Verso un’intelligenza artificiale più trasparente
Una pietra miliare per far funzionare l’IA è l’apprendimento automatico: la capacità delle macchine di imparare dall’esperienza e dei dati e migliorare nel tempo man mano che apprendono. In effetti, è stata l’esplosione nella ricerca e nell’applicazione dell’apprendimento automatico che ha reso l’IA il letto caldo di recente interesse, investimento e applicazione che è oggi. Fondamentalmente, l’apprendimento automatico consiste nel dare alle macchine un sacco di dati da cui imparare, e usare sofisticati algoritmi che possono generalizzare da quell’apprendimento per dati che la macchina non ha mai visto prima. In questo modo, l’algoritmo di apprendimento automatico è la ricetta che insegna alla macchina come apprendere e il modello di apprendimento automatico è il risultato di tale apprendimento che può quindi generalizzare a nuovi dati.
Indipendentemente dall’algoritmo utilizzato per creare il modello di apprendimento automatico, esiste una verità fondamentale: il modello di apprendimento automatico è valido solo come i suoi dati. Dati errati danno come risultato modelli cattivi In molti casi, questi cattivi modelli sono facili da individuare poiché funzionano male. Ad esempio, se hai creato un modello di apprendimento automatico per identificare i gatti nelle immagini e il modello identifica le farfalle come gatti o non riesce a individuare ovvi gatti nelle immagini, sappiamo che c’è qualcosa di sbagliato nel modello.
Ci sono molte ragioni per cui un modello potrebbe funzionare male. I dati di input potrebbero essere crivellati di errori o scarsamente ripuliti. Le varie impostazioni e configurazioni per il modello, gli iperparametri, potrebbero essere impostate in modo errato ottenendo risultati scadenti. O forse i data scientist e gli ingegneri ML che hanno addestrato il modello hanno selezionato un sottoinsieme di dati disponibili che presentavano una sorta di pregiudizio intrinseco in esso, risultando in risultati distorti del modello. Forse il modello non era abbastanza allenato o aveva problemi di sovra-adattamento o di insufficienza con risultati scarsi. In effetti, ci sono molti modi in cui un modello risultante potrebbe essere al di sotto dello standard.
Ora, se invece di un modello di classificazione dei gatti, avessimo creato un modello di riconoscimento facciale e lo avessimo usato per motivi di sicurezza. Se il modello identifica erroneamente le persone, è colpa di una configurazione errata del modello, di un modello scarsamente addestrato, di dati di input errati o forse solo del fatto che abbiamo selezionato un set parziale per addestrare il modello in primo luogo? Se dovremmo dipendere da questo modello, come possiamo fidarci di quel modello sapendo che ci sono così tanti modi in cui il modello fallisce?
In un tipico progetto di sviluppo di applicazioni, abbiamo garanzia di qualità (QA) e processi di prova, strumenti e tecnologie in grado di individuare rapidamente eventuali bug o deviazioni dalle norme di programmazione stabilite. Possiamo eseguire le nostre applicazioni attraverso test di regressione per assicurarci che nuove patch e correzioni non causino più problemi e abbiamo modi per testare continuamente le nostre capacità mentre le integriamo continuamente con combinazioni sempre più complesse di sistemi e funzionalità dell’applicazione.
Ma qui è dove incontriamo alcune difficoltà con i modelli di apprendimento automatico. Non sono codici di per sé in quanto non possiamo semplicemente esaminare il codice per vedere dove si trovano i bug. Se sapessimo come avrebbe dovuto funzionare l’apprendimento, beh, allora non avremmo bisogno di addestrarlo con i dati, vero? Dovremmo semplicemente codificare il modello da zero e finirlo. Tuttavia, non è così che funzionano i modelli di apprendimento automatico. Deriviamo la funzionalità del modello dai dati e attraverso l’uso di algoritmi che tentano di costruire il modello più accurato dai dati forniti, dobbiamo generalizzare a dati che il sistema non ha mai visto prima. Ci stiamo approssimando e quando ci avviciniamo non possiamo mai essere esatti. Quindi, non possiamo semplicemente risolvere il problema con il modello giusto. Possiamo solo iterare. Scorrere con dati migliori. Migliore iperparametro di configurazione. Algoritmi migliori. Più potenza. Questi sono gli strumenti che abbiamo.
