I ricercatori decodificano le scansioni cerebrali per generare testo
il mese e scorso, Neuralink di Elon Musk ha dimostrato che è possibile monitorare l’attività cerebrale dai nostri telefoni. Ci sono state speculazioni intorno a Neuralink sul potenziale che ha per le generazioni future.
La decodifica dei segnali cerebrali ha grandi implicazioni in medicina. Una persona disabile può essere assistita, può capire cosa prova una persona senza parole e altro ancora. Quindi, possiamo sapere cosa sta pensando qualcuno? Se possiamo, l’output sarà in un formato di testo? Indagando su linee simili, i ricercatori dell’ETH di Zurigo, in Svizzera, hanno proposto un nuovo modello basato sui dati che classifica direttamente una scansione fMRI e la mappa alla parola corrispondente all’interno di un vocabolario fisso.
Inoltre, affrontano la decodifica del cervello su soggetti invisibili. Questo nuovo modello, hanno scritto i ricercatori, sfrutta l’apprendimento profondo per decodificare le attività cerebrali sotto forma di scansioni fMRI in testo.
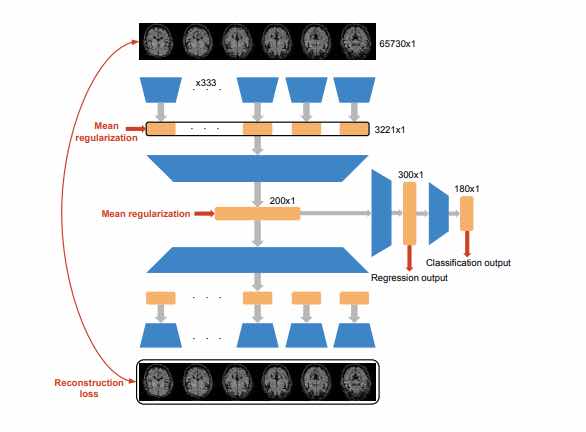
In questo lavoro, i ricercatori cercano di mappare le attività cerebrali sotto forma di scansioni fMRI sul testo presentato ai soggetti durante la scansione. Hanno considerato due tipi di decodificatori: decodificatori classici basati sulla regressione e decodificatori basati sulla classificazione, che imparano a mappare le attività cerebrali su una parola all’interno di un vocabolario limitato. Sopra è mostrata l’architettura del decodificatore migliorato applicato.
Ma la raccolta della fMRI non è un processo semplice. Esistono incongruenze tra le sessioni di scansione e può essere costoso e lento. Gli autori lamentano che occorrono circa 4 ore solo per ottenere le 180 scansioni cerebrali, che devono ancora essere elaborate. La maggior parte dei lavori precedenti sulla decodifica del cervello ha considerato lo scenario in cui il modello viene addestrato con i dati dello stesso soggetto che viene valutato. Gli autori sostengono che questo scenario non è adatto per applicazioni nella vita reale e che di fatto limita la nostra capacità di decodificare le attività cerebrali.
Nel decodificatore basato sulla classificazione, lo strato di regressione di dimensione 300 × 1 viene trasformato in uno strato non lineare e sopra di esso viene aggiunto un ulteriore strato softmax.
Il funzionamento del modello si presenta così:
Scansione fMRI monodimensionale di dimensione 65, 730 × 1 voxel e genera un vettore latente di dimensione 200 × 1.
Il vettore latente viene utilizzato per produrre la regressione o l’obiettivo di classificazione.
Il modello è costituito da due layer non lineari completamente connessi che producono mappe delle caratteristiche. Ogni strato non lineare ha 0,4 dropout, normalizzazione batch e attivazione Leaky ReLU (α = 0,3). Questo semplice modello è considerato un modello base.
Il modello viene quindi trasformato in un autoencoder (decoder-encoder) aggiungendo un encoder che rispecchia il modello base, cioè il decoder.
Questo codificatore ricostruisce le attività cerebrali di input (fMRI) dal vettore latente e un termine di ricostruzione viene aggiunto alla funzione di perdita.
Il decodificatore di classificazione fMRI viene quindi utilizzato per trasformare una scansione del cervello in un vettore di probabilità su un vocabolario di 180 parole. Le prime 5 previsioni vengono selezionate e utilizzate come incorporamenti e punti di ancoraggio per il modello di generazione del linguaggio.
Il modello GPT-2 genera quindi il testo.
Secondo gli autori, gli esperimenti hanno dimostrato che l’output della decodifica fMRI potrebbe guidare la generazione del linguaggio con grande scioltezza. Detto questo, gli autori ammettono anche che è necessario migliorare la decodifica da fMRI a parole.
Ad esempio, per tenere conto del ritardo nelle scansioni fMRI dovuto al flusso sanguigno, sarebbe desiderabile avere una misura di certezza per la parola decodificata che innesca la generazione del linguaggio quando il decodificatore è certo e la interrompe altrimenti. Inoltre, sarebbe necessario registrare espressioni come “positivo”, “negativo”, “felicità”, “natura”, ecc.
Takeaway chiave
I contributi di questo lavoro dei ricercatori dell’ETH di Zurigo possono essere riassunti come segue:
Introdotto un modello per decodificare le scansioni fMRI in parole che supera di gran lunga i modelli esistenti.
Il modello si generalizza con successo a soggetti invisibili.
Introdotta una strategia per condizionare la generazione del linguaggio verso il contenuto semantico delle scansioni fMRI
Può portare a un vero e proprio sistema per tradurre le attività cerebrali in un testo coerente.