rilevamento anomalie tramite LSTM
Il rilevamento dell’anomalia è stato utilizzato in varie applicazioni di data mining per trovare le attività anomale presenti nei dati disponibili. Con l’avanzamento delle tecniche di apprendimento automatico e gli sviluppi nel campo dell’apprendimento profondo, al giorno d’oggi la richiesta di anomalie è molto richiesta. Ciò è dovuto all’implementazione di algoritmi di machine learning con set di dati pesanti e alla generazione di risultati più accurati. Il rilevamento delle anomalie non si limita ora al rilevamento delle attività fraudolente dei clienti, ma viene anche applicato in applicazioni industriali in pieno svolgimento.
Nelle industrie manifatturiere, dove vengono utilizzati macchinari pesanti, viene applicata la tecnica di rilevamento delle anomalie per prevedere le attività anomale delle macchine in base ai dati letti dai sensori. Ad esempio, in base ai dati di temperatura letti attraverso i sensori, è possibile prevedere il possibile guasto del sistema. In questo articolo, discuteremo come rilevare anomalie presenti nei dati di temperatura disponibili nel formato serie temporale. Questi dati vengono acquisiti dai sensori di un componente interno di una grande macchina industriale.
Cos’è Anomaly?
Nell’apprendimento automatico e nel data mining, il rilevamento delle anomalie ha il compito di identificare elementi, eventi o osservazioni rari sospetti e che sembrano diversi dalla maggior parte dei dati. Queste anomalie possono indicare alcuni tipi di problemi come frodi bancarie, problemi medici, guasti di apparecchiature industriali ecc. Il rilevamento delle anomalie ha due categorie principali, il rilevamento delle anomalie senza supervisione in cui vengono rilevate anomalie in un dato senza etichetta e il rilevamento delle anomalie sorvegliato in cui sono presenti anomalie rilevato nei dati etichettati. Esistono varie tecniche utilizzate per il rilevamento di anomalie come tecniche basate sulla densità, tra cui K-NN, macchine vettoriali di supporto di una classe, Autoencoder, modelli di Markov nascosti ecc.
Il set di dati
In questo esperimento, abbiamo utilizzato il set di dati Numenta Anomaly Benchmark (NAB) disponibile pubblicamente su Kaggle . È un nuovo punto di riferimento per la valutazione di algoritmi di apprendimento automatico nel rilevamento di anomalie in streaming, applicazioni online. Comprende oltre 50 file di dati di serie temporali artificiali e reali etichettati oltre a un nuovo meccanismo di punteggio progettato per applicazioni in tempo reale. Questo set di dati comprende anche una serie temporale di dati denominata “machine_temperature_system_failure” nel formato CSV. Comprende i dati del sensore di temperatura di un componente interno di una grande macchina industriale. Questo set di dati contiene anomalie tra cui l’arresto della macchina, guasti catastrofici della macchina ecc.
Implementazione di Anomaly Detection
Per implementare il nostro lavoro, prima di tutto, dobbiamo importare le librerie richieste. La libreria P andas è richiesta per le operazioni di frame di dati e la libreria NumPy per le operazioni di array. Per la stampa, stiamo importando librerie matplotlib e seaborn e per la preelaborazione dei dati, stiamo importando la libreria di preelaborazione . Per la rete neurale ricorrente LSTM, vengono importate le librerie Keras richieste . La libreria temporale viene utilizzata per visualizzare il tempo di compilazione del nostro modello LSTM RNN.
Importazione delle librerie richieste
import panda come pd
import numpy as np
import matplotlib
import seaborn
import matplotlib.dates as md
from matplotlib import pyplot as plt
from sklearn import preelaborazione
da keras.layers.core import Dense, Activation, Dropout
from keras.layers.recurrent importazione LSTM
da keras.models importare sequenziale
tempo import
Poiché questa implementazione è stata eseguita in Google Colab, utilizziamo lo snippet di codice seguente per leggere i dati dal sistema informatico locale.
Per caricare file dal sistema locale
da google.colab importare file
caricati = files.upload ()
carica il file in Google Colab

Una volta che il caricamento è mostrato al 100%, leggeremo il file di dati CSV che è i dati del sensore di temperatura nel formato delle serie temporali.