Se sei il costruttore del modello, allora hai quegli strumenti a tua disposizione per migliorare i tuoi modelli. Ma cosa succede se sei l’utente o il consumatore di quel modello? Cosa succede se il modello che si sta utilizzando funziona male? Non hai lo stesso controllo sulla ricostruzione di quel modello. Tuttavia, ancora più significativamente, non sai perché quel modello ha prestazioni scarse. È stato addestrato con dati errati? I data scientist hanno scelto un set di dati selettivo o distorto che non corrisponde alla tua realtà? Sono state scelte le impostazioni dell’iperparametro sbagliate che potrebbero funzionare bene per gli sviluppatori ma non per te?
Il problema è che non conosci le risposte a nessuna di queste domande. Non c’è trasparenza. Come consumatore modello, hai solo il modello. Usalo o perdilo. La tua scelta è di accettare il modello così com’è o andare avanti e costruirne uno tuo. Poiché il mercato si sposta dai modellisti ai modellisti, questa è sempre una risposta inaccettabile. Il mercato ha bisogno di maggiore visibilità e maggiore trasparenza per poter fidarsi dei modelli che altri stanno costruendo. Dovresti fidarti di quel modello che il provider cloud sta fornendo? Che dire del modello incorporato nello strumento da cui dipendi? Quale visibilità hai su come è stato messo insieme il modello e come verrà iterato? La risposta in questo momento è poca o nessuna.
Problema n. 1: algoritmi inspiegabili
Un problema che è stato ben riconosciuto è che alcuni algoritmi di apprendimento automatico sono inspiegabili. Vale a dire, quando è stata presa una decisione o il modello è giunto a una conclusione come una classificazione o una regressione, c’è poca visibilità sulla comprensione di come il modello è giunto a tale conclusione. Le reti neurali di apprendimento profondo, l’attuale celebre dell’apprendimento automatico in questi giorni soffre particolarmente di questo problema. Ad esempio, quando un modello di riconoscimento delle immagini riconosce una tartaruga come un fucile, qual è il motivo per cui il modello lo fa? In realtà non sappiamo perché, e quindi coloro che cercano di sfruttare i punti deboli del modello possono sfruttare tali vulnerabilità lanciando queste reti di apprendimento profondo per un ciclo. Mentre ci sono numerosi sforzi in corso per aggiungere elementi di spiegabilità agli algoritmi di apprendimento profondo, non siamo ancora nel punto in cui tali approcci stanno vedendo un’adozione diffusa.
Non tutti gli algoritmi di machine learning soffrono degli stessi problemi di spiegabilità. Gli alberi decisionali per loro natura sono spiegabili, sebbene se usati in metodi di insieme come le foreste casuali, perdiamo elementi di tale spiegabilità. Quindi, la prima domanda che ogni consumatore di modello dovrebbe porre è quanto sia spiegabile l’algoritmo che è stato usato per costruire il modello? Se sappiamo fino a che punto un utente del modello può ottenere spiegabilità per una determinata decisione del modello, possiamo avere un aspetto della visibilità delle prestazioni del modello.
Problema n. 2: mancanza di visibilità nei set di dati di allenamento
Tuttavia, semplicemente sapere se un determinato modello utilizza un algoritmo spiegabile non è sufficiente per comprendere le prestazioni di un modello. Come accennato in precedenza, la forza di un modello dipende in modo significativo dai suoi dati di allenamento. Dati buoni, puliti, ben etichettati (nel caso di approcci di apprendimento supervisionato) daranno luogo a modelli buoni e ben funzionanti. Giusto? Beh, non sempre. Se i dati di allenamento non rappresentano i tuoi dati del mondo reale, anche questi modelli altamente qualificati, puliti e ben etichettati funzioneranno male.
Pertanto, la domanda successiva che un utente modello dovrà porre riguarda i dati di formazione. Da dove provengono quei dati? Come è stato pulito? Quali sono le caratteristiche o le dimensioni su cui è stato formato il modello? Posso vedere o accedere ai dati di allenamento? Posso ottenere visibilità su come i dati sono stati ripuliti e quali funzionalità sono state utilizzate? Se la risposta è no a queste domande, hai una visibilità molto limitata e confidi che il modello abbia in mente le tue migliori intenzioni.
Problema n. 3: mancanza di visibilità sui metodi di selezione dei dati
Supponiamo che tu abbia accesso al set completo di dati di allenamento utilizzati. Ciò rappresenterebbe il massimo in termini di trasparenza per il modello giusto? Non proprio. Solo perché hai accesso a gigabyte o petabyte di dati utilizzati per addestrare il modello non significa che sai quali aspetti di quei dati sono stati effettivamente utilizzati per addestrare il modello. Che cosa succede se gli ingegneri ML scelgono di utilizzare solo un sottoinsieme di tali dati o dimensioni, colonne o caratteristiche specifiche di quel set di dati? Cosa accadrebbe se i data scientist usassero approcci di aumento dei dati per migliorare i dati di training con dati aggiuntivi non inclusi nel set di dati di training? Il semplice accesso ai dati di formazione non risponde a tutte le domande sulla trasparenza.
La piena trasparenza significa anche sapere come i dati sono stati selezionati dai dati di formazione disponibili e idealmente anche essere in grado di utilizzare gli stessi metodi di selezione sui dati di formazione come un consumatore modello per vedere quali dati sono stati inclusi e quali dati sono stati esclusi. Potresti capire che il tuo uso del modello sta fallendo perché i dati che stai utilizzando nella vita reale sono semplicemente i dati che sono stati esclusi dai dati utilizzati per la formazione. Senza avere piena visibilità sui metodi di selezione dei dati, esiste ancora una mancanza di trasparenza.
Problema n. 4: comprensione limitata della distorsione nei set di dati di addestramento
Molte volte, i modelli incontrano problemi non a causa di dati errati o persino dati scarsamente selezionati, ma a causa di una predisposizione intrinseca nei dati di addestramento. La parola “bias” è in qualche modo sovraccaricata nel senso dell’apprendimento automatico poiché la usiamo in tre modi diversi: nel senso dei pesi e dei “bias” posti in una rete neurale, nel senso separato del compromesso “bias” quell’equilibrio si sovrappone o si sottrae, e nel senso più ampiamente compreso di “pregiudizio” informativo che viene imposto dagli umani a prendere decisioni basate sulle proprie nozioni preconcette. È l’ultimo senso di cui siamo più preoccupati qui.
Ci sono stati molti problemi relativi ai modelli di riconoscimento facciale formati su set di dati limitati a causa della propensione degli sviluppatori di modelli e problemi di modelli di decisione sui prestiti che hanno utilizzato set di dati storicamente distorti per determinare la disponibilità di credito. Le distorsioni della società nei set di dati sono significative e diffuse e le organizzazioni devono trovare il modo di eliminare tali distorsioni se provocano modelli che perpetuano le distorsioni in modi indesiderati. Questo è un concetto reso popolare da Cathy O’Neil nel suo libro Weapons of Math Destruction .
Tuttavia, questo è solo il pregiudizio più visibile. Esistono altri pregiudizi che potrebbero contaminare l’utilità di un determinato modello. Forse un negozio di e-commerce online sta usando un modello per classificare e taggare automaticamente gli abiti per un negozio di moda online. Se il modello fosse stato addestrato utilizzando dati occidentali, gli abiti da sposa verrebbero classificati principalmente identificando tonalità bianche o simili come avorio, bianco sporco o crema come abiti da sposa. Questo modello tuttavia fallirebbe nei paesi non occidentali dove abiti colorati, sari, kimono e altre forme di abiti da sposa sono le norme accettate.
In altri casi, le industrie assicurative potrebbero utilizzare modelli per identificare e classificare i veicoli. Tuttavia, se questi modelli fossero addestrati su foto diurne ben illuminate di nuovi veicoli appena usciti dalla fabbrica, il modello fallirebbe terribilmente su foto di versioni più vecchie e malconce degli stessi veicoli scattate di notte o in condizioni di scarsa illuminazione. La realtà è che l’utente del modello non conosce il bias esistente del set di dati. Sarebbe utile sapere che i pregiudizi intrinseci del modello potrebbero essere. Forse lo sviluppatore del modello non conosce nemmeno i pregiudizi, ma gli utenti del modello lo scopriranno sicuramente.
Problema n. 5: visibilità limitata nel controllo delle versioni del modello
Un altro problema con la trasparenza dei modelli è che i modelli potrebbero essere continuamente aggiornati. In effetti, i buoni modelli dovrebbero essere ripetuti in modo da poter essere ancora migliori. Questo fa parte di metodologie consolidate . Tuttavia, se sei un utente modello e il modello che stai utilizzando inizia a funzionare male quando si stava comportando bene prima, potresti chiederti perché è così. Il primo istinto per gli utenti del modello che vedono improvvisi problemi di prestazioni del modello è quello di esaminare i dati immessi nel modello per vedere se qualcosa è cambiato. Ma cosa penseresti se i dati fossero gli stessi ma il modello non funzionasse bene? Chiaramente qualcosa è cambiato nel modello. Questa è la sfida di non avere visibilità nel versioning del modello.
