sicurezza e controllo e persino monitoraggio online personale in tempo reale, aggiornamento online e propulsione.
L’Internet of Things (IoT) è un concetto e un paradigma che considera la presenza pervasiva nell’ambiente di una varietà di oggetti che possono interagire tra loro e cooperare con altri oggetti tramite connessioni wireless e cablate e schemi di indirizzamento unici per creare nuovi servizi e raggiungere obiettivi comuni.
Cos’è Edge ML?
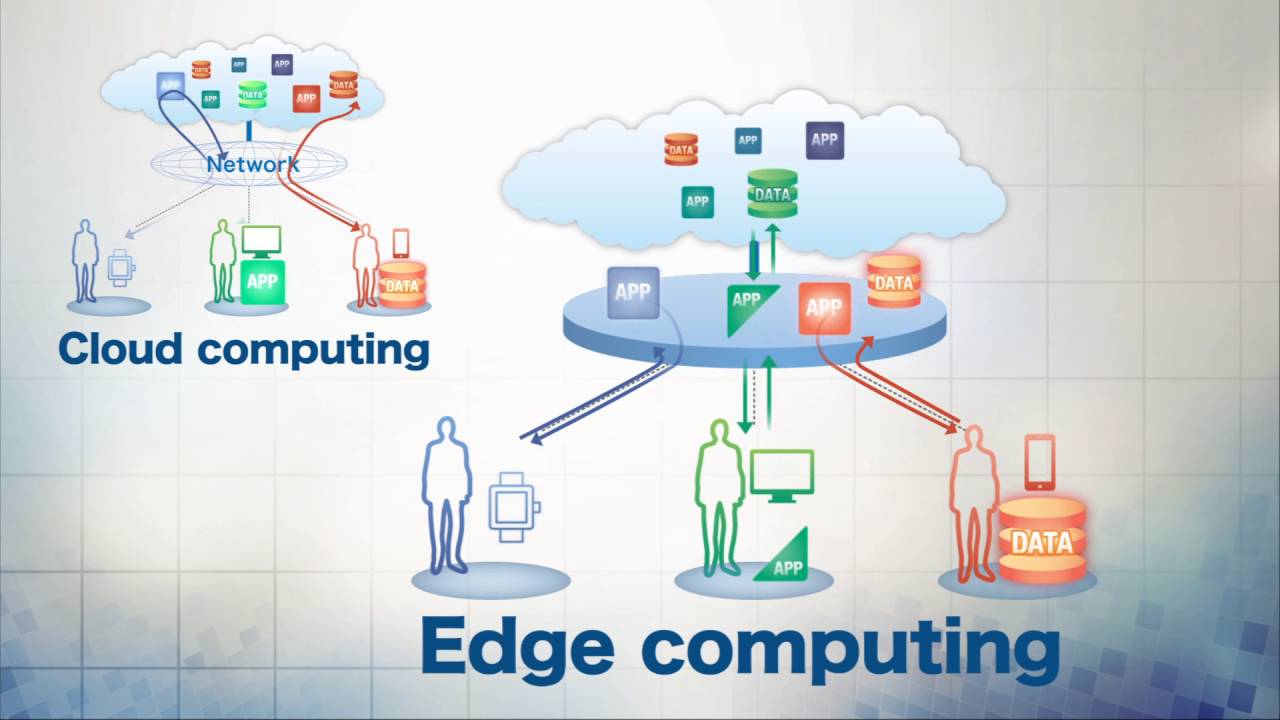
Edge Machine Learning appare come un’estensione del cloud computing per avvicinare i servizi cloud agli utenti finali. L’edge computing fornisce piattaforme di elaborazione virtuale che forniscono capacità di elaborazione, archiviazione e rete spesso posizionate ai margini della rete.
I server perimetrali sono dispositivi che forniscono servizi ai dispositivi finali e possono essere gateway IoT, router e mini data center in stazioni base di rete mobile, automobili e altri luoghi. I dispositivi perimetrali sono dispositivi finali che richiedono servizi da server perimetrali, come telefoni cellulari, dispositivi IoT e dispositivi incorporati.
La combinazione dell’edge computing con l’intelligenza artificiale presenta una possibile risposta ai principali problemi delle applicazioni basate sull’intelligenza artificiale. Questo nuovo modello di intelligenza è noto come edge intelligence. Edge intelligence si riferisce a una rete di sistemi e dispositivi collegati per la raccolta, la memorizzazione nella cache, l’elaborazione e l’analisi dei dati vicino a dove vengono raccolti i dati, con l’obiettivo di migliorare la qualità e la velocità dei dati proteggendo al contempo la privacy e la sicurezza dei dati.
A differenza dell’intelligence basata sul cloud tradizionale, che richiede ai dispositivi finali di caricare i dati creati o raccolti su un cloud remoto, l’edge intelligence elabora e analizza i dati in locale, proteggendo efficacemente la privacy degli utenti, riducendo i tempi di reazione e conservando le risorse di larghezza di banda.
Quando utilizzare l’edge computing
Da allora, è diventato più importante gestire, archiviare ed elaborare i dati in modo efficace. È particolarmente importante per le aziende sensibili al fattore tempo elaborare i dati in modo rapido ed efficace al fine di ridurre al minimo i rischi per la sicurezza e accelerare i processi aziendali. L’edge computing tenta di ottimizzare le applicazioni Web e i dispositivi Internet riducendo l’utilizzo della larghezza di banda e il ritardo di comunicazione.
Ad esempio, le installazioni di petrolio e gas si trovano spesso in aree lontane. L’edge computing consente l’analisi in tempo reale avvicinando l’elaborazione alla risorsa, riducendo la dipendenza dalla connettività di alta qualità a un cloud centralizzato.
Come funziona Edge ML?
L’obiettivo alla base di Edge ML è che il modello esista sui dispositivi ai margini della rete. Gli algoritmi ML vengono quindi eseguiti localmente sul dispositivo, eliminando la necessità di una connessione Internet per analizzare i dati e produrre risultati utilizzabili. L’intero processo potrebbe essere suddiviso in quattro componenti principali.
Edge Caching
L’edge caching è un sistema di dati distribuito che raccoglie e archivia i dati creati dai dispositivi perimetrali e dall’ambiente circostante, nonché i dati ricevuti da Internet, per supportare le applicazioni intelligenti per gli utenti perimetrali. Al limite, i dati sono diffusi.
I dispositivi perimetrali, come dispositivi di monitoraggio e sensori, raccolgono dati ambientali. Tali dati sono conservati in luoghi appropriati ed elaborati e analizzati da algoritmi intelligenti per fornire servizi agli utenti finali.
La memorizzazione nella cache si basa sulla ridondanza della richiesta. Nell’edge caching, i dati acquisiti vengono inseriti in applicazioni intelligenti e i risultati vengono ritrasmessi alla posizione in cui sono archiviati i dati. La ridondanza può essere classificata in tipi, ridondanza dei dati e ridondanza del calcolo.
La ridondanza dei dati si riferisce al fatto che gli input di un’applicazione intelligente possono essere identici o parzialmente identici. Considerando un’analisi continua della visione mobile, ci sono molti pixel comparabili tra fotogrammi consecutivi. Alcuni dispositivi perimetrali con risorse limitate potrebbero dover trasferire i video acquisiti ai server perimetrali per un’ulteriore elaborazione. I dispositivi Edge devono semplicemente caricare vari pixel o frame quando si utilizza la memorizzazione nella cache. I dispositivi perimetrali potrebbero riutilizzare i risultati del segmento ripetuto per ridurre al minimo l’elaborazione eccessiva.
La ridondanza del calcolo indica che le attività di calcolo richieste dalle applicazioni intelligenti possono essere le stesse. Un server perimetrale, ad esempio, fornisce servizi di riconoscimento delle immagini ai dispositivi perimetrali. Le attività di riconoscimento dello stesso ambiente possono essere le stesse, ad esempio le attività di riconoscimento di oggetti di vari utenti nella stessa posizione. I server perimetrali potrebbero comunicare immediatamente agli utenti i risultati del riconoscimento acquisiti in precedenza.
La cache può essere archiviata in tre posizioni: stazioni base macro e micro, nonché dispositivi edge. Esistono due tipi di materiale noti come file popolari e modelli intelligenti. Le stazioni base Macro sono in genere utilizzate come edge server nell’edge intelligence, fornendo servizi intelligenti con dati archiviati.
La cache viene consegnata, in due modi, uno viene consegnato da una singola stazione base e l’altro viene consegnato da più stazioni base in base alla cooperazione tra di loro. Inoltre, viene esplorato attentamente il contenuto ideale da memorizzare nella cache, ad esempio contenuto basato sulla ridondanza dei dati e contenuto basato sulla ridondanza del calcolo. Rispetto alle stazioni base macro e micro, i dispositivi edge hanno spesso meno risorse e una grande mobilità. A causa della capacità di archiviazione limitata di macro BS, micro BS e dispositivi periferici, è necessario affrontare la sostituzione del contenuto.
Rivista di analisi dell’India
Formazione di bordo
L’edge training è un processo di apprendimento distribuito che apprende i valori migliori per tutti i pesi e le distorsioni , nonché i modelli nascosti, utilizzando il training set memorizzato nell’edge. L’edge training, a differenza dei tradizionali metodi di addestramento centralizzato su potenti server o cluster di elaborazione, si svolge in genere su edge server o dispositivi perimetrali, che in genere non sono potenti quanto i server centralizzati o i cluster di elaborazione.
Il dispositivo viene addestrato in due modi: individualmente e in collaborazione. L’allenamento da solista viene eseguito su un singolo dispositivo senza l’aiuto di altri, mentre l’allenamento collaborativo coinvolge numerosi dispositivi che lavorano insieme per addestrare un algoritmo condiviso. Poiché la formazione individuale richiede più hardware, che a volte non è disponibile, la maggior parte del materiale esistente si concentra su progetti di formazione collaborativa.
L’edge training è sostanzialmente più lento dei paradigmi di training centralizzato, in cui CPU e GPU potenti potrebbero garantire un risultato decente con un periodo di training minimo. Alcuni ricercatori sono interessati ad accelerare l’edge training. Il lavoro sull’accelerazione della formazione è suddiviso in due gruppi, in base all’architettura della formazione: accelerazione per la formazione individuale e accelerazione per la formazione collaborativa.
L’allenamento in solitario è un sistema chiuso in cui i parametri o gli schemi ottimali sono ottenuti mediante il calcolo iterativo su singoli dispositivi. La formazione collaborativa, invece, si basa sulla collaborazione di più dispositivi, che necessitano di contatti periodici per l’aggiornamento. La frequenza degli aggiornamenti e il costo degli aggiornamenti sono due elementi che influenzano l’efficienza della comunicazione e il successo della formazione.
I ricercatori in questo campo si occupano principalmente di come mantenere le prestazioni del modello/algoritmo con una frequenza e una spesa di aggiornamento ridotte. Inoltre, la natura aperta della formazione collaborativa lo rende vulnerabile agli utenti malevoli. C’è anche della letteratura su problemi di privacy e sicurezza.
Rivista di analisi dell’India
Inferenza del bordo
L’inferenza perimetrale è la fase in cui un algoritmo appreso viene impiegato in un passaggio in avanti per calcolare l’output su dispositivi e server perimetrali. La maggior parte dei modelli di intelligenza artificiale attuali sono pensati per essere implementati su dispositivi con CPU e GPU potenti; tuttavia, ciò non è possibile con un’impostazione del bordo.
I modelli sono resi appropriati per l’ambiente perimetrale inventando nuovi algoritmi che hanno esigenze hardware ridotte e sono naturalmente adatti alle impostazioni perimetrali o comprimendo modelli esistenti per eliminare le operazioni superflue durante l’inferenza.
Nel caso della costruzione di un nuovo metodo, ci sono due approcci: consentire ai computer di costruire modelli ottimali, ad es. ricerca di architetture e architetture inventate dall’uomo utilizzando convoluzioni separabili in profondità e convoluzioni di gruppo.
I modelli attuali sono compressi per la compressione del modello per creare modelli più sottili e più piccoli che sono più computazionali ed efficienti dal punto di vista energetico con una perdita di precisione bassa o nulla. Le tecniche di compressione del modello includono l’approssimazione di basso rango, la distillazione della conoscenza, la progettazione di strati compatti, la potatura della rete e la quantizzazione dei parametri.
Rivista di analisi dell’India
Scarico del bordo
L’edge offloading è un paradigma di calcolo distribuito che fornisce funzioni di calcolo come memorizzazione nella cache, training e inferenza all’edge. Se un singolo dispositivo perimetrale non ha la capacità di supportare una determinata applicazione di intelligence perimetrale, le responsabilità dell’applicazione potrebbero essere scaricate su server perimetrali o altri dispositivi perimetrali. Il livello di edge offloading fornisce in modo trasparente servizi di elaborazione agli altri tre componenti di edge intelligence. La strategia di offload è fondamentale nell’edge offloading, poiché dovrebbe sfruttare al massimo le risorse disponibili nell’ambiente edge.
I server cloud, i server perimetrali e i dispositivi perimetrali ospitano le risorse del computer disponibili. L’offload da dispositivo a cloud (D2C), l’offload da dispositivo a server edge (D2E), l’offload da dispositivo a dispositivo (D2D) e l’offload ibrido sono le tecniche più utilizzate.
La tecnica di offload D2C sceglie di lasciare le operazioni di pre-elaborazione sui dispositivi edge e di scaricare il resto dei lavori su un server cloud, il che potrebbe ridurre drasticamente la quantità di dati caricati e la latenza.
L’approccio di offloading D2E utilizza una procedura simile, che può ridurre ulteriormente la latenza e la dipendenza dalla rete cellulare.
Concentrati sulle situazioni di casa intelligente nel metodo di scaricamento D2D, in cui gadget IoT, dispositivi indossabili e smartphone collaborano per condurre attività di formazione/inferenza.
Le soluzioni di scarico ibride offrono la massima adattabilità, sfruttando al meglio tutte le risorse disponibili.
Applicazioni di Edge ML
L’edge computing viene utilizzato in una varietà di settori. Raccoglie, elabora, filtra e analizza i dati a livello locale o ai margini della rete. Viene utilizzato nelle seguenti aree.
Assistenza sanitaria
L’edge computing può aiutare con l’accesso ai dati utilizzando l’apprendimento automatico e l’automazione. Aiuta nell’identificazione di dati problematici che richiedono una rapida attenzione da parte dei medici al fine di migliorare la cura del paziente ed eliminare gli eventi sanitari.
Le malattie croniche dei pazienti possono essere monitorate con monitor sanitari e altri gadget sanitari indossabili. Ha il potenziale per salvare vite informando istantaneamente gli operatori sanitari quando è necessaria assistenza. Inoltre, i robot chirurgici devono essere in grado di interpretare immediatamente i dati per aiutare in modo sicuro, tempestivo e preciso. Se questi gadget si basano sull’invio di dati al cloud prima di esprimere giudizi, le conseguenze potrebbero essere disastrose.
Costruzione
L’edge computing viene utilizzato principalmente nel settore edile per la sicurezza dei lavoratori, raccogliendo e analizzando dati da dispositivi di sicurezza, telecamere, sensori e così via. Fornisce alle organizzazioni una panoramica delle condizioni di sicurezza sul lavoro e garantisce che il personale rispetti le norme di sicurezza.
Pubblicità
Il marketing mirato e le informazioni per le attività di vendita al dettaglio dipendono da fattori essenziali specificati nelle apparecchiature sul campo, come le informazioni demografiche. L’edge computing può aiutare a proteggere la privacy degli utenti in questo scenario. Invece di trasmettere dati non protetti al cloud, può crittografare i dati e mantenere la fonte.
Produzione
Nel settore manifatturiero, l’edge computing viene utilizzato per monitorare i processi industriali e utilizzare l’apprendimento automatico e l’analisi in tempo reale per migliorare la qualità dei prodotti e rilevare gli errori di produzione. Incoraggia inoltre l’incorporazione di sensori ambientali nelle operazioni di produzione.
L’edge computing offre anche informazioni sui componenti in stock e sulla loro durata. Consente al produttore di effettuare scelte commerciali più accurate e tempestive in merito alle operazioni e alla struttura.
agricoltura
L’edge computing viene utilizzato nei sensori in agricoltura per misurare la densità dei nutrienti e il consumo di acqua e migliorare la raccolta. A tale scopo, il sensore acquisisce dati sulle variabili ambiente, temperatura e suolo. Esamina i loro impatti al fine di aumentare la produttività agricola e garantire che la raccolta avvenga nelle circostanze climatiche più favorevoli.
Gas e Petrolio
L’edge computing può essere utilizzato per monitorare la sicurezza nelle utility del gas e del petrolio. I sensori misurano continuamente l’umidità e la pressione. Per rispondere rapidamente, è necessaria una connettività di rete adeguata. Il problema è che la maggior parte di queste strutture si trova in luoghi lontani con collegamenti limitati.
Di conseguenza, posizionare l’edge computing su o vicino a tali sistemi offre una connessione maggiore e capacità di monitoraggio continuo. L’edge computing può anche rilevare i problemi delle apparecchiature in tempo reale. I sensori possono monitorare l’energia generata da tutte le apparecchiature, inclusi veicoli elettrici, sistemi eolici e altri, e utilizzare la gestione della rete per aiutare a ridurre i costi e creare energia efficiente.
Veicoli autonomi
Un passaggio pedonale davanti a un veicolo autonomo deve essere fermato immediatamente. Non è giusto affidarsi a un server lontano per esprimere questo giudizio. Inoltre, le auto che utilizzano la tecnologia edge possono interagire in modo più efficace poiché possono parlare prima tra loro, anziché inviare prima dati su incidenti, condizioni meteorologiche, traffico o deviazioni a un server remoto. L’edge computing può essere vantaggioso.
Sistemi audio intelligenti
I sistemi audio intelligenti possono imparare a comprendere i comandi vocali in locale per eseguire comandi semplici. Anche se l’accesso a Internet si interrompe, sarebbe possibile accendere e spegnere le luci o modificare le impostazioni del termostato.
Vantaggi e svantaggi
I seguenti sono i vantaggi dell’edge computing.
Tempi di risposta più rapidi
Come affermato in precedenza, l’implementazione di processi di elaborazione presso o vicino a dispositivi perimetrali aiuta a ridurre al minimo la latenza.
Prendi in considerazione lo spostamento di file all’interno dello stesso edificio. Lo scambio di file richiede più tempo poiché comunica con un server remoto situato in qualsiasi parte del globo e quindi ritorna come file ricevuto. Il router è responsabile del trasferimento dei dati in tutto il luogo di lavoro utilizzando l’Edge Computing, riducendo drasticamente la latenza. Consente inoltre di risparmiare una notevole quantità di larghezza di banda.
Efficacia dei costi
L’edge computing consente di risparmiare risorse del server e larghezza di banda, il che consente di risparmiare denaro. Il costo aumenta man mano che si implementano i servizi cloud per supportare un gran numero di dispositivi nelle aziende o nelle case con gadget intelligenti. L’edge computing, d’altra parte, ha il potenziale per ridurre questa spesa ricollocando la parte di elaborazione di tutti questi dispositivi sull’edge.
Protezione dei dati e privacy
Lo spostamento dei dati tra server all’estero solleva problemi di privacy, sicurezza e legali. Può porre seri problemi se viene dirottato e cade nelle mani sbagliate.
L’edge computing avvicina i dati alla fonte pur rimanendo entro i parametri delle regole dei dati. Consente di elaborare i dati sensibili in locale anziché spostarli nel cloud o in un data center. Di conseguenza, i tuoi dati rimangono al sicuro all’interno dei tuoi locali.
I seguenti sono gli svantaggi dell’edge computing.
Stoccaggio e costo
Anche se i costi dell’archiviazione nel cloud sono ridotti, c’è un costo aggiuntivo sull’estremità locale. Gran parte di ciò deriva dallo sviluppo della capacità di archiviazione per i dispositivi edge. L’edge computing ha anche una componente di costo poiché l’infrastruttura di rete IT esistente deve essere sostituita o migliorata per supportare dispositivi edge e storage. Alcune aziende potrebbero scoprire che il costo del passaggio a una rete perimetrale è paragonabile al costo della costruzione e della manutenzione di un’infrastruttura IT tradizionale.
Perdita di dati
Il vantaggio dell’edge computing comporta un pericolo. Per ridurre al minimo la perdita di dati, il sistema deve essere ben pianificato e programmato prima di essere implementato. Molti dispositivi di edge computing, come dovrebbero, scartano i dati inutili dopo la raccolta; tuttavia, se i dati rimossi sono significativi, i dati vengono persi e l’analisi nel cloud è imprecisa.
Rischio per la sicurezza
C’è un vantaggio per la sicurezza a livello di cloud e aziendale, ma c’è anche un pericolo per la sicurezza a livello locale. Non ha senso per un’azienda avere un fornitore basato su cloud con una sicurezza eccellente se la sua rete locale è vulnerabile.
Conclusioni
L’apprendimento automatico sui dispositivi riduce al minimo la congestione della rete consentendo di eseguire calcoli vicino alle origini dati mantenendo la privacy durante il caricamento dei dati. Con questo articolo abbiamo compreso il funzionamento e le applicazioni di Edge Machine Learning.