Lezione del file dal sistema locale
df = pd.read_csv (“ambient_temperature_system_failure.csv”)
Per verificare se i dati vengono letti correttamente, vediamo l’intestazione del file e quindi visualizziamo i dati tramite la stampa.
df.head ()
dati del sensore di temperatura
Visualizza i dati
figsize = (10,5)
df.plot (x = ‘timestamp’, y = ‘value’, figsize = figsize, title = ‘Temperature (Graden Farenhite)’);
plt.grid ();
plt.show ();
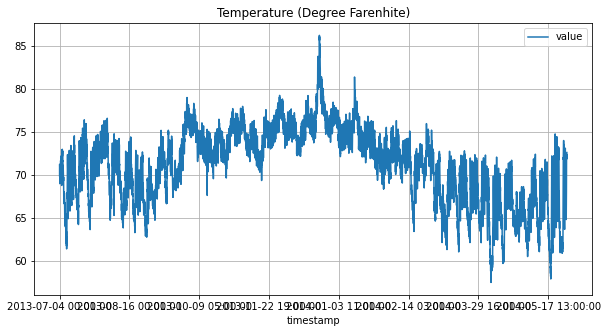
grafico dei dati del sensore di temperatura
Come possiamo vedere che le date non appaiono chiaramente sull’asse X, dobbiamo cambiare il tipo di colonna timestamp. Poiché la temperatura nel nostro set di dati è espressa in gradi Fahrenheit, la convertiremo in gradi Celcius.
Modifica del tipo di colonna timestamp per la visualizzazione
df [‘timestamp’] = pd.to_datetime (df [‘timestamp’])
df [‘value’] = (df [‘value’] – 32) * 5/9
df.plot (x = ‘timestamp’, y = ‘value’, figsize = figsize);
plt.title (‘Temperature (Degree Celcius)’, fontsize = 16);
plt.grid ();
plt.show ();
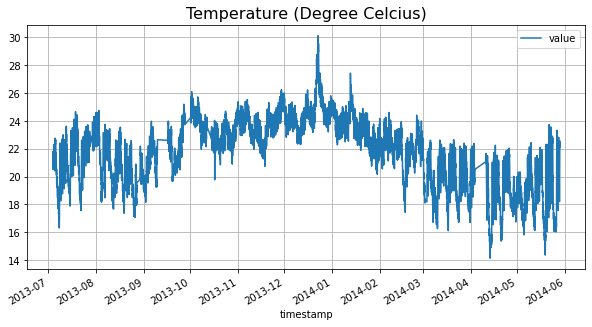
dati del sensore di temperatura
Ora possiamo vedere che i dati sono visualizzati perfettamente. Per verificare la stabilità della temperatura durante giorni e notti nei giorni feriali e nei fine settimana, elaboreremo di conseguenza i nostri dati. Innanzitutto, specificheremo ore, quindi giorni, quindi giorni feriali e notti. Infine, visualizzeremo la temperatura durante questi periodi di tempo usando un istogramma.
Formulazione dei dati nel formato richiesto
df [‘hours’] = df [‘timestamp’]. Dt.hour
df [‘daylight’] = ((df [‘hours’]> = 7) & (df [‘hours’ ] <= 22)). Astype (int)
df [‘DayOfTheWeek’] = df [‘timestamp’]. Dt.dayofweek
df [‘WeekDay’] = (df [‘DayOfTheWeek’] <5) .astype (int)
Anomalia popolazione stimata
outliers_fraction = 0,01
df [‘time_epoch’] = (df [‘timestamp’]. astype (np.int64) / 100000000000) .astype (np.int64)
df [‘categorie’] = df [‘WeekDay’] * 2 + df [‘daylight’]
a = df.loc [df [‘categorie’] == 0, ‘valore’]
b = df.loc [df [ ‘categorie’] == 1, ‘valore’]
c = df.loc [df [‘categorie’] == 2, ‘valore’]
d = df.loc [df [‘categorie’] == 3, ‘valore ‘]
Visualizzazione dei dati formattati
figsize = (10,5)
fig, ax = plt.subplots (figsize = figsize)
a_heights, a_bins = np.histogram (a)
b_heights, b_bins = np.histogram (b, bins = a_bins)
c_heights, c_bins = np.histogram (c, bins = a_bins)
d_heights, d_bins = np.histogram (d, bins = a_bins)
larghezza = (a_bins [1] – a_bins [0]) / 6
ax.bar (a_bins [: – 1], a_heights * 100 / a.count (), larghezza = larghezza, facecolor = ‘blu’, etichetta = ‘Weekend Night’)
ax.bar (b_bins [: – 1] + larghezza, (b_heights * 100 / b.count ()), larghezza = larghezza, facecolor = ‘verde’, etichetta = ‘Weekend Light’)