Se si utilizza un modello basato su cloud, il versioning del modello apparentemente casuale e spontaneo potrebbe causare problemi. Per la piena trasparenza, i produttori che producono modelli dovrebbero anche rendere chiaro e coerente il modo in cui verranno modellati i modelli, la frequenza di versioning del modello e la possibilità di utilizzare versioni di modelli precedenti se i nuovi modelli iniziano a funzionare male. Mentre i buoni fornitori di modelli forniranno una visibilità completa sul controllo delle versioni dei modelli, ciò non viene fatto in modo coerente o garantito, soprattutto se confrontato tra diversi fornitori di modelli.
Altre questioni relative alla fiducia e alla trasparenza del modello
Vi sono molti altri problemi da considerare riguardo alla trasparenza dei modelli che possono indurre gli utenti dei modelli a pensarci due volte prima a seconda di un modello per applicazioni altamente critiche. Sai perché il modello è stato creato e cosa gli sviluppatori del modello avevano in mente per il suo caso d’uso? Stai usando il modello nel modo previsto dai modellisti? Sono state effettuate analisi sul potenziale impatto che il modello potrebbe avere per diversi utenti? Qual è l’origine dei dati di allenamento? Quali sono le varie metriche delle prestazioni per diversi tipi di dati di input? Come funziona questo modello in produzione su varie misure? Potete applicare l’apprendimento del trasferimento al modello e, in tal caso, come? Come sono cambiate le metriche delle prestazioni del modello nel tempo? Chi altro sta usando il modello? Queste sono tutte domande valide e importanti a cui rispondere,
Un metodo di valutazione della trasparenza proposto
I tentativi di trasparenza del modello non sono nuovi. Google ha recentemente annunciato il proprio approccio alle schede modello Google Cloud che affronta alcune delle considerazioni sulla trasparenza del modello, in particolare per quanto riguarda le prestazioni e l’applicabilità a set di dati specifici. Tuttavia, non affronta molti degli aspetti sopra elencati e per buoni motivi. Il loro approccio si concentra principalmente sull’aiutare il modellista a costruire modelli migliori, ma non necessariamente sui consumatori di modelli di terze parti. Mentre le carte modello hanno un aspetto di “equità” affrontato nell’approccio, molte delle misure sopra non sono ancora state inserite nelle specifiche delle carte modello.
Nel maggio 2019, il National Institute of Standards and Technology (NIST), un’agenzia del governo federale degli Stati Uniti, ha convocato una riunione per il progresso degli standard di intelligenza artificiale secondo i piani strategici di AI della Casa Bianca. Nel corso di tale riunione è stata proposta l’idea di un metodo per valutare la trasparenza dei modelli attraverso più misure. Tuttavia, NIST non ha intrapreso alcuna azione a seguito di ciò. Di conseguenza, gli analisti di Cognilytica hanno sviluppato una valutazione della trasparenza a più fattori che ha contribuito all’organizzazione no profit ATARC, che successivamente l’ha raccolta per l’azione in uno dei loro gruppi di lavoro di Intelligenza Artificiale. (Divulgazione: sono un analista principale di Cognilytica e un presidente del gruppo di lavoro di ATARC).
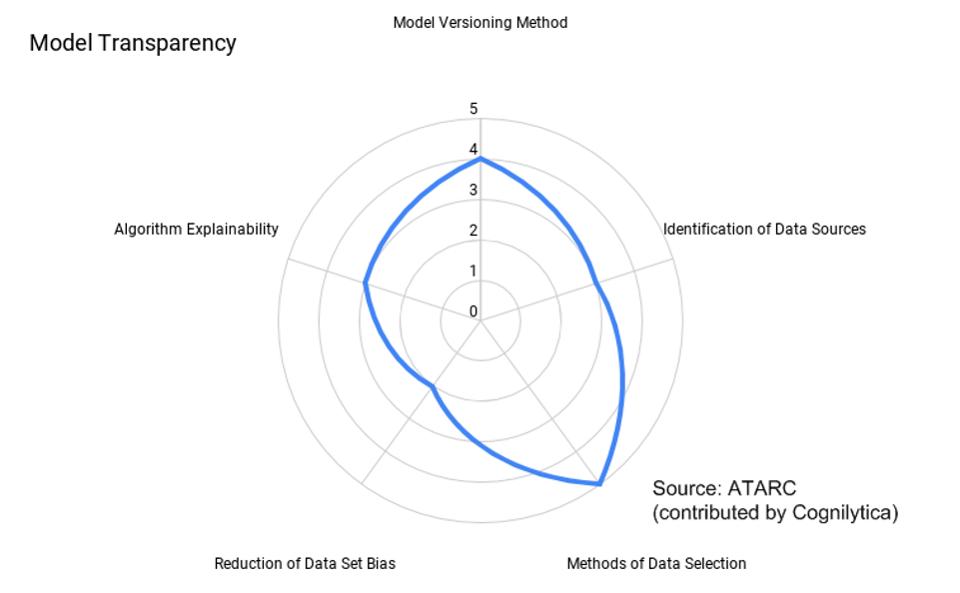
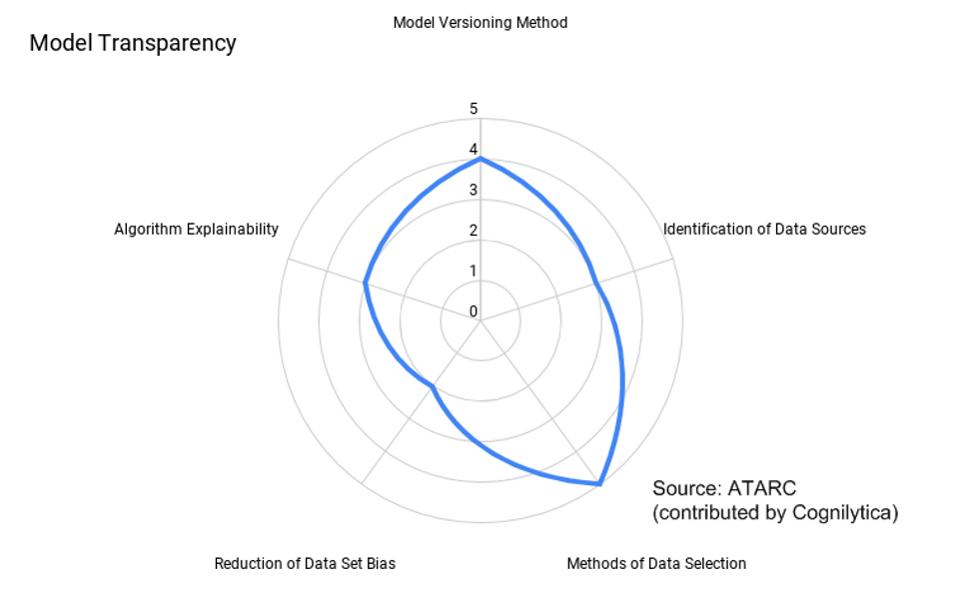
Il gruppo di lavoro ATARC AI Ethics and Responsible AI ha ripetuto la proposta e prodotto un documento che mira agli sviluppatori di modelli a valutare i loro modelli su cinque fattori per la trasparenza. Ciascuno dei fattori è associato a una delle aree problematiche sopra menzionate e assegna un valore in punti per la trasparenza lungo quella misura. Ad esempio, un modello potrebbe ottenere un “1” per la spiegabilità algoritmica (che significa una scatola nera totale) mentre un punteggio di “5” per la trasparenza dei dati di allenamento (viene fornito l’accesso completo al set di dati di allenamento). Il risultato finale è una “carta radar” che mostra la trasparenza per un determinato modello, come illustrato di seguito:
Modello di diagramma di valutazione della trasparenza
Modello di diagramma di valutazione della trasparenza ATARC / COGNILYTICA
Attualmente il gruppo di lavoro ATARC sta cercando di contribuire con il modello come standard all’International Organization for Standardization (ISO) , e sta anche incoraggiando gli altri a contribuire e fornire feedback. Indipendentemente dal fatto che questo particolare approccio alla trasparenza sia ampiamente adottato, si spera che i modellisti grandi e piccoli siano incoraggiati a includere una valutazione della trasparenza del modello come parte del loro rilascio del modello.
È importante notare che queste valutazioni dei modelli sono autovalutate, il che significa che coloro che costruiscono modelli produrranno la valutazione per i modelli che costruiscono. Sebbene sia possibile per gli sviluppatori di modelli dichiarare in modo inesatto i loro livelli di trasparenza, è molto facile per gli utenti dei modelli verificare e convalidare le proprie autovalutazioni. Dopotutto, non puoi dichiarare che i dati di addestramento del modello sono disponibili per chiunque possa accedervi se non è il caso.
Una valutazione della trasparenza è estremamente necessaria per l’industria. Per fidarsi dell’intelligenza artificiale, le organizzazioni hanno bisogno di modelli affidabili. È molto difficile fidarsi di qualsiasi modello o fonte di terze parti senza avere trasparenza sul funzionamento di tali modelli. Sebbene non vi siano dubbi sul fatto che molte organizzazioni e organismi di normalizzazione stanno lavorando su simili sforzi per migliorare la trasparenza dei modelli, è evidente che nel settore deve esserci un certo consenso sui metodi di trasparenza per vedere i guadagni a lungo termine che spera di ottenere con l’IA.