ax.bar (c_bins [: – 1] + larghezza * 2, (c_heights * 100 / c.count ()), larghezza = larghezza, facecolor = ‘rosso’, etichetta = ‘Weekday Night’)
ax.bar (d_bins [: – 1] + larghezza * 3, (d_heights * 100 / d.count ()), larghezza = larghezza, facecolor = ‘nero’, etichetta = ‘Weekday Light’)
plt.legend ()
plt.show ()
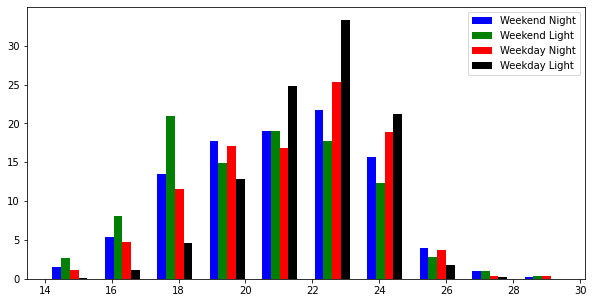
distribuzione della temperatura; rilevamento anomalie tramite LSTM
L’istogramma sopra mostra che la temperatura è relativamente più stabile durante i giorni della settimana alla luce del giorno. Ora, preelaboreremo il nostro set di dati per l’addestramento della rete neurale ricorrente LSTM. A tal fine, per prima cosa, prenderemo le colonne richieste dal set di dati e le ridimensioneremo usando lo Scaler standard.
Preparazione dei dati per il modello
LSTM data_n = df [[” valore ‘,’ ore ‘,’ luce del giorno ‘,’ DayOfTheWeek ‘,’ WeekDay ‘]]
min_max_scaler = preprocessing.StandardScaler ()
np_scaled = min_max_scaler.fit_transform (data_n)
data_ pd.DataFrame (np_scaled)
Nel passaggio successivo, definiremo e inizializzeremo i parametri richiesti e definiremo il set di dati di training e test. Impareremo da 50 valori precedenti e prevediamo attraverso il modello LSTM solo il valore successivo.
Parametri importanti e formazione / Dimensione test
prediction_time = 1
testdatasize = 1000
unroll_length = 50
testdatacut = testdatasize + unroll_length + 1
Training data
x_train = data_n [0: -prediction_time-testdatacut] .values
y_train = data_n [prediction_time: -testdatacut] [0] .values
Test data
x_test = data_n [0-testdatacut: -prediction_time] .values
y_test = data_n [prediction_time-testdatacut:] [0] .values
Come sappiamo che l’architettura di una rete neurale ricorrente ha uno stato nascosto. Lo stato nascosto al momento t è una funzione dello stato nascosto al tempo t − 1 e l’ingresso al tempo t . Questo stato nascosto al momento 0 è in genere inizializzato a. Il motivo fondamentale per cui gli RNN vengono srotolati è che tutti gli input e gli stati nascosti precedenti vengono utilizzati per calcolare i gradienti rispetto all’output finale dell’RNN. La seguente funzione di srotolamento creerà una sequenza di 50 punti dati precedenti per ciascuno dei punti di addestramento e test.
def unroll (data, sequence_length = 24):
result = []
per indice nell’intervallo (len (data) – sequence_length):
result.append (data [index: index + sequence_length])
return np.asarray (risultato)
Adatta i set di dati per la forma dei dati della sequenza
x_train = unroll (x_train, unroll_length)
x_test = unroll (x_test, unroll_length)
y_train = y_train [-x_train.shape [0]:]
y_test = y_test [-x_test.shape [0]: ]
Ora vedremo la forma finale dei nostri dati di allenamento e test.
Shape of data
print (“x_train”, x_train.shape)
print (“y_train”, y_train.shape)
print (“x_test”, x_test.shape)
print (“y_test”, y_test.shape)
forma del set di dati
Nel passaggio successivo, definiremo e aggiungeremo strati uno alla volta la rete neurale ricorrente LSTM. Per i dettagli di base sul modello LSTM RNN, puoi fare riferimento all’articolo ” Come codificare la tua prima rete LSTM in Keras “.
Costruzione del modello di
modello = Sequential ()
model.add (LSTM (input_dim = x_train.shape [-1], output_dim = 50, return_sequences = True))
model.add (Dropout (0.2))
model.add (LSTM (100, return_sequences = False))
model.add (Dropout (0.2))
model.add (Dense (units = 1))
model.add (Activation (‘linear’))
start = time.time () model.compile (
loss = ‘mse’, optimizer = ‘rmsprop’)
print (‘tempo di compilazione: {}’. format (time.time () – start))
Tempo di compilazione LSTM
Una volta definito e compilato correttamente il modello LSTM RNN, formeremo il nostro modello. I seguenti iperparametri possono essere regolati per verificare le prestazioni migliori.
model.fit (x_train, y_train, batch_size = 3028, nb_epoch = 50, validation_split = 0.1)
Formazione LSTM
Dopo l’addestramento riuscito del modello, visualizzeremo le prestazioni dell’allenamento.
Visualizzazione dell’allenamento e perdita di validaton
plt.figure (figsize = (10, 5))
plt.plot (model.history.history [‘loss’], label = ‘Loss’)
plt.plot (model.history.history [‘val_loss’], Label = ‘Val_Loss’)
plt.xlabel ( ‘epoche’)
plt.ylabel ( ‘perdita’)
plt.grid ()
plt.legend ()
Perdita di formazione e validazione LSTM
Ora eseguiremo lo snippet di codice seguente per comprendere meglio la differenza tra i dati originali e quelli previsti attraverso la visualizzazione.
creating dell’elenco delle differenze tra previsione e dati di test
loaded_model = model
diff = []
ratio = []
p = loaded_model.predict (x_test)
per te nell’intervallo (len (y_test)):
pr = p [u] [0]
ratio.append ((y_test [u] / pr) -1)
diff.append (abs (y_test [u] – pr))
Stampa della previsione e della realtà (per i dati del test)
plt.figure (figsize = (10, 5))
plt.plot (p, color = ‘red’, label = ‘Prediction’)
plt.plot (y_test, color = ‘blue’, label = ‘Test Data’)
plt.legend (loc = ‘in alto a sinistra’)
plt.grid ()
plt.legend ()
previsione per modello LSTM; rilevamento anomalie tramite LSTM
Ora, nel prossimo passo, troveremo le anomalie. I valori previsti più distanti sono considerati anomalie. Usando lo snippet di codice seguente, troveremo le anomalie nei dati.
Seleziona i punti di previsione / realtà più distanti come anomalie
diff = pd.Series (diff)
number_of_outliers = int (outliers_fraction * len (diff))
soglia = diff.nlargest (number_of_outliers) .min ()
Data con anomalia label
test = (diff> = soglia) .astype (int)
complement = pd.Series (0, index = np.arange (len (data_n) -testdatasize))
df [‘anomaly27’] = complement.append (test, ignore_index = ‘True ‘)
print (df [‘ anomaly27 ‘]. value_counts ())
Infine, visualizzeremo le anomalie utilizzando il codice seguente per la stampa.
Visualizzazione di anomalie (punti rossi)
plt.figure (figsize = (15,10))
a = df.loc [df [‘anomaly27’] == 1, [‘time_epoch’, ‘value’]] #anomaly
plt.plot (df [‘time_epoch’], df [‘value’], color = ‘blue’)
plt.scatter (a [‘time_epoch’], a [‘value’], color = ‘red’, label = ‘Anomaly’)
plt.axis ([1.370 * 1e7, 1.405 * 1e7, 15,30])
plt.grid ()
plt.legend ()
rilevamento anomalie tramite LSTM
Come possiamo vedere nella figura sopra, le anomalie sono visualizzate come punti rossi. Tutti i passaggi precedenti possono essere ripetuti più volte per visualizzare le anomalie sintonizzando gli iperparametri. Se troviamo la stessa visualizzazione alla fine, allora possiamo finire con queste anomalie.
Riferimenti